" height="18.016311920580208px" id="GKXyVanMq" stroke-dasharray="0" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgb(0, 0, 0)" transform="translate(3 3)" width="18px"/></svg>)
"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient><linearGradient id="CBS1bzkxF-2031533640-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgb(255, 255, 255)"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient><linearGradient id="Jd7AK81w9-2031533640-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgb(255, 255, 255)"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient></defs><g d="M 0 16 L 0 0 L 16 0 L 16 16 Z M 9.167 5.167 C 9.167 4.891 8.943 4.667 8.667 4.667 C 8.391 4.667 8.167 4.891 8.167 5.167 C 8.167 6.784 7.809 7.834 7.155 8.488 C 6.501 9.143 5.451 9.5 3.833 9.5 C 3.557 9.5 3.333 9.724 3.333 10 C 3.333 10.276 3.557 10.5 3.833 10.5 C 5.451 10.5 6.501 10.857 7.155 11.512 C 7.809 12.166 8.167 13.216 8.167 14.833 C 8.167 15.109 8.391 15.333 8.667 15.333 C 8.943 15.333 9.167 15.109 9.167 14.833 C 9.167 13.216 9.524 12.166 10.178 11.512 C 10.832 10.857 11.883 10.5 13.5 10.5 C 13.776 10.5 14 10.276 14 10 C 14 9.724 13.776 9.5 13.5 9.5 C 11.883 9.5 10.832 9.143 10.178 8.488 C 9.524 7.834 9.167 6.784 9.167 5.167 Z M 4 3.667 C 4 3.483 3.851 3.333 3.667 3.333 C 3.483 3.333 3.333 3.483 3.333 3.667 C 3.333 4.32 3.189 4.715 2.952 4.952 C 2.715 5.189 2.32 5.333 1.667 5.333 C 1.483 5.333 1.333 5.483 1.333 5.667 C 1.333 5.851 1.483 6 1.667 6 C 2.32 6 2.715 6.145 2.952 6.382 C 3.189 6.618 3.333 7.013 3.333 7.667 C 3.333 7.851 3.483 8 3.667 8 C 3.851 8 4 7.851 4 7.667 C 4 7.013 4.145 6.618 4.382 6.382 C 4.618 6.145 5.013 6 5.667 6 C 5.851 6 6 5.851 6 5.667 C 6 5.483 5.851 5.333 5.667 5.333 C 5.013 5.333 4.618 5.189 4.382 4.952 C 4.145 4.715 4 4.32 4 3.667 Z M 7.333 1 C 7.333 0.816 7.184 0.667 7 0.667 C 6.816 0.667 6.667 0.816 6.667 1 C 6.667 1.422 6.573 1.65 6.445 1.778 C 6.317 1.906 6.089 2 5.667 2 C 5.483 2 5.333 2.149 5.333 2.333 C 5.333 2.517 5.483 2.667 5.667 2.667 C 6.089 2.667 6.317 2.761 6.445 2.889 C 6.573 3.016 6.667 3.244 6.667 3.667 C 6.667 3.851 6.816 4 7 4 C 7.184 4 7.333 3.851 7.333 3.667 C 7.333 3.244 7.427 3.016 7.555 2.889 C 7.683 2.761 7.911 2.667 8.333 2.667 C 8.517 2.667 8.667 2.517 8.667 2.333 C 8.667 2.149 8.517 2 8.333 2 C 7.911 2 7.683 1.906 7.555 1.778 C 7.427 1.65 7.333 1.422 7.333 1 Z" fill="transparent" height="16px" id="aoZYv33vR" width="16px"><path d="M 0 16 L 0 0 L 16 0 L 16 16 Z" fill="transparent" height="16px" id="Z2uGmhW9f" width="16px"/><g d="M 7.833 4.5 C 7.833 4.224 7.609 4 7.333 4 C 7.057 4 6.833 4.224 6.833 4.5 C 6.833 6.117 6.476 7.168 5.822 7.822 C 5.168 8.476 4.117 8.833 2.5 8.833 C 2.224 8.833 2 9.057 2 9.333 C 2 9.61 2.224 9.833 2.5 9.833 C 4.117 9.833 5.168 10.191 5.822 10.845 C 6.476 11.499 6.833 12.549 6.833 14.167 C 6.833 14.443 7.057 14.667 7.333 14.667 C 7.609 14.667 7.833 14.443 7.833 14.167 C 7.833 12.549 8.191 11.499 8.845 10.845 C 9.499 10.191 10.549 9.833 12.167 9.833 C 12.443 9.833 12.667 9.61 12.667 9.333 C 12.667 9.057 12.443 8.833 12.167 8.833 C 10.549 8.833 9.499 8.476 8.845 7.822 C 8.191 7.168 7.833 6.117 7.833 4.5 Z M 2.667 3 C 2.667 2.816 2.517 2.667 2.333 2.667 C 2.149 2.667 2 2.816 2 3 C 2 3.654 1.855 4.048 1.618 4.285 C 1.382 