" height="18.016311920580208px" id="GKXyVanMq" stroke-dasharray="0" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgb(0, 0, 0)" transform="translate(3 3)" width="18px"/></svg>)
"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient><linearGradient id="CBS1bzkxF-2031533640-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgb(255, 255, 255)"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient><linearGradient id="Jd7AK81w9-2031533640-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgb(255, 255, 255)"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient></defs><g d="M 0 16 L 0 0 L 16 0 L 16 16 Z M 9.167 5.167 C 9.167 4.891 8.943 4.667 8.667 4.667 C 8.391 4.667 8.167 4.891 8.167 5.167 C 8.167 6.784 7.809 7.834 7.155 8.488 C 6.501 9.143 5.451 9.5 3.833 9.5 C 3.557 9.5 3.333 9.724 3.333 10 C 3.333 10.276 3.557 10.5 3.833 10.5 C 5.451 10.5 6.501 10.857 7.155 11.512 C 7.809 12.166 8.167 13.216 8.167 14.833 C 8.167 15.109 8.391 15.333 8.667 15.333 C 8.943 15.333 9.167 15.109 9.167 14.833 C 9.167 13.216 9.524 12.166 10.178 11.512 C 10.832 10.857 11.883 10.5 13.5 10.5 C 13.776 10.5 14 10.276 14 10 C 14 9.724 13.776 9.5 13.5 9.5 C 11.883 9.5 10.832 9.143 10.178 8.488 C 9.524 7.834 9.167 6.784 9.167 5.167 Z M 4 3.667 C 4 3.483 3.851 3.333 3.667 3.333 C 3.483 3.333 3.333 3.483 3.333 3.667 C 3.333 4.32 3.189 4.715 2.952 4.952 C 2.715 5.189 2.32 5.333 1.667 5.333 C 1.483 5.333 1.333 5.483 1.333 5.667 C 1.333 5.851 1.483 6 1.667 6 C 2.32 6 2.715 6.145 2.952 6.382 C 3.189 6.618 3.333 7.013 3.333 7.667 C 3.333 7.851 3.483 8 3.667 8 C 3.851 8 4 7.851 4 7.667 C 4 7.013 4.145 6.618 4.382 6.382 C 4.618 6.145 5.013 6 5.667 6 C 5.851 6 6 5.851 6 5.667 C 6 5.483 5.851 5.333 5.667 5.333 C 5.013 5.333 4.618 5.189 4.382 4.952 C 4.145 4.715 4 4.32 4 3.667 Z M 7.333 1 C 7.333 0.816 7.184 0.667 7 0.667 C 6.816 0.667 6.667 0.816 6.667 1 C 6.667 1.422 6.573 1.65 6.445 1.778 C 6.317 1.906 6.089 2 5.667 2 C 5.483 2 5.333 2.149 5.333 2.333 C 5.333 2.517 5.483 2.667 5.667 2.667 C 6.089 2.667 6.317 2.761 6.445 2.889 C 6.573 3.016 6.667 3.244 6.667 3.667 C 6.667 3.851 6.816 4 7 4 C 7.184 4 7.333 3.851 7.333 3.667 C 7.333 3.244 7.427 3.016 7.555 2.889 C 7.683 2.761 7.911 2.667 8.333 2.667 C 8.517 2.667 8.667 2.517 8.667 2.333 C 8.667 2.149 8.517 2 8.333 2 C 7.911 2 7.683 1.906 7.555 1.778 C 7.427 1.65 7.333 1.422 7.333 1 Z" fill="transparent" height="16px" id="aoZYv33vR" width="16px"><path d="M 0 16 L 0 0 L 16 0 L 16 16 Z" fill="transparent" height="16px" id="Z2uGmhW9f" width="16px"/><g d="M 7.833 4.5 C 7.833 4.224 7.609 4 7.333 4 C 7.057 4 6.833 4.224 6.833 4.5 C 6.833 6.117 6.476 7.168 5.822 7.822 C 5.168 8.476 4.117 8.833 2.5 8.833 C 2.224 8.833 2 9.057 2 9.333 C 2 9.61 2.224 9.833 2.5 9.833 C 4.117 9.833 5.168 10.191 5.822 10.845 C 6.476 11.499 6.833 12.549 6.833 14.167 C 6.833 14.443 7.057 14.667 7.333 14.667 C 7.609 14.667 7.833 14.443 7.833 14.167 C 7.833 12.549 8.191 11.499 8.845 10.845 C 9.499 10.191 10.549 9.833 12.167 9.833 C 12.443 9.833 12.667 9.61 12.667 9.333 C 12.667 9.057 12.443 8.833 12.167 8.833 C 10.549 8.833 9.499 8.476 8.845 7.822 C 8.191 7.168 7.833 6.117 7.833 4.5 Z M 2.667 3 C 2.667 2.816 2.517 2.667 2.333 2.667 C 2.149 2.667 2 2.816 2 3 C 2 3.654 1.855 4.048 1.618 4.285 C 1.382 4.522 0.987 4.667 0.333 4.667 C 0.149 4.667 0 4.816 0 5 C 0 5.184 0.149 5.333 0.333 5.333 C 0.987 5.333 1.382 5.478 1.618 5.715 C 1.855 5.952 2 6.346 2 7 C 2 7.184 2.149 7.333 2.333 7.333 C 2.517 7.333 2.667 7.184 2.667 7 C 2.667 6.346 2.811 5.952 3.048 5.715 C 3.285 5.478 3.68 5.333 4.333 5.333 C 4.517 5.333 4.667 5.184 4.667 5 C 4.667 4.816 4.517 4.667 4.333 4.667 C 3.68 4.667 3.285 4.522 3.048 4.285 C 2.811 4.048 2.667 3.654 2.667 3 Z M 6 0.333 C 6 0.149 5.851 0 5.667 0 C 5.483 0 5.333 0.149 5.333 0.333 C 5.333 0.756 5.239 0.984 5.112 1.112 C 4.984 1.239 4.756 1.333 4.333 1.333 C 4.149 1.333 4 1.483 4 1.667 C 4 1.851 4.149 2 4.333 2 C 4.756 2 4.984 2.094 5.112 2.222 C 5.239 2.35 5.333 2.578 5.333 3 C 5.333 3.184 5.483 3.333 5.667 3.333 C 5.851 3.333 6 3.184 6 3 C 6 2.578 6.094 2.35 6.222 2.222 C 6.35 2.094 6.578 2 7 2 C 7.184 2 7.333 1.851 7.333 1.667 C 7.333 1.483 7.184 1.333 7 1.333 C 6.578 1.333 6.35 1.239 6.222 1.112 C 6.094 0.984 6 0.756 6 0.333 Z" fill="transparent" height="14.66671286102295px" id="ae6ccdFme" transform="translate(1.333 0.667)" width="12.66663px"><path d="M 5.833 0.5 C 5.833 0.224 5.609 0 5.333 0 C 5.057 0 4.833 0.224 4.833 0.5 C 4.833 2.117 4.476 3.168 3.822 3.822 C 3.168 4.476 2.117 4.833 0.5 4.833 C 0.224 4.833 0 5.057 0 5.333 C 0 5.61 0.224 5.833 0.5 5.833 C 2.117 5.833 3.168 6.191 3.822 6.845 C 4.476 7.499 4.833 8.549 4.833 10.167 C 4.833 10.443 5.057 10.667 5.333 10.667 C 5.609 10.667 5.833 10.443 5.833 10.167 C 5.833 8.549 6.191 7.499 6.845 6.845 C 7.499 6.191 8.549 5.833 10.167 5.833 C 10.443 5.833 10.667 