4.522 0.987 4.667 0.333 4.667 C 0.149 4.667 0 4.816 0 5 C 0 5.184 0.149 5.333 0.333 5.333 C 0.987 5.333 1.382 5.478 1.618 5.715 C 1.855 5.952 2 6.346 2 7 C 2 7.184 2.149 7.333 2.333 7.333 C 2.517 7.333 2.667 7.184 2.667 7 C 2.667 6.346 2.811 5.952 3.048 5.715 C 3.285 5.478 3.68 5.333 4.333 5.333 C 4.517 5.333 4.667 5.184 4.667 5 C 4.667 4.816 4.517 4.667 4.333 4.667 C 3.68 4.667 3.285 4.522 3.048 4.285 C 2.811 4.048 2.667 3.654 2.667 3 Z M 6 0.333 C 6 0.149 5.851 0 5.667 0 C 5.483 0 5.333 0.149 5.333 0.333 C 5.333 0.756 5.239 0.984 5.112 1.112 C 4.984 1.239 4.756 1.333 4.333 1.333 C 4.149 1.333 4 1.483 4 1.667 C 4 1.851 4.149 2 4.333 2 C 4.756 2 4.984 2.094 5.112 2.222 C 5.239 2.35 5.333 2.578 5.333 3 C 5.333 3.184 5.483 3.333 5.667 3.333 C 5.851 3.333 6 3.184 6 3 C 6 2.578 6.094 2.35 6.222 2.222 C 6.35 2.094 6.578 2 7 2 C 7.184 2 7.333 1.851 7.333 1.667 C 7.333 1.483 7.184 1.333 7 1.333 C 6.578 1.333 6.35 1.239 6.222 1.112 C 6.094 0.984 6 0.756 6 0.333 Z" fill="transparent" height="14.66671286102295px" id="ae6ccdFme" transform="translate(1.333 0.667)" width="12.66663px"><path d="M 5.833 0.5 C 5.833 0.224 5.609 0 5.333 0 C 5.057 0 4.833 0.224 4.833 0.5 C 4.833 2.117 4.476 3.168 3.822 3.822 C 3.168 4.476 2.117 4.833 0.5 4.833 C 0.224 4.833 0 5.057 0 5.333 C 0 5.61 0.224 5.833 0.5 5.833 C 2.117 5.833 3.168 6.191 3.822 6.845 C 4.476 7.499 4.833 8.549 4.833 10.167 C 4.833 10.443 5.057 10.667 5.333 10.667 C 5.609 10.667 5.833 10.443 5.833 10.167 C 5.833 8.549 6.191 7.499 6.845 6.845 C 7.499 6.191 8.549 5.833 10.167 5.833 C 10.443 5.833 10.667 5.61 10.667 5.333 C 10.667 5.057 10.443 4.833 10.167 4.833 C 8.549 4.833 7.499 4.476 6.845 3.822 C 6.191 3.168 5.833 2.117 5.833 0.5 Z" fill="url(%23t2lXByE48-2031533640-linear-gradient)" height="10.66671px" id="t2lXByE48" transform="translate(2 4)" width="10.66663px"/><path d="M 2.667 0.333 C 2.667 0.149 2.517 0 2.333 0 C 2.149 0 2 0.149 2 0.333 C 2 0.987 1.855 1.382 1.618 1.618 C 1.382 1.855 0.987 2 0.333 2 C 0.149 2 0 2.149 0 2.333 C 0 2.517 0.149 2.667 0.333 2.667 C 0.987 2.667 1.382 2.811 1.618 3.048 C 1.855 3.285 2 3.68 2 4.333 C 2 4.517 2.149 4.667 2.333 4.667 C 2.517 4.667 2.667 4.517 2.667 4.333 C 2.667 3.68 2.811 3.285 3.048 3.048 C 3.285 2.811 3.68 2.667 4.333 2.667 C 4.517 2.667 4.667 2.517 4.667 2.333 C 4.667 2.149 4.517 2 4.333 2 C 3.68 2 3.285 1.855 3.048 1.618 C 2.811 1.382 2.667 0.987 2.667 0.333 Z" fill="url(%23CBS1bzkxF-2031533640-linear-gradient)" height="4.66667px" id="CBS1bzkxF" transform="translate(0 2.667)" width="4.66667px"/><path d="M 2 0.333 C 2 0.149 1.851 0 1.667 0 C 1.483 0 1.333 0.149 1.333 0.333 C 1.333 0.756 1.239 0.984 1.112 1.112 C 0.984 1.239 0.756 1.333 0.333 1.333 C 0.149 1.333 0 1.483 0 1.667 C 0 1.851 0.149 2 0.333 2 C 0.756 2 0.984 2.094 1.112 2.222 C 1.239 2.35 1.333 2.578 1.333 3 C 1.333 3.184 1.483 3.333 1.667 3.333 C 1.851 3.333 2 3.184 2 3 C 2 2.578 2.094 2.35 2.222 2.222 C 2.35 2.094 2.578 2 3 2 C 3.184 2 3.333 1.851 3.333 1.667 C 3.333 1.483 3.184 1.333 3 1.333 C 2.578 1.333 2.35 1.239 2.222 1.112 C 2.094 0.984 2 0.756 2 0.333 Z" fill="url(%23Jd7AK81w9-2031533640-linear-gradient)" height="3.333333px" id="Jd7AK81w9" transform="translate(4 0)" width="3.3333399999999997px"/></g></g></svg>)