5.61 10.667 5.333 C 10.667 5.057 10.443 4.833 10.167 4.833 C 8.549 4.833 7.499 4.476 6.845 3.822 C 6.191 3.168 5.833 2.117 5.833 0.5 Z" fill="url(%23t2lXByE48-2031533640-linear-gradient)" height="10.66671px" id="t2lXByE48" transform="translate(2 4)" width="10.66663px"/><path d="M 2.667 0.333 C 2.667 0.149 2.517 0 2.333 0 C 2.149 0 2 0.149 2 0.333 C 2 0.987 1.855 1.382 1.618 1.618 C 1.382 1.855 0.987 2 0.333 2 C 0.149 2 0 2.149 0 2.333 C 0 2.517 0.149 2.667 0.333 2.667 C 0.987 2.667 1.382 2.811 1.618 3.048 C 1.855 3.285 2 3.68 2 4.333 C 2 4.517 2.149 4.667 2.333 4.667 C 2.517 4.667 2.667 4.517 2.667 4.333 C 2.667 3.68 2.811 3.285 3.048 3.048 C 3.285 2.811 3.68 2.667 4.333 2.667 C 4.517 2.667 4.667 2.517 4.667 2.333 C 4.667 2.149 4.517 2 4.333 2 C 3.68 2 3.285 1.855 3.048 1.618 C 2.811 1.382 2.667 0.987 2.667 0.333 Z" fill="url(%23CBS1bzkxF-2031533640-linear-gradient)" height="4.66667px" id="CBS1bzkxF" transform="translate(0 2.667)" width="4.66667px"/><path d="M 2 0.333 C 2 0.149 1.851 0 1.667 0 C 1.483 0 1.333 0.149 1.333 0.333 C 1.333 0.756 1.239 0.984 1.112 1.112 C 0.984 1.239 0.756 1.333 0.333 1.333 C 0.149 1.333 0 1.483 0 1.667 C 0 1.851 0.149 2 0.333 2 C 0.756 2 0.984 2.094 1.112 2.222 C 1.239 2.35 1.333 2.578 1.333 3 C 1.333 3.184 1.483 3.333 1.667 3.333 C 1.851 3.333 2 3.184 2 3 C 2 2.578 2.094 2.35 2.222 2.222 C 2.35 2.094 2.578 2 3 2 C 3.184 2 3.333 1.851 3.333 1.667 C 3.333 1.483 3.184 1.333 3 1.333 C 2.578 1.333 2.35 1.239 2.222 1.112 C 2.094 0.984 2 0.756 2 0.333 Z" fill="url(%23Jd7AK81w9-2031533640-linear-gradient)" height="3.333333px" id="Jd7AK81w9" transform="translate(4 0)" width="3.3333399999999997px"/></g></g></svg>)
" height="24px" id="WCm44spAV" width="24px"/><path d="M 3.892 7.742 C 1.674 7.742 0 6.014 0 3.882 C 0 1.738 1.589 0 3.892 0 C 5.107 0 5.951 0.374 6.623 1.173 L 5.566 2.09 C 5.118 1.621 4.564 1.386 3.892 1.386 C 2.452 1.386 1.547 2.517 1.547 3.882 C 1.547 5.246 2.452 6.356 3.924 6.356 C 4.649 6.356 5.193 6.111 5.63 5.63 L 6.718 6.558 C 6.153 7.24 5.193 7.742 3.892 7.742 Z" fill="rgb(255, 255, 255)" height="7.741500000000002px" id="XEPpGD7l5" transform="translate(4 8.25)" width="6.717999999999989px"/><path d="M 2.74 7.922 C 1.215 7.922 0 6.632 0 5.032 C 0 3.433 1.215 2.122 2.74 2.122 C 3.7 2.122 4.201 2.516 4.5 3.113 L 4.5 2.239 L 5.928 2.239 L 5.928 7.784 L 4.531 7.784 L 4.531 6.877 C 4.233 7.507 3.731 7.922 2.74 7.922 Z M 1.439 5.023 C 1.439 5.865 2.057 6.622 2.975 6.622 C 3.924 6.622 4.531 5.897 4.531 5.033 C 4.531 4.169 3.924 3.423 2.975 3.423 C 2.057 3.423 1.439 4.159 1.439 5.022 Z M 6.784 7.784 L 6.784 0 L 8.224 0 L 8.224 7.784 L 6.784 7.784 Z" fill="rgb(255, 255, 255)" height="7.9224997406005855px" id="lGDJupIUR" transform="translate(10.5 8)" width="8.223500194549558px"/></g></svg>)
" width="18px"><path d="M 2 8 C 0.895 8 0 7.105 0 6 L 0 2 C 0 0.895 0.895 0 2 0 L 6 0 C 7.105 0 8 0.895 8 2 L 8 6 C 8 7.105 7.105 8 6 8 Z" fill="transparent" height="8px" id="ZrCrI93dV" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" width="8px"/><path d="M 0 0 L 0 4 C 0 5.105 0.895 6 2 6 L 6 6" fill="transparent" height="6px" id="emltWYAiE" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" transform="translate(4 8)" width="6px"/><path d="M 2 8 C 0.895 8 0 7.105 0 6 L 0 2 C 0 0.895 0.895 0 2 0 L 6 0 C 7.105 0 8 0.895 8 2 L 8 6 C 8 7.105 7.105 8 6 8 Z" fill="transparent" height="8px" id="WpBecYDfi" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" transform="translate(10 10)" width="8px"/></g></svg>)

Ingenieurwesen im Jahr 2026 und darüber hinaus
Wir bauen Infrastrukturen, die fast nie ausfallen dürfen. Um dies zu erreichen, arbeiten wir schnell und liefern qualitativ hochwertige Software ohne Abkürzungen oder Kompromisse. Dieses Dokument beschreibt die ingenieurtechnischen Standards, die uns bis 2026 und darüber hinaus leiten werden.

Teamstruktur
Unsere Ingenieurorganisation besteht aus fünf Kernteams, die jeweils unterschiedliche Verantwortungsbereiche haben:
Foundation Team: Konzentriert sich auf die Herstellung und Einhaltung von Codierungsstandards und architektonischen Mustern. Dieses Team arbeitet eng mit anderen Teams zusammen, um Best Practices in der gesamten Organisation zu etablieren.
Consumer-, Enterprise- und Plattform-Teams: Produktorientierte Teams, die schnell Funktionen bereitstellen und gleichzeitig die in diesem Dokument festgelegten Qualitätsstandards einhalten. Diese Teams beweisen, dass Geschwindigkeit und Qualität sich nicht gegenseitig ausschließen.
Community-Team: Zuständig für die schnelle Überprüfung von PRs aus der Open-Source-Community, Bereitstellung von Feedback und Unterstützung dieser Arbeit bis zur Zusammenführung. Dieses Team sorgt dafür, dass unsere Open-Source-Beitragenden ein großartiges Erlebnis haben und ihre Beiträge unseren Qualitätsstandards entsprechen.
Unsere Ergebnisse bisher
Die Daten sprechen für sich. Im letzten Jahr und einem halben Jahr haben wir grundlegend verändert, wie wir Software entwickeln:
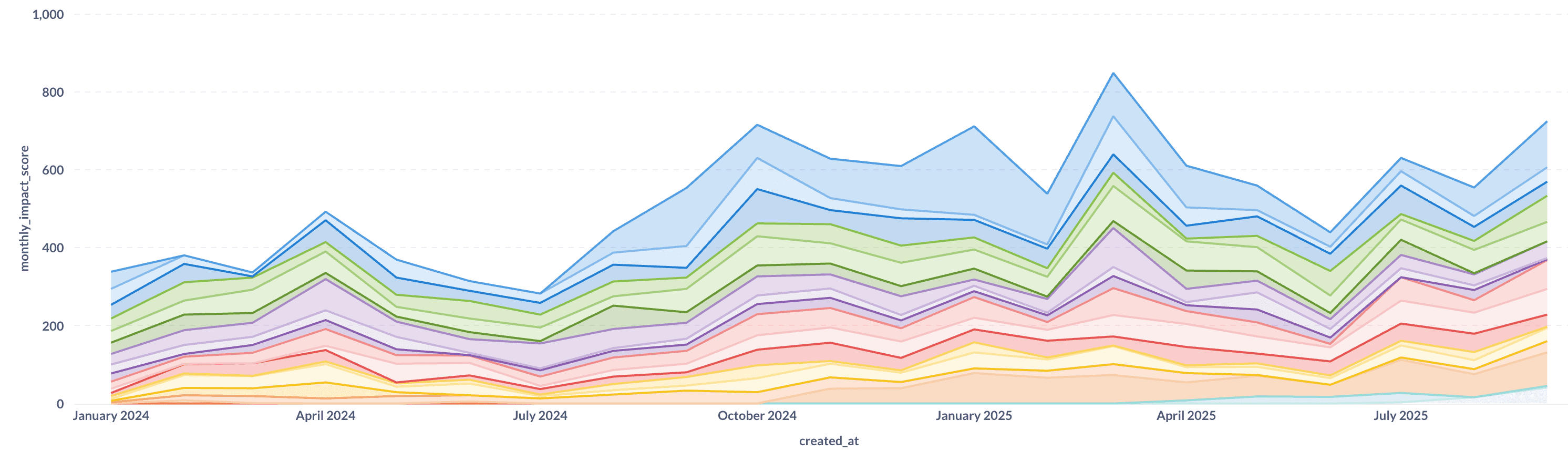
Wir haben unsere Engineering-Leistung ungefähr verdoppelt, während wir gleichzeitig die Qualität verbessert haben. Noch beeindruckender ist der Wandel, was wir entwickeln:
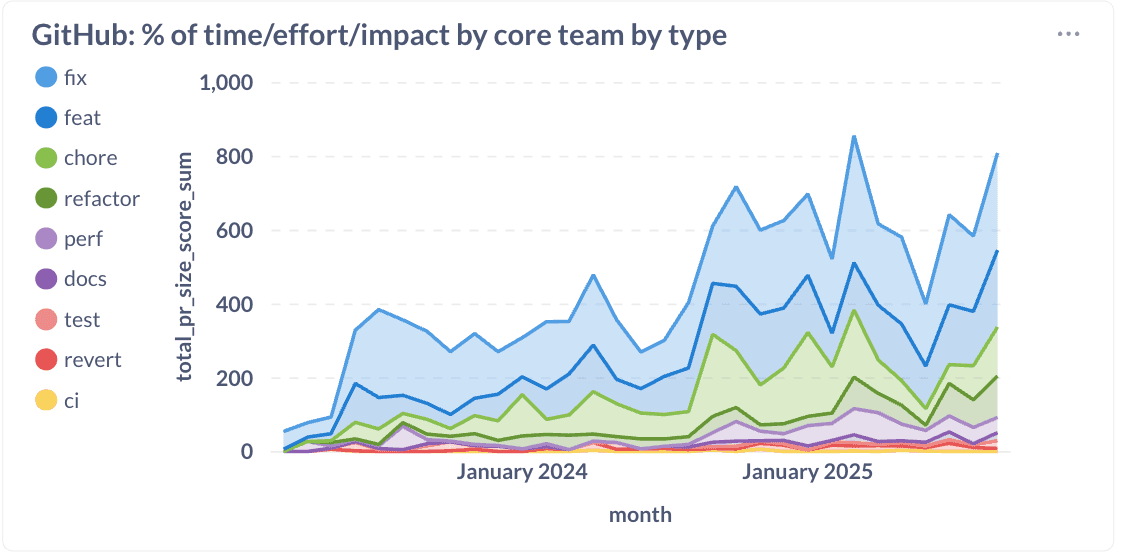
Wir haben erfolgreich etwa 20% des Engineeringsaufwands von Korrekturen umgeleitet hin zu Features, Leistungsverbesserungen, Refaktorierungen und Aufgaben. Diese Verschiebung zeigt, dass Investitionen in Qualität und Architektur einen nicht verlangsamen. Sie beschleunigen einen.
Cal.com's Grundlage ermöglicht Exzellenz für coss.com
Cal.com ist ein stabiles, profitables Unternehmen, das wir weiter ausbauen werden.
Dieser Erfolg verschafft uns einen einzigartigen Vorteil beim Aufbau von coss.com. Anders als in den frühen Tagen von Cal.com, als wir schnell handeln mussten, um die Produkt-Markt-Passung zu erreichen und ein nachhaltiges Geschäft aufzubauen, startet coss.com aus einer Position der Stärke.
Wir müssen uns bei coss.com nicht beeilen.
Die Stabilität von Cal.com bedeutet, dass wir uns leisten können, coss.com von Anfang an richtig aufzubauen. Wir haben den Luxus, diese technischen Standards umzusetzen, ohne den Druck von sofortigen Marktanforderungen oder Finanzierungsbeschränkungen. Dies ist eine grundlegend andere Ausgangsposition.
Die "Langsamkeit" ist eine Investition, keine Kosten.
Ja, die Einhaltung dieser Standards mag sich anfangs langsamer anfühlen und für einige Ingenieure sogar frustrierend sein. Das Schreiben von DTOs dauert länger, als Datenbanktypen direkt an das Frontend zu übergeben. Die Erstellung ordnungsgemäßer Abstraktionen und der Einsatz von Abhängigkeitsinjektion erfordert mehr Vorabgestaltung. Eine Testabdeckung von über 80% für neuen Code aufrechtzuerhalten, erfordert Disziplin. Aber diese scheinbare Langsamkeit ist vorübergehend, und die Belohnung ist exponentiell.
Betrachten Sie die verzinslichen Renditen...
Richtig von Anfang an architekturierter Code benötigt später keine umfangreichen Refaktorierungen mehr
Hohe Testabdeckung verhindert Fehler, die sonst Wochen voller Debugging und Hotfixes erfordern würden (siehe 2023 bis Mitte 2024)
Richtige Abstraktionen machen das Hinzufügen neuer Funktionen im Laufe der Zeit erheblich schneller
Klar definierte Grenzen und DTOs verhindern die architektonische Erosion, die schließlich vollständige Neuschreibungen erfordert
Der Cal.com-Verlauf zeigt, was passiert, wenn man für unmittelbare Geschwindigkeit optimiert. Hohe Anfangsgeschwindigkeit, die allmählich abnimmt, wenn technologische Schulden sich anhäufen, architektonische Abkürzungen Engpässe schaffen und mehr Zeit mit der Behebung von Problemen verbracht wird, als Funktionen zu entwickeln (siehe früheres Diagramm, in dem wir 55-60% des Engineeringsaufwands für Korrekturen aufgewendet haben).
Der Trajektorie von coss.com wird die Kraft des korrekten Bauens von Anfang an nutzen. Etwas langsamer initiale Geschwindigkeit beim Festlegen ordnungsgemäßer Muster, gefolgt von exponentieller Beschleunigung, während diese Muster Dividenden zahlen und schnellere Entwicklungen mit höherem Vertrauen ermöglichen.