" height="24px" id="WCm44spAV" width="24px"/><path d="M 3.892 7.742 C 1.674 7.742 0 6.014 0 3.882 C 0 1.738 1.589 0 3.892 0 C 5.107 0 5.951 0.374 6.623 1.173 L 5.566 2.09 C 5.118 1.621 4.564 1.386 3.892 1.386 C 2.452 1.386 1.547 2.517 1.547 3.882 C 1.547 5.246 2.452 6.356 3.924 6.356 C 4.649 6.356 5.193 6.111 5.63 5.63 L 6.718 6.558 C 6.153 7.24 5.193 7.742 3.892 7.742 Z" fill="rgb(255, 255, 255)" height="7.741500000000002px" id="XEPpGD7l5" transform="translate(4 8.25)" width="6.717999999999989px"/><path d="M 2.74 7.922 C 1.215 7.922 0 6.632 0 5.032 C 0 3.433 1.215 2.122 2.74 2.122 C 3.7 2.122 4.201 2.516 4.5 3.113 L 4.5 2.239 L 5.928 2.239 L 5.928 7.784 L 4.531 7.784 L 4.531 6.877 C 4.233 7.507 3.731 7.922 2.74 7.922 Z M 1.439 5.023 C 1.439 5.865 2.057 6.622 2.975 6.622 C 3.924 6.622 4.531 5.897 4.531 5.033 C 4.531 4.169 3.924 3.423 2.975 3.423 C 2.057 3.423 1.439 4.159 1.439 5.022 Z M 6.784 7.784 L 6.784 0 L 8.224 0 L 8.224 7.784 L 6.784 7.784 Z" fill="rgb(255, 255, 255)" height="7.9224997406005855px" id="lGDJupIUR" transform="translate(10.5 8)" width="8.223500194549558px"/></g></svg>)
" width="18px"><path d="M 2 8 C 0.895 8 0 7.105 0 6 L 0 2 C 0 0.895 0.895 0 2 0 L 6 0 C 7.105 0 8 0.895 8 2 L 8 6 C 8 7.105 7.105 8 6 8 Z" fill="transparent" height="8px" id="ZrCrI93dV" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" width="8px"/><path d="M 0 0 L 0 4 C 0 5.105 0.895 6 2 6 L 6 6" fill="transparent" height="6px" id="emltWYAiE" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" transform="translate(4 8)" width="6px"/><path d="M 2 8 C 0.895 8 0 7.105 0 6 L 0 2 C 0 0.895 0.895 0 2 0 L 6 0 C 7.105 0 8 0.895 8 2 L 8 6 C 8 7.105 7.105 8 6 8 Z" fill="transparent" height="8px" id="WpBecYDfi" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" transform="translate(10 10)" width="8px"/></g></svg>)

Ingénierie en 2026 et au-delà
Nous construisons une infrastructure qui ne doit presque jamais échouer. Pour y parvenir, nous agissons rapidement tout en livrant un logiciel de qualité incroyable, sans raccourcis ni compromis. Ce document décrit les normes d'ingénierie qui nous guideront jusqu'en 2026 et au-delà.

Structure de l'équipe
Notre organisation d'ingénierie se compose de cinq équipes principales, chacune avec des responsabilités distinctes :
Équipe Fondation : Se concentre sur l'établissement et le maintien de normes de codage et de modèles architecturaux. Cette équipe travaille en collaboration avec d'autres équipes pour établir les meilleures pratiques à travers l'organisation.
Équipes Consommateur, Entreprise et Plateforme : Équipes axées sur le produit qui livrent rapidement des fonctionnalités tout en maintenant les normes de qualité établies dans ce document. Ces équipes démontrent que la rapidité et la qualité ne sont pas mutuellement exclusives.
Équipe Communauté : Responsable de l'examen rapide des PRs de la communauté open source, fournissant des commentaires et guidant ce travail jusqu'à la fusion. Cette équipe s'assure que nos contributeurs open source vivent une excellente expérience et que leurs contributions respectent nos normes de qualité.
Nos résultats jusqu'à présent
Les données parlent d'elles-mêmes. Au cours de l'année et demie écoulée, nous avons fondamentalement transformé notre manière de concevoir des logiciels :