Kernprinzipien
1. Keine aufgeschobene Qualität
Wir werden "Ich mache es in einem nachfolgenden PR" bei kleinen Refaktorierungen minimieren.
Nicht abgeschlossene PRs für kleinere Verbesserungen finden selten statt. Stattdessen akkumulieren sie sich als technische Schuld, die uns Monate oder Jahre später belastet. Wenn eine kleine Refaktorierung jetzt gemacht werden kann, dann machen Sie sie jetzt. Nachfolgende PRs sollten für wesentliche Änderungen vorbehalten sein, die wirklich separate PRs oder außergewöhnliche, dringende Fälle rechtfertigen.
2. Hohe Standards in Code-Review
Lassen Sie keine PRs mit vielen Anmerkungen durch, nur um nicht der "böse Mensch" zu sein.
Genau so werden Codebasen im Laufe der Zeit schlampig. Code-Review hat nicht damit zu tun, nett zu sein. Es geht darum, die Qualitätsstandards aufrechtzuerhalten, die unsere Infrastruktur erfordert. Jede Anmerkung zählt. Jede Musterverletzung zählt. Adressieren Sie sie vor dem Merging, nicht danach.
3. Treibt euch gegenseitig dazu an, das Richtige zu tun
Wir halten uns gegenseitig für die Qualität verantwortlich
Ecken abzuschnipsen, mag sich im Moment schneller anfühlen, aber es schafft Probleme, die später alle verlangsamen. Wenn Sie sehen, dass ein Teamkollege dabei ist, einen PR mit offensichtlichen Problemen zu mergen, sprechen Sie es an. Wenn jemand einen schnellen Hack anstelle der richtigen Lösung vorschlägt, wehren Sie sich. Wenn Sie versucht sind, Tests zu überspringen oder architektonische Muster zu ignorieren, erwarten Sie, dass Ihre Teamkollegen Sie herausfordern.
Es geht nicht darum, schwierig zu sein oder Leute zu verlangsamen
Es geht um die kollektive Eigentümerschaft unserer Codebasis und unseres Rufs. Jede Abkürzung, die eine Person nimmt, wird zum Problem aller. Jede heute geschnittene Ecke bedeutet mehr Debugging-Sitzungen, mehr Hotfixes und mehr frustrierte Kunden morgen.
Machen Sie es normal, schlechte Entscheidungen respektvoll herauszufordern
Wenn jemand sagt: "Lass uns das jetzt einfach hart codieren", sollte die erwartete Antwort sein: "Was würde es kosten, es das erste Mal richtig zu machen?" Wenn jemand ungetesteten Code einfügen möchte, sollte das Team zurückdrängen. Wenn jemand vorschlägt, zu kopieren und einzufügen, anstatt eine ordentliche Abstraktion zu schaffen, sprechen Sie es respektvoll an.
Wir bauen etwas, das fast niemals scheitern sollte
Dieses Maß an Zuverlässigkeit passiert nicht zufällig. Es passiert, wenn jeder Ingenieur sich für die Qualität verantwortlich fühlt, nicht nur für seinen eigenen Code, sondern für das gesamte System. Wir gewinnen als Team oder wir scheitern als Team.
4. Streben Sie nach Einfachheit
Priorisieren Sie Klarheit über Cleverness
Das Ziel ist Code, der leicht zu lesen und schnell zu verstehen ist, nicht elegante Komplexität. Einfache Systeme reduzieren die kognitive Last für jeden Ingenieur.
Stellen Sie sich die richtigen Fragen
Löse ich tatsächlich das aktuelle Problem?
Denke ich zu viel über mögliche zukünftige Anwendungsfälle nach?
Habe ich mindestens eine andere Alternative zur Lösung dieses Problems in Betracht gezogen? Wie vergleicht sie sich?
Einfach bedeutet nicht mangelhaft an Funktionen
Nur weil unser Ziel es ist, einfache Systeme zu schaffen, bedeutet dies nicht, dass sie dürftig und ohne offensichtliche Funktionalität sein sollten.
5. Automatisiere alles
Nutze KI
Generiere 80% des Boilerplates und nicht-kritischen Codes mit KI, damit wir uns ausschließlich auf komplexe Geschäftslogik und kritische Architekturen konzentrieren können.
Erstellen Sie geräuschfreie Alarme und intelligente Fehlerbehandlung.
Manuelles Testen gehört mehr und mehr der Vergangenheit an. KI kann schnell und intelligent Mega-Test-Suites für uns erstellen.
Unser CI ist der Endgegner
Alles in diesem standardisierten Dokument wird überprüft, bevor Code in PRs zusammengeführt wird
Keine Überraschungen gelangen in das Haupt-Repository
Prüfungen sind schnell und nützlich
Architekturstil
Wir wechseln zu einem strikten Architekturmodell basierend auf Vertical Slice Architecture und Domain-Driven Design (DDD). Die folgenden Muster und Prinzipien werden in PR-Reviews rigoros durchgesetzt und durch Linting unterstützt.
Vertical Slice Architecture: Pakete/Funktionen
Unsere Codebasis ist nach Domäne organisiert, nicht nach technischer Schicht. Das packages/features-Verzeichnis ist das Herzstück dieses architektonischen Ansatzes. Jedes darin befindliche Verzeichnis stellt einen vollständigen vertikalen Ausschnitt der Anwendung dar, angetrieben durch die betroffene Domäne.
Struktur:
Jeder Funktionsordner ist ein autarker vertikaler Ausschnitt, der alles enthält, was für diese Domäne benötigt wird:
Domänenlogik: Die zentralen Geschäftsregeln und Entitäten spezifisch für diese Funktion
Anwendungsdienste: Anwendungsfallorchestration für diese Domäne
Repositories: Datenzugriff, spezifisch für die Anforderungen dieser Funktion
DTOs: Datenübertragungsobjekte zum Überschreiten von Grenzen
UI-Komponenten: Frontend-Komponenten, die sich auf diese Funktion beziehen (falls zutreffend)
Tests: Unit-, Integrations- und End-to-End-Tests für diese Funktion
Warum vertikale Ausschnitte wichtig sind
Traditionelle geschichtete Architektur ist nach technischen Belangen organisiert:
Das schafft mehrere Probleme:
Änderungen an einer Funktion erfordern das Bearbeiten von Dateien, die über mehrere Verzeichnisse verstreut sind
Es ist schwierig zu verstehen, was eine Funktion tut, da ihr Code fragmentiert ist
Teams treten sich gegenseitig auf die Füße, wenn sie an verschiedenen Funktionen arbeiten
Sie können eine Funktion nicht leicht extrahieren oder veraltet machen
Vertikale Ausschnittarchitektur ist nach Domäne organisiert:
Das löst diese Probleme:
Alles, was mit Verfügbarkeit zu tun hat, befindet sich in
packages/features/availabilitySie können die gesamte Verfügbarkeitsfunktion verstehen, indem Sie ein Verzeichnis erkunden
Teams können an verschiedenen Funktionen arbeiten, ohne Konflikte zu haben (wenn das Cal.com-Ingenieursteam wächst, aber definitiv bei coss.com werden wir Teams haben, die sich um wichtige Pakete kümmern)
Funktionen sind lose gekoppelt und können unabhängig voneinander entwickelt werden
Richtlinien für die Funktionale Organisation
Theoretisch ist jede Funktion unabhängig einsetzbar. Obwohl wir sie möglicherweise nicht tatsächlich separat bereitstellen, erzwingt diese Organisation, dass wir Abhängigkeiten klar halten und die Kopplung minimal bleibt. Dies ist die Prämisse und der Erfolg von Microservices, obwohl wir noch keine Microservices bereitstellen werden.