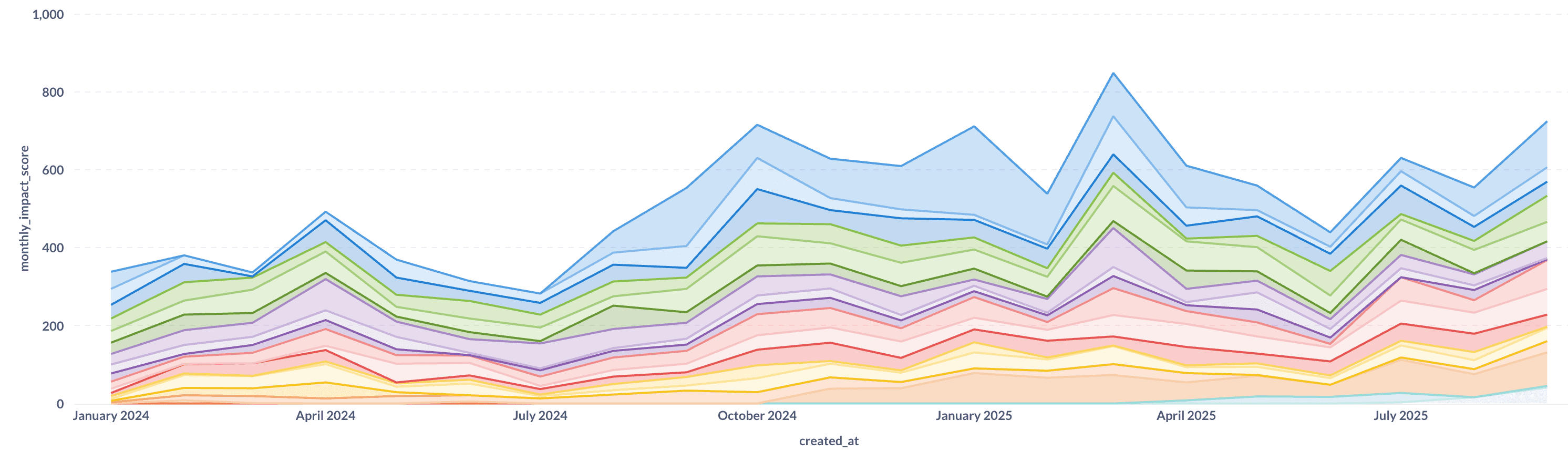
Nous avons à peu près doublé notre production d'ingénierie tout en améliorant simultanément la qualité. Encore plus impressionnant est le changement dans ce que nous construisons :
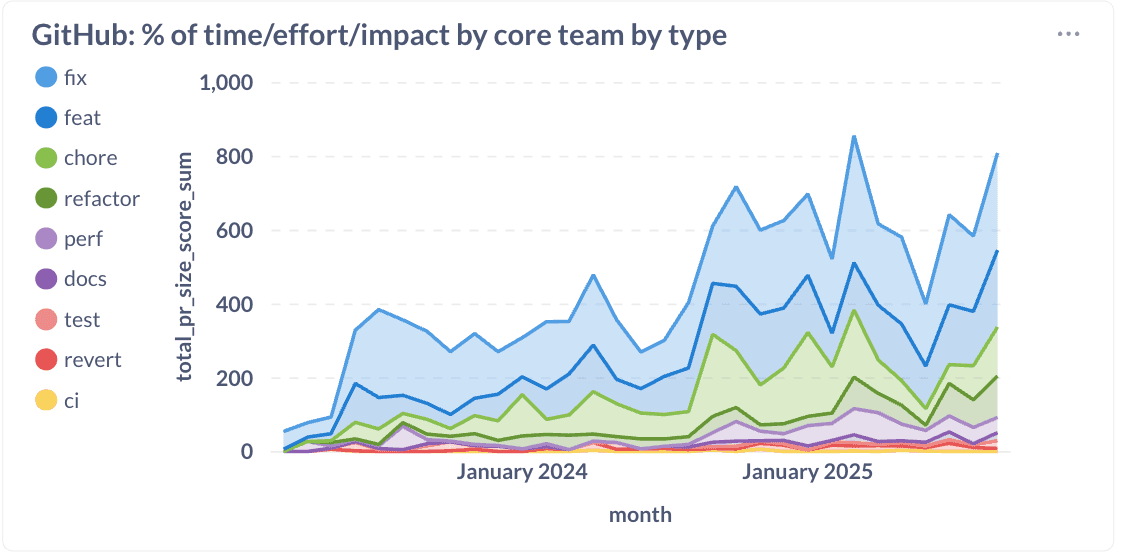
Nous avons réussi à réallouer environ 20 % de l'effort d'ingénierie des corrections vers les fonctionnalités, les améliorations de performance, les refontes et les tâches ménagères. Ce changement démontre qu'investir dans la qualité et l'architecture ne vous ralentit pas. Cela vous accélère.
La Fondation de Cal.com favorise l'excellence pour coss.com
Cal.com est une entreprise stable et rentable que nous continuerons à développer.
Ce succès nous offre un avantage unique alors que nous construisons coss.com. Contrairement aux premiers jours de Cal.com, où nous devions avancer rapidement pour atteindre l'adéquation produit-marché et bâtir une entreprise durable, coss.com part d'une position de force.
Nous n'avons pas besoin de nous précipiter pour coss.com.
La stabilité de Cal.com signifie que nous pouvons nous permettre de construire coss.com de la bonne manière dès le premier jour. Nous avons le luxe d'implémenter ces normes d'ingénierie sans la pression des exigences du marché ou des contraintes de financement immédiates. C'est une position de départ fondamentalement différente.
La "lenteur" est un investissement, pas un coût.
Oui, suivre ces normes peut sembler plus lent au départ et peut même être frustrant pour certains ingénieurs. Écrire des DTOs prend plus de temps que de passer directement des types de base de données au frontend. Créer des abstractions appropriées et une injection de dépendances nécessite plus de conception en amont. Maintenir une couverture de test de plus de 80 % pour le nouveau code exige de la discipline. Mais cette lenteur apparente est temporaire, et le rendement est exponentiel.
Considérez les rendements composés...
Un code architecturé correctement dès le départ n'a pas besoin de refontes massives plus tard
Une couverture de test élevée évite des bugs qui consommant des semaines de débogage et de corrections rapides (voir 2023 à mi-2024)
Les abstractions appropriées permettent d'ajouter de nouvelles fonctionnalités beaucoup plus rapidement au fil du temps
Des limites claires et des DTOs préviennent l'érosion architecturale qui finit par exiger des réécritures complètes
La trajectoire de Cal.com montre ce qui se passe lorsque vous optimisez pour la vitesse immédiate. Une vitesse initiale élevée qui se dégrade progressivement à mesure que la dette technique s'accumule, les raccourcis architecturaux créent des goulots d'étranglement, et plus de temps est consacré à résoudre des problèmes qu'à construire des fonctionnalités (voir le graphique précédent où nous avons passé 55-60 % de l'effort d'ingénierie sur des corrections).
La trajectoire de coss.com embrassera le pouvoir de construire correctement dès le premier jour. Une vélocité initiale légèrement plus lente pendant que l'on établit des modèles appropriés, suivie d'une accélération exponentielle à mesure que ces modèles rapportent des dividendes et permettent un développement plus rapide avec plus de confiance.