Funktionen kommunizieren über gut définierte Schnittstellen. Wenn Buchungen Verfügbarkeitsdaten benötigt, importiert es von @calcom/features/availability über exportierte Schnittstellen und greift nicht auf interne Implementierungsdetails zu.
Gemeinsamer Code lebt an geeigneten Orten:
Domänenagnostische Dienstprogramme und bereichsübergreifende Bedenken (Authentifizierung, Protokollierung):
packages/libGemeinsame UI-Grundlagen:
packages/ui(und bald auch coss.com ui)
Domänengrenzen werden automatisch durchgesetzt. Wir werden Linting erstellen, das verhindert, in die internen Funktionen vorzudringen, wo es nicht erlaubt ist. Wenn packages/features/bookings versucht, von packages/features/availability/services/internal zu importieren, blockiert der Linter es. Alle bereichsübergreifenden Abhängigkeiten müssen über die öffentliche API der Funktion gehen.
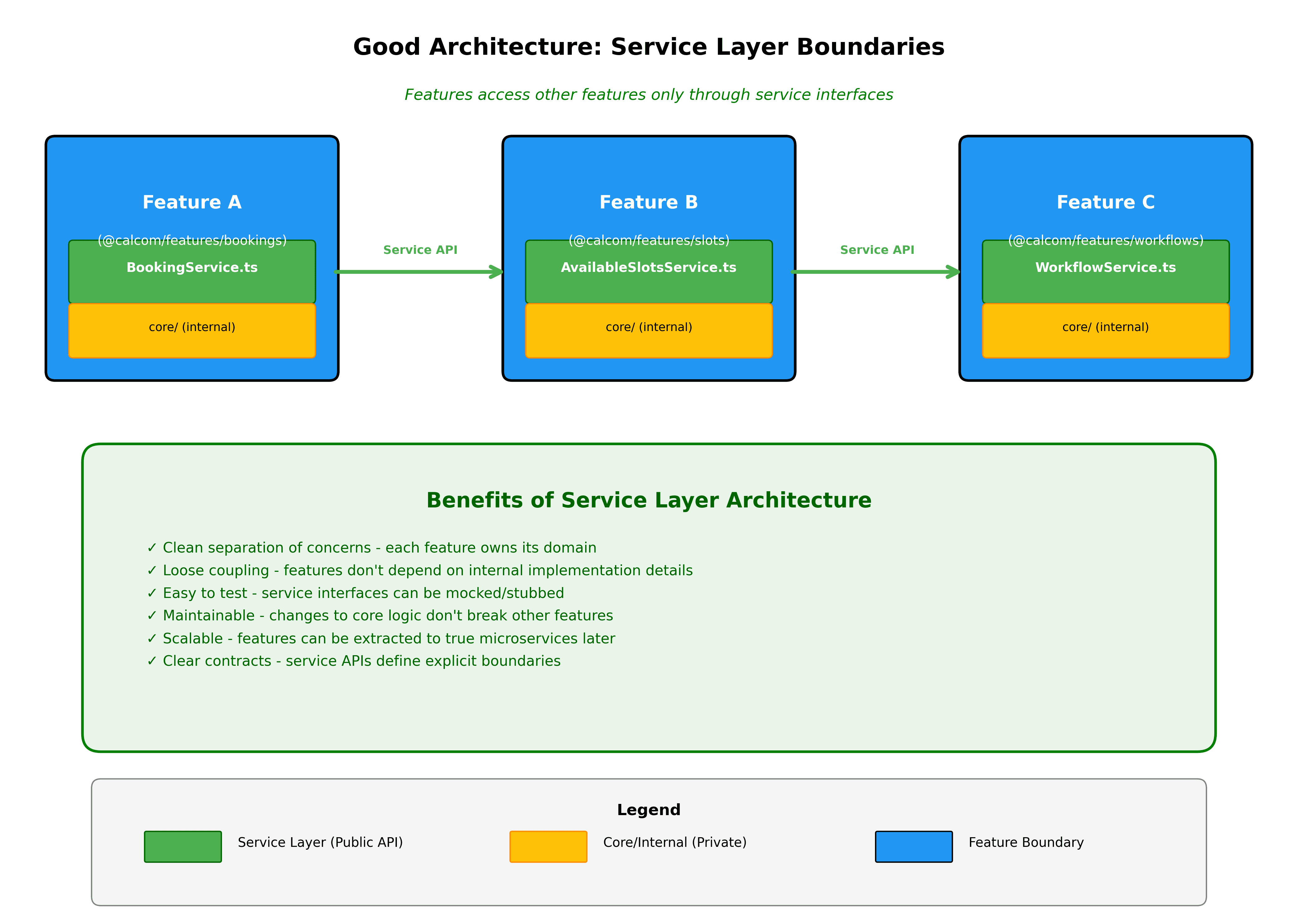
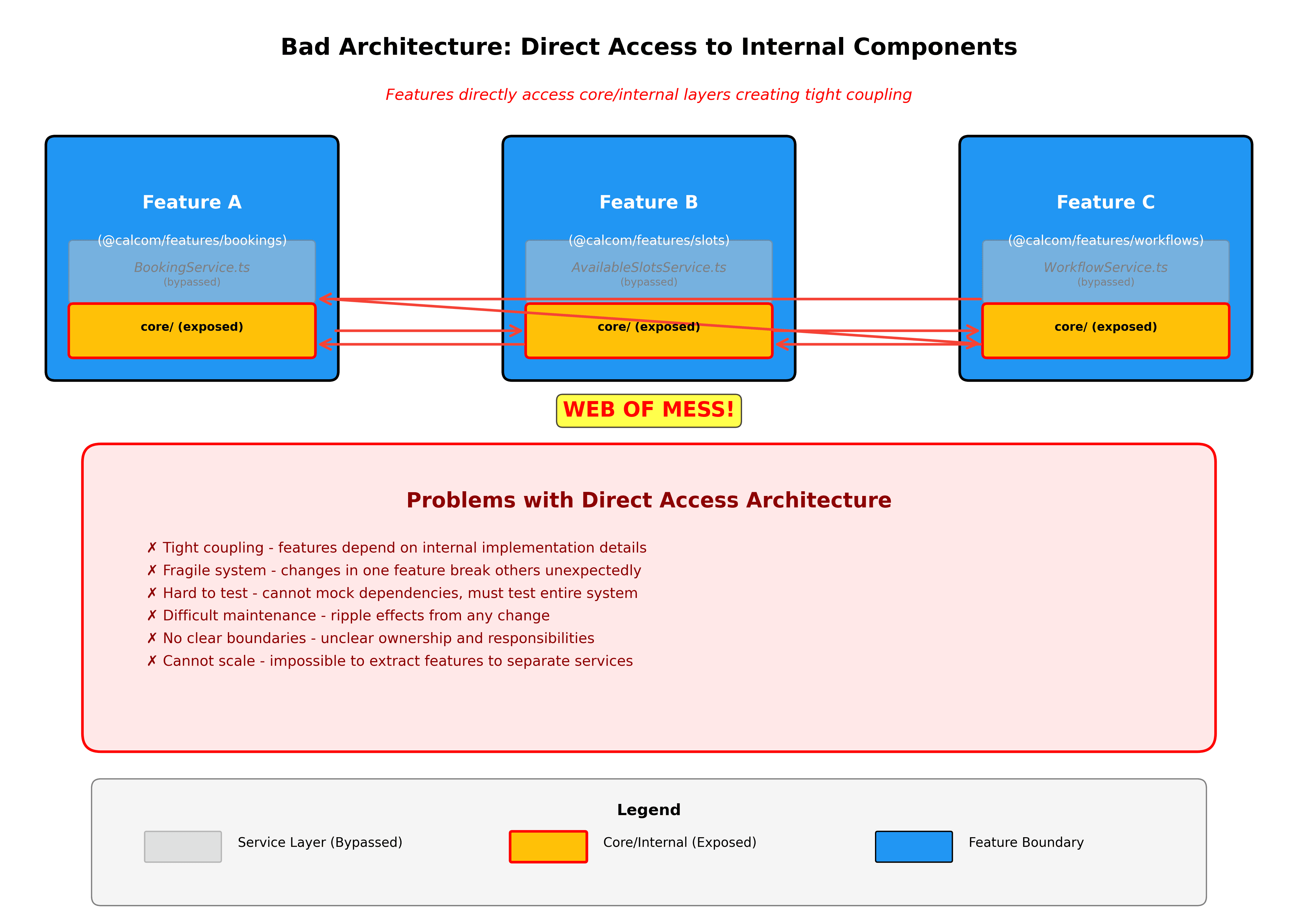
Neue Funktionen beginnen als vertikale Ausschnitte. Beim Erstellen von etwas Neuem, erstellen Sie einen neuen Ordner in packages/features mit dem kompletten vertikalen Ausschnitt. Dies macht klar, was Sie bauen und hält alles von Tag eins organisiert.