Principes de base
1. Pas de qualité différée
Nous minimiserons "Je le ferai dans un PR de suivi" pour les petites refontes.
Les PRs de suivi pour des améliorations mineures se matérialisent rarement. Au lieu de cela, ils s'accumulent en tant que dette technique qui nous pèse des mois ou des années plus tard. Si une petite refonte peut être effectuée maintenant, faites-le maintenant. Les suivis devraient être réservés aux changements substantiels qui justifient réellement des PRs séparés ou à des cas exceptionnels et urgents.
2. Des normes élevées dans les revues de code
Ne laissez pas passer des PRs avec beaucoup de détails juste pour éviter d'être "la mauvaise personne".
C'est précisément comme ça que les bases de code deviennent négligées avec le temps. La revue de code ne consiste pas à être gentil. Il s'agit de maintenir les normes de qualité que notre infrastructure exige. Chaque détail compte. Chaque violation de modèle compte. Traitez-les avant de fusionner, pas après.
3. Se pousser les uns les autres à faire ce qui est juste
Nous nous tenons mutuellement responsables de la qualité
Prendre des raccourcis peut sembler plus rapide sur le moment, mais cela crée des problèmes qui ralentissent tout le monde plus tard. Lorsque vous voyez un coéquipier sur le point de fusionner un PR avec des problèmes évidents, parlez-en. Lorsqu'une personne suggère une solution rapide au lieu de la bonne, réagissez. Lorsque vous êtes tenté de sauter des tests ou d'ignorer les motifs architecturaux, attendez-vous à ce que vos coéquipiers vous défient.
Ce n'est pas être difficile ou ralentir les gens
C'est assumer collectivement la responsabilité de notre base de code et de notre réputation. Chaque raccourci pris par une personne devient le problème de tout le monde. Chaque raccourci aujourd'hui signifie plus de sessions de débogage, plus de corrections rapides, et plus de clients frustrés demain.
Démocratisez le fait de défier les mauvaises décisions, respectueusement
Si quelqu'un dit "mettons simplement ça en dur pour l'instant", il devrait s'attendre à ce que la réponse soit "que faudrait-il pour le faire correctement dès le début ?". Si quelqu'un veut soumettre du code non testé, l'équipe devrait s'y opposer. Si quelqu'un suggère de copier-coller au lieu de créer une abstraction appropriée, appelez ça respectueusement.
Nous construisons quelque chose qui doit presque jamais échouer
Ce niveau de fiabilité n'arrive pas par hasard. Cela se produit lorsque chaque ingénieur se sent responsable de la qualité, non seulement de son propre code, mais aussi de l'ensemble du système. Nous réussissons en tant qu'équipe ou échouons en tant qu'équipe.
4. Viser la simplicité
Privilégier la clarté plutôt que la ruse
L'objectif est d'écrire du code facile à lire et à comprendre rapidement, pas une complexité élégante. Des systèmes simples réduisent la charge cognitive pour chaque ingénieur.
Posez-vous les bonnes questions
Suis-je vraiment en train de résoudre le problème à portée de main ?
Est-ce que je réfléchis trop à des cas d'utilisation futurs possibles ?
Ai-je envisagé au moins une autre alternative pour résoudre cela ? Comment cela se compare-t-il ?
Simple ne signifie pas dépourvu de fonctionnalités
Juste parce que notre objectif est de créer des systèmes simples, cela ne signifie pas qu'ils doivent sembler anémiques et dépourvus de fonctionnalités évidentes.
5. Automatiser tout
Exploiter l'IA
Générer 80 % du code boilerplate et non critique en utilisant l'IA, nous permettant de nous concentrer uniquement sur la logique métier complexe et les architectures critiques.
Construire des alertes sans bruit et une gestion des erreurs intelligentes.
Les tests manuels sont de plus en plus une chose du passé. L'IA peut rapidement et intelligemment construire des suites de tests titanesques pour nous.
Notre CI est le boss final
Tout dans ce document de normes est vérifié avant que le code ne soit fusionné dans les PRs
Aucune surprise ne fait son chemin dans le main
Les vérifications sont rapides et utiles
Normes architecturales
Nous passons à un modèle architectural strict basé sur Architecture Slice Verticale et Conception Pilotée par le Domaine (DDD). Les patrons et principes suivants seront appliqués rigoureusement dans les revues de PR et via le linting.
Architecture Slice Verticale : packages/features
Notre base de code est organisée par domaine, pas par couche technique. Le répertoire packages/features constitue le cœur de cette approche architecturale. Chaque dossier à l'intérieur représente une tranche verticale complète de l'application, conduite par le domaine qu'elle touche.