Vorteile
Auffindbarkeit
Suchen Sie die Buchungslogik? Sie befindet sich alles in
packages/features/bookings. Keine Notwendigkeit, durch Controller, Dienste, Repositories und verstreute Hilfsprogramme im Code zu jagen.
Einfacheres Testen
Testen Sie die gesamte Funktion als eine Einheit. Sie haben alle Teile an einem Ort, was integration tests natürlich und unkompliziert macht.
Klarere Abhängigkeiten
Wenn Sie sehen
import { getAvailability } from '@calcom/features/availability', wissen Sie genau, von welcher Funktion Sie abhängen. Wenn die Abhängigkeiten zu komplex werden, ist es offensichtlich und kann angegangen werden.
Repository-Muster und Abhängigkeitsinjektion
Technologieentscheidungen dürfen sich nicht durch die Anwendung ausbreiten. Das Prisma-Problem illustriert dies perfekt. Derzeit haben wir Referenzen zu Prisma, die über hunderte von Dateien verstreut sind. Dies schafft massive Kopplung und macht Technologieänderungen unhaltbar teuer. Wir erleben jetzt die Schmerzen beim Upgrade von Prisma auf v6.16. Etwas, das nur eine lokalisierte Refaktorierung hinter abgeschirmten Repositories hätte sein sollen, war eine langwierige, nahezu endlose Verfolgung von Problemen über mehrere Apps hinweg.
Der Standard von jetzt an:
Alle Datenbankzugriffe müssen über Repository-Klassen erfolgen. Wir haben bereits einen guten Vorsprung dabei.
Repositories sind der einzige Code, der von Prisma (oder einem anderen ORM) weiß. Es sollte keine Logik in ihnen sein.
Repositories werden über Abhängigkeitsinjektion-Container injiziert
Wenn wir jemals von Prisma zu Drizzle oder einem anderen ORM wechseln, sind die einzigen Änderungen erforderlich:
Repository-Implementierungen
DI-Container-Verkabelung für neue Repositories
Nichts anderes im Code-Base sollte sich kümmern oder ändern
Das ist keine Theorie. So bauen wir wartungsfreundliche Systeme auf.
Datenübertragungsobjekte (DTOs)
Datenbanktypen sollten nicht an das Frontend durchdringen. Dies ist zu einer beliebten Abkürzung in unserem Tech-Stack geworden, aber es ist ein Codesmell, das mehrere Probleme schafft.
Technologische Koppelung (Prisma-Typen enden in React-Komponenten)
Sicherheitsrisiken (versehentliche Weitergabe sensibler Felder)
Zerbrechliche Verträge zwischen Server und Client (dies ist besonders problematisch, da wir viele weitere APIs entwickeln)
Unfähigkeit, das Datenbankschema unabhängig zu entwickeln
Alle DTO-Konvertierungen durch Zod, sogar für eine API-Antwort, um sicherzustellen, dass alle Daten vor dem Senden an den Benutzer validiert werden. Besser, um zu scheitern, als etwas falsch zurückzugeben.
Der Standard von jetzt an:
Erstellen Sie explizite DTOs bei jeder architektonischen Grenze.
Datenebene → Anwendungsebene → API: Transformieren Sie Datenbankmodelle in Anwendungs-DTOs und dann Anwendungs-DTOs in API-spezifische DTOs
API → Anwendungsebene → Datenebene: Transformieren Sie die API-DTOs durch die Anwendungsebene und in daten-spezifische DTOs
Ja, das erfordert mehr Code. Ja, es lohnt sich. Explizite Grenzen verhindern die architektonische Erosion, die langfristige Wartungsalbträume erzeugt.
Domain-Driven Design Patterns
Die folgenden Muster müssen korrekt und konsequent verwendet werden:
Anwendungsdienste
Orchestrierung von Anwendungsfällen, Koordination zwischen Domänendiensten und Repositories
Domänendienste
Enthalten Geschäftlogik, die nicht natürlich zu einer einzigen Entität gehört
Repositories
Abstrahieren von Datenzugang, Isolierung von Technologieentscheidungen
Abhängigkeitsinjektion
Ermöglichen von loser Koppelung, Erleichterung von Tests, Isolierung von Anliegen
Caching-Proxies
Umschließen Repositories oder Dienste, um Caching-Verhalten transparent hinzuzufügen
Nicht der einzige Weg, Caching zu betreiben, aber ein schöner Ausgangspunkt
Dekoratoren
Fügen Querschnittsbelange (Protokollierung, Metriken usw.) ohne Verschmutzung der Domänenlogik hinzu
Konsistenz der Codebasis
Unsere Codebasen sollten sich anfühlen, als hätte eine Person sie geschrieben. Dieses Maß an Konsistenz erfordert strikte Einhaltung der etablierten Muster, umfassende Linting-Regeln, die architektonische Standards durchsetzen, Code-Reviews, die Musterverletzungen ablehnen + die Unterstützung von KI-Code-Rezensenten.
Verlagern Sie Bedingungsanweisungen an den Anwendungseingangspunkt
Wenn-Anweisungen gehören an den Eingabepunkt und nicht in Ihren Diensten verstreut. Dies ist ein von den wichtigsten Architekturprinzipien für die Aufrechterhaltung von sauberem, fokussiertem Code, der sich nicht in unüberschaubare Komplexität auswächst.
So wird Code im Laufe der Zeit schlechter: Ein Dienst wird für einen klaren, spezifischen Zweck geschrieben. Die Logik ist sauber und fokussiert. Dann kommt eine neue Produkterforderung, und jemand fügt eine if-Anweisung hinzu. Einige Jahre und mehrere weitere Anforderungen später ist dieser Dienst mit bedingten Überprüfungen für verschiedene Szenarien übersät. Der Dienst ist geworden:
Kompliziert und schwer zu lesen
Schwer verständlich und schwer nachvollziehbar
Anfälliger für Fehler
Verletzung der Einzelverantwortung (Bearbeitung zu vieler verschiedener Fälle)
Nahezu unmöglich, gründlich zu testen
Der Dienst hat seine Grenzen überschritten in Bezug auf Verantwortlichkeiten und Logik.
Eine Lösung: Fabrikmuster mit spezialisierten Diensten
Verwenden Sie das Fabrikmuster, um Entscheidungen am Eingangspunkt zu treffen, und übergeben Sie dann an spezialisierte Dienste, die ihre spezifische Logik ohne Bedingungsanweisungen behandeln.
Beispiel aus unserer Codebasis:
Der BillingPortalServiceFactory bestimmt, ob die Abrechnung für eine Organisation, ein Team oder einen einzelnen Benutzer erfolgt und gibt dann den entsprechenden Dienst zurück:
Jeder Dienst behandelt dann seine spezifische Logik, ohne "bin ich eine Organisation oder ein Team?" zu überprüfen:
Warum das wichtig ist
Dienste bleiben fokussiert
Jeder Dienst hat eine Verantwortung und muss nichts über andere Kontexte wissen. Der
OrganizationBillingPortalServiceenthält keine if-Anweisungen, dieif (isTeam)oderif (isUser)überprüfen. Es weiß nur, wie man mit Organisationen umgehen kann.
Änderungen sind isoliert
Wenn Sie die Organisation Abrechnungslogik ändern müssen, berühren Sie nur
OrganizationBillingPortalService. Sie riskieren nicht, die Team- oder Benutzerabrechnung zu brechen. Sie müssen keine verschachtelten Bedingungsanweisungen nachverfolgen, um herauszufinden, welchen Weg Ihr Code nimmt.
Das Testen ist unkompliziert
Testen Sie jeden Dienst unabhängig mit seinen spezifischen Szenarien. Es besteht keine Notwendigkeit, jede Kombination von Bedingungsanweisungen über verschiedene Kontexte hinweg zu testen.
Neue Anforderungen verschmutzen nicht den vorhandenen Code
z.B. Wenn Sie Enterprise-Abrechnung mit verschiedenen Regeln hinzufügen müssen, erstellen Sie
EnterpriseBillingPortalService. Die Fabrik erhält eine weitere Bedingung, aber bestehende Dienste bleiben unberührt und fokussiert.
Wie man es erreicht
Verlagern Sie Bedingungsanweisungen zu Controllern, Fabriken oder Routinglogik. Lassen Sie diese Eingabepunkte die Entscheidung darüber treffen, welchen Dienst zu verwenden ist.
Halten Sie Dienste rein und fokussiert auf eine einzelne Verantwortung. Wenn ein Dienst überprüfen muss "welcher Typ bin ich?", benötigen Sie wahrscheinlich mehrere Dienste.
Bevorzugen Sie Polymorphismus gegenüber Bedingungsanweisungen
Schnittstellen definieren den Vertrag. Konkrete Implementierungen liefern die Details.
Beobachten Sie die Ansammlung von if-Anweisungen
Während der Code-Review, wenn Sie sehen, dass ein Dienst Bedingungsanweisungen für verschiedene Szenarien erhält, ist das ein Signal, um in spezialisierte Dienste zu refaktorieren.
API-Design: Dünne Controller und HTTP-Abstraktion
Controller sind dünne Schichten, die nur HTTP-Belange behandeln.
Sie nehmen Anfragen entgegen, verarbeiten sie und transformieren Daten in DTOs, die an die Kernanwendungslogik übergeben werden. Zukünftig sollte keine Anwendungs- oder Kernlogik in API-Routen oder tRPC-Handlern zu finden sein.
Wir müssen die HTTP-Technologie von unserer Anwendung trennen.
Die Art und Weise, wie wir Daten zwischen Client und Server übertragen (sei es REST, tRPC, etc.), sollte nicht beeinflussen, wie unsere Kernanwendung funktioniert. HTTP ist ein Übermittlungsmechanismus und kein architektonischer Treiber.
Controller-Verantwortungen (und NUR diese):
Eingehende Anfragen empfangen und validieren
Daten aus Anfrageparametern, Body, Headern extrahieren
Anforderungsdaten in DTOs transformieren
Geeignete Anwendungsdienste mit diesen DTOs aufrufen
Antworten der Anwendungsdienste in Antwort-DTOs transformieren
HTTP-Antworten mit den richtigen Statuscodes zurückgeben
Controller sollten NICHT:
Geschäftslogik oder Domänenregeln enthalten
Direkt auf Datenbanken oder externe Dienste zugreifen
Komplexe Datenumwandlungen oder Berechnungen durchführen
Entscheidungen darüber treffen, was die Anwendung tun sollte
Über Implementierungsdetails der Domäne Bescheid wissen
Beispiel für ein dünnes Controller-Muster:
API-Versionierung und Breaking Changes
Keine Breaking Changes. Das ist entscheidend. Sobald ein API-Endpunkt öffentlich ist, muss er stabil bleiben. Breaking Changes zerstören das Entwicklervetrauen und schaffen Integrations-Albträume für unsere Nutzer.
Strategien zur Vermeidung von Breaking Changes:
Fügen Sie neue Felder immer als optional hinzu
Verwenden Sie API-Versionierung, wenn Sie bestehendes Verhalten ändern müssen
Veraltete alte Endpunkte schonend mit klaren Migrationspfaden
Erhalten Sie die Rückwärtskompatibilität für mindestens zwei Hauptversionen aufrecht
Wenn Sie Breaking Changes vornehmen müssen:
Erstellen Sie eine neue API-Version mit dateispezifischer Versionierung in API v2 (vielleicht schauen wir uns auch die kürzlich eingeführte benannte Versionsnummerierung von Stripe an)
Führen Sie während der Übergangsphase beide Versionen gleichzeitig aus (wir tun dies bereits in API v2)
Stellen Sie bei Möglichkeit automatisierte Migrationstools bereit
Geben Sie den Benutzern genügend Zeit zum Migrieren (mindestens 6 Monate für öffentliche APIs)
Dokumentieren Sie genau, was sich geändert hat und warum
Performance und Algorithmuskomplexität
Wir entwickeln für große Organisationen und Teams. Was bei 10 Nutzern oder 50 Datensätzen gut funktioniert, kann unter dem Gewicht des Unternehmensskalar zusammenbrechen. Performance ist nichts, was wir später optimieren. Es ist etwas, das wir von Anfang an korrekt aufbauen.
Denken Sie von Anfang an über Skalierbarkeit nach
Beim Erstellen von Funktionen immer fragen: "Wie verhält es sich mit 1.000 Benutzern? 10.000 Datensätzen? 100.000 Operationen?" Der Unterschied zwischen O(n) und O(n²)-Algorithmen mag in der Entwicklung unmerklich sein, kann aber in der Produktion katastrophal sein.
Häufige O(n²)-Muster zu vermeiden:
Verschachtelte Array-Iterationen (
.mapinnerhalb von.map,.forEachinnerhalb von.forEach)Array-Methoden wie
.some,.findoder.filterin Schleifen oder RückrufenJedes Element gegen jedes andere Element ohne Optimierung prüfen
Chained Filters oder verschachteltes Mappen über große Listen
Beispiel aus der Praxis: Für 100 verfügbare Slots und 50 belegte Zeiten führt ein O(n²)-Algorithmus 5.000 Prüfungen durch. Skalieren Sie das auf 500 Slots und 200 belegte Zeiten und Sie führen 100.000 Operationen durch. Das ist eine 20-fache Erhöhung der Rechenlast nur für eine 5-fache Erhöhung der Daten.