Structure :
Chaque dossier de fonctionnalité est une tranche verticale autonome qui inclut tout ce qui est nécessaire pour ce domaine :
Logique de domaine : Les règles commerciales principales et les entités spécifiques à cette fonctionnalité
Services d'application : Orchestration de cas d'utilisation pour ce domaine
Dépôts : Accès aux données spécifique aux besoins de cette fonctionnalité
DTOs : Objets de transfert de données pour traverser les frontières
Composants UI : Composants frontend relatifs à cette fonctionnalité (le cas échéant)
Tests : Tests unitaires, d'intégration et de bout en bout pour cette fonctionnalité
Pourquoi les slices verticales sont importantes
L'architecture traditionnelle par couche s'organise par préoccupations techniques :
Cela crée plusieurs problèmes :
Les changements apportés à une fonctionnalité nécessitent de toucher des fichiers dispersés dans de nombreux répertoires
Il est difficile de comprendre ce que fait une fonctionnalité car son code est fragmenté
Les équipes se marchent sur les pieds lorsqu'elles travaillent sur des fonctionnalités différentes
Vous ne pouvez pas facilement extraire ou déprécier une fonctionnalité
L'architecture slice verticale s'organise par domaine :
Cela résout ces problèmes :
Tout ce qui concerne la disponibilité se trouve dans
packages/features/availabilityVous pouvez comprendre l'ensemble de la fonctionnalité de disponibilité en explorant un répertoire
Les équipes peuvent travailler sur des fonctionnalités différentes sans conflits (si l'équipe d'ingénierie de Cal.com grandit, mais presque certainement dans coss.com nous aurons des équipes prenant en charge des packages majeurs)
Les fonctionnalités sont faiblement couplées et peuvent évoluer indépendamment
Directives pour l'organisation des fonctionnalités
En théorie, chaque fonctionnalité est déployable de manière indépendante. Bien que nous ne les déployions peut-être pas séparément, l'organisation de cette manière nous oblige à garder des dépendances claires et un couplage minimal. C'est le principe et le succès des microservices, bien que nous ne déploierons pas encore de microservices.
Les fonctionnalités communiquent par le biais d'interfaces bien définies. Si les réservations ont besoin de données de disponibilité, elles importent depuis @calcom/features/availability via des interfaces exportées, et non en accédant aux détails de mise en œuvre internes.
Le code partagé se trouve aux endroits appropriés :
Utilitaires indépendants du domaine et préoccupations transversales (authentification, journalisation) :
packages/libPrimitives UI partagées :
packages/ui(et bientôt coss.com ui)
Les limites du domaine sont appliquées automatiquement. Nous allons construire un linting qui empêche d'accéder aux internes des features là où vous ne devriez pas être autorisé. Si packages/features/bookings essaie d'importer depuis packages/features/availability/services/internal, le linter le bloquera. Toutes les dépendances inter-features doivent passer par l'API publique de la feature.
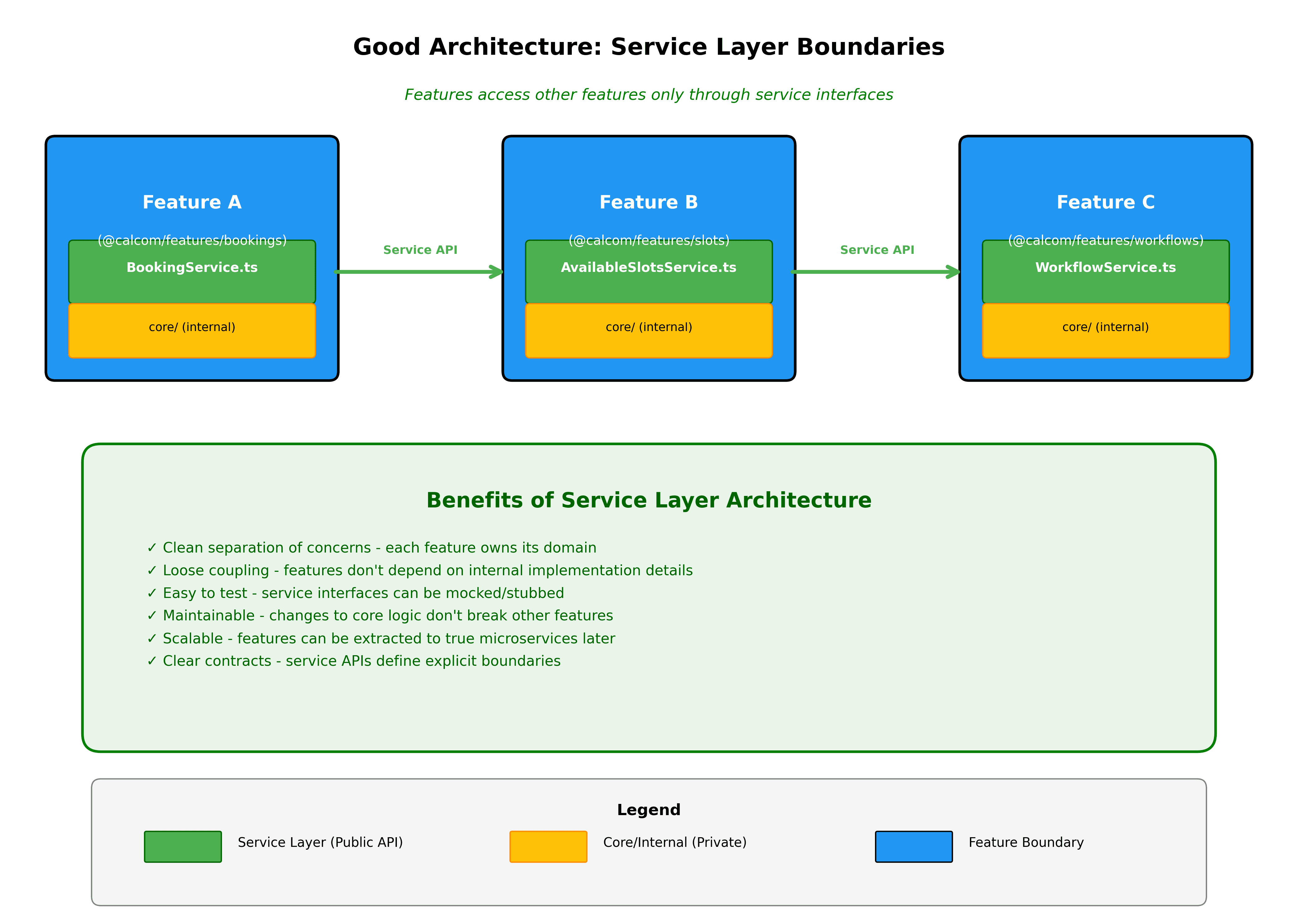
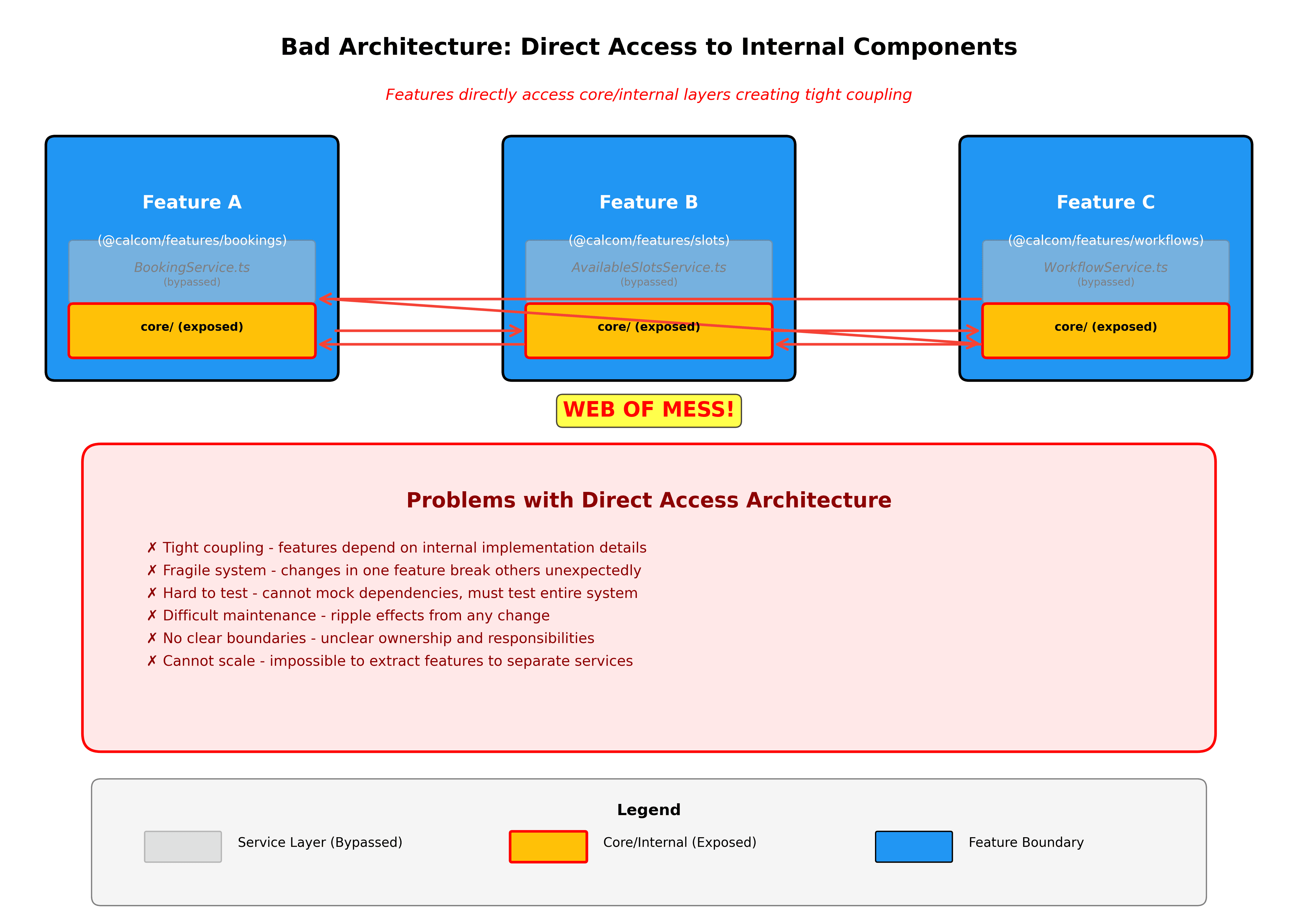
Les nouvelles fonctionnalités commencent comme des slices verticales. Lors de la création de quelque chose de nouveau, créez un nouveau dossier dans packages/features avec la slice verticale complète. Cela le rend clair sur ce que vous construisez et garde tout organisé dès le premier jour.
Avantages
Discoverabilité
Vous cherchez la logique de réservation ? Tout est dans
packages/features/bookings. Pas besoin de chercher à travers des contrôleurs, services, dépôts et utilitaires dispersés dans la base de code.
Tests plus faciles
Testez l'ensemble de la fonctionnalité comme une unité. Vous avez toutes les pièces en un seul endroit, ce qui rend les tests d'intégration naturels et simples.
Dépendances plus claires
Lorsque vous voyez
import { getAvailability } from '@calcom/features/availability', vous savez exactement sur quelle feature vous dépendez. Lorsque les dépendances deviennent trop complexes, c'est évident et peut être traité.