Wählen Sie die richtigen Datenstrukturen und Algorithmen
Die meisten Leistungsprobleme werden durch die Auswahl besserer Datenstrukturen und Algorithmen gelöst:
Sortieren + Frühausstieg: Sortieren Sie Ihre Daten einmal und brechen Sie Schleifen ab, wenn Sie wissen, dass verbleibende Elemente nicht übereinstimmen
Binäre Suche: Verwenden Sie die binäre Suche für Suchen in sortierten Arrays anstelle von linearen Scans
Zweipunkt-Techniken: Zum Zusammenführen oder Überschneiden sortierter Sequenzen, gehen Sie durch beide mit Zeigern anstelle von verschachtelten Schleifen
Hash-Maps/Sets: Verwenden Sie Objekte oder Sets für O(1)-Suche anstelle von
.findoder.includesauf ArraysIntervall-Bäume: Für Planung, Verfügbarkeit und Bereichsabfragen, verwenden Sie ordnungsgemäße Baumstrukturen anstelle von brutalen Vergleichen
Beispiel Umwandlung:
Automatisierte Leistungstests
Wir werden mehrere Abwehrmechanismen gegen Leistungsregressionen umsetzen:
Linting-Regeln die markieren:
Funktionen mit verschachtelten Schleifen oder verschachtelten Array-Methoden
Mehrfach verschachtelte
.some,.findoder.filter-AufrufeRekursion ohne Speicherung
Bekannte Anti-Muster für unser Gebiet (Planung, Verfügbarkeitsprüfungen usw.)
Performance-Benchmarks in CI die:
Kritische Algorithmen auf realistischen, großskaligen Daten ausführen
Ausführungszeiten gegen Basislinie bei jedem PR vergleichen
Zusammenführungen blockieren, die Leistungsregressionen einführen
Mit Unternehmensmaßstab-Daten testen (tausende Benutzer, zehntausende Datensätze)
Produktionsüberwachung die:
Ausführungszeit für kritische Pfade verfolgt
Alarmiert, wenn Algorithmen langsamer werden, wenn Daten wachsen
Erkennt Regressionen, bevor Benutzer sie bemerken
Bietet reale Leistungsdaten zur Optimierungsvorbereitung
Performance ist ein Feature
Performance ist nicht optional. Es ist nichts, was wir "später angehen". Für Unternehmenskunden, die über große Teams buchen, bedeuten langsame Antworten verlorene Produktivität und frustrierte Benutzer (unsere Erfahrung mit einigen größeren Unternehmenskunden ist ein Zeugnis dafür).
Jeder Ingenieur sollte:
Ihr Code profilieren, bevor Sie optimieren, aber von Anfang an über die Komplexität nachdenken
Mit realistischen, großskaligen Daten testen (nicht nur 5 Testdatensätze). Wir haben bereits Seed-Skripte gebaut. Wir müssen sie wahrscheinlich erweitern.
Von Anfang an effiziente Algorithmen und Datenstrukturen wählen
Bei Code-Review auf verschachtelte Iterationen achten
Jeden Algorithmus in Frage stellen, der mit dem Produkt von zwei Variablen skaliert
Die NP-schwere Realität der Planung
Planungsprobleme sind von Natur aus NP-schwer. Das bedeutet, dass mit zunehmender Anzahl von Einschränkungen, Teilnehmern oder Zeitschlitzen die Rechenkomplexität exponentiell ansteigen kann. Die meisten optimalen Planungsalgorithmen haben in der worst-case-Szenario exponentielle Zeitkomplexität, die Algorithmuswahl entscheidend macht.
Realweltimplikationen:
Die optimale Meetingzeit für 10 Personen über 3 Zeitzonen mit individuellen Verfügbarkeitsbeschränkungen zu finden, ist rechnerisch teuer
Die Hinzufügung von Konflikterkennung, Puffern und einer Vielzahl anderer Optionen verstärkt das Problem
Schlechte Algorithmuswahl, die bei kleinen Teams gut funktionierte, wird für große Organisationen völlig unbrauchbar
Was Millisekunden bei 5 Benutzern dauert, könnte viele Sekunden bei Organisationen dauern
Strategien zum Management der NP-schweren Komplexität:
Verwenden Sie Approximationsalgorithmen, die "gut genug"-Lösungen schnell finden, anstatt perfekte Lösungen langsam
Implementieren Sie aggressives Caching von berechneten Zeitplänen und Verfügbarkeiten
Berechnen Sie häufige Szenarien während der Nebenzeiten vor
Teilen Sie große Planungsprobleme in kleinere, handlichere Stücke
Setzen Sie vernünftige Zeitlimits und greifen Sie bei Bedarf auf einfachere Algorithmen zurück
Aus diesem Grund ist Performance nicht nur ein nettes Extra in Planungssoftware. Es ist die Grundlage, die bestimmt, ob Ihr System auf Unternehmensbedürfnisse skalieren kann oder unter realen Nutzungsmustern zusammenbricht.
Anforderungen an die Codeabdeckung
Globales Abdeckungs-Tracking
Wir verfolgen die Gesamtcodeabdeckung als wichtigen Metrik, die sich im Laufe der Zeit verbessert. Das gibt uns Einblicke in unsere Test-Reife und hilft, Bereiche zu identifizieren, die Aufmerksamkeit erfordern. Der globale Abdeckungsprozentsatz wird auf unseren Dashboards im Vordergrund angezeigt.
80%+ Abdeckung für neuen Code
Jeder PR muss eine nahezu 80%+ Abdeckung für den Code haben, den er einführt oder ändert. Dies wird automatisch in unserer CI-Pipeline erzwungen. Wenn Sie 50 Zeilen neuen Code hinzufügen, müssen diese 50 Zeilen durch Tests abgedeckt sein. Wenn Sie eine vorhandene Funktion ändern, müssen Ihre Änderungen getestet werden. Dies ist eine Gesamtcodeabdeckung. Die Abdeckung von Unittests muss nahezu 100% erreichen, insbesondere mit der Möglichkeit, KI zu verwenden, um dabei zu helfen, diese zu generieren.
Das Argument "Abdeckung ist nicht die ganze Geschichte" entkräften: Ja, wir wissen, dass Abdeckung keine perfekten Tests garantiert. Wir wissen, dass Sie sinnlose Tests schreiben können, die jede Zeile berühren, aber nichts Bedeutendes testen. Wir wissen, dass Abdeckung nur einer von vielen Metriken ist. Aber es ist sicherlich besser, einen hohen Prozentsatz anzustreben, als keine Ahnung zu haben, wo Sie sich befinden.
Erfolg messen
"Velocity" (dies von Scrum gestohlen, obwohl wir Scrum nicht verwenden werden)
Stetiges Wachstum in monatlichen Statistiken (Funktionen, Verbesserungen, Refaktorierungen)
Qualität
Reduzieren Sie den Arbeitsaufwand in PRs, der für Korrekturen aufgewendet wird, von derzeit 35% auf 20% oder weniger bis Ende 2026 (berechnet basierend auf Dateieingaben und Änderungen/Löschungen)
Architekturale Gesundheit
Metriken zur Muster-Adhärenz, technologisches Koppeln, Grenzverletzungen
Überprüfungseffizienz
Kleinere PRs, schnellere Überprüfungen, weniger Feedback-Runden
Anwendungs- und API-Verfügbarkeit
Wie nah sind wir an 99,99%?

Beginnen Sie noch heute kostenlos mit Cal.com!
Erleben Sie nahtlose Planung und Produktivität ohne versteckte Gebühren. Melden Sie sich in Sekunden an und beginnen Sie noch heute, Ihre Planung zu vereinfachen, ganz ohne Kreditkarte!