Patron de Répértoire et Injection de Dépendance
Les choix technologiques ne doivent pas transparaître dans l'application. Le problème de Prisma l'illustre parfaitement. Nous avons actuellement des références à Prisma dispersées sur des centaines de fichiers. Cela crée un couplage massif et rend les changements technologiques prohibitivement coûteux. Nous ressentons maintenant la douleur de cela pour la mise à niveau de Prisma en v6.16. Ce qui aurait dû être juste un refactoring localisé derrière des dépôts protégés a été une poursuite sans fin et sinueuse de problèmes à travers plusieurs applications.
La norme à partir de maintenant :
Toutes les accès à la base de données doivent passer par des classes de Répertoire. Nous avons déjà une belle avance sur cela.
Les dépôts sont le seul code qui connaisse Prisma (ou tout autre ORM). Aucune logique ne devrait être présente en eux.
Les dépôts sont injectés via des conteneurs Injection de Dépendance (DI)
Si nous devons passer de Prisma à Drizzle ou un autre ORM, les seuls changements requis sont :
Mises en œuvre des dépôts
Câblage du conteneur DI pour les nouveaux dépôts
Rien d'autre dans la base de code ne devrait s'en préoccuper ou changer
Ce n'est pas théorique. C'est comme ça que nous construisons des systèmes maintenables.
Objets de Transfert de Données (DTOs)
Les types de base de données ne devraient pas fuir vers le frontend. Cela est devenu un raccourci populaire dans notre pile technologique, mais c'est une odeur de code qui crée plusieurs problèmes.
Couplage technologique (les types Prisma finissent dans les composants React)
Risques sécuritaires (fuite accidentelle de champs sensibles)
Contrats fragiles entre le serveur et le client (cela est particulièrement problématique à mesure que nous construisons de nombreuses API supplémentaires)
Impossibilité de faire évoluer le schéma de base de données de manière indépendante
Toutes les conversions DTOs via Zod, même pour une réponse API pour s'assurer que toutes les données sont validées avant d'être envoyées à l'utilisateur. Mieux vaut échouer que retourner quelque chose de faux.
La norme à partir de maintenant :
Créer des DTOs explicites à chaque frontière architecturale.
Couche Données → Couche Application → API: Transformer les modèles de base de données en DTOs de niveau application, puis transformer les DTOs de l'application en DTOs spécifiques à l'API
API → Couche Application → Couche Données: Transformer les DTOs de l'API par l'application et aux DTOs spécifiques aux données
Oui, cela nécessite plus de code. Oui, cela en vaut la peine. Les frontières explicites empêchent l'érosion architecturale qui crée des cauchemars de maintenance à long terme.
Patrons de Conception Pilotée par le Domaine
Les patrons suivants doivent être utilisés correctement et de manière cohérente :
Services d'application
Orchestrer les cas d'utilisation, coordonner entre les services de domaine et les dépôts
Services de domaine
Contenir la logique professionnelle qui n'appartient pas naturellement à une seule entité
Répertoires
Abstraire l'accès aux données, isoler les choix technologiques
Injection de Dépendance
Permettre le couplage lâche, faciliter les tests, isoler les préoccupations
Proxies de mise en cache
Emballer les dépôts ou services pour ajouter un comportement de mise en cache de manière transparente
Pas le seul moyen de faire de la mise en cache, bien sûr, mais un bon point de départ
Décorateurs
Ajouter des préoccupations transversales (journalisation, métriques, etc.) sans polluer la logique de domaine
Consistance de la base de code
Nos bases de code devraient donner l'impression qu' une seule personne les a écrites. Ce niveau de consistance nécessite une adhérence stricte aux modèles établis, des règles de linting complètes qui imposent des normes architecturales, des revues de code qui rejettent les violations de modèle + l'aide des relecteurs de code AI.
Déplacer les conditionnels au point d'entrée de l'application
Les instructions if appartiennent au point d'entrée, pas dispersées dans vos services. C'est l'un des principes architecturaux les plus importants pour maintenir un code propre et concentré qui ne se transforme pas en complexité insurmontable.
Voici comment le code se dégrade au fil du temps : Un service est écrit dans un but clair et spécifique. La logique est propre et concentrée. Ensuite, une nouvelle exigence de produit arrive, et quelqu'un ajoute une instruction if. Quelques années et plusieurs exigences plus tard, ce service est truffé de vérifications conditionnelles pour différents scénarios. Le service est devenu :
Compliqué et difficile à lire
Difficile à comprendre et à appréhender
Plus susceptible aux bugs
Violer la responsabilité unique (gérer trop de cas différents)
Presque impossible à tester complètement
Le service a outrepassé ses limites en termes de responsabilités et de logique.
Une solution : le patron de fabrique avec des services spécialisés
Utilisez le patron de fabrique pour prendre des décisions au point d'entrée, puis déléguez à des services spécialisés qui gèrent leur logique spécifique sans conditionnels.
Exemple tiré de notre codebase :
La BillingPortalServiceFactory détermine si la facturation est pour une organisation, une équipe, ou un utilisateur individuel, puis retourne le service approprié :
Chaque service gère ensuite sa logique spécifique sans besoin de vérifier "suis-je une organisation ou une équipe ?":
Pourquoi cela importe
Les services restent concentrés
Chaque service a une responsabilité unique et n'a pas besoin de connaître d'autres contextes. Le
OrganizationBillingPortalServicene contient pas des if vérifiantif (isTeam)ouif (isUser). Il ne sait gérer que les organisations.
Les modifications sont isolées
Lorsque vous devez modifier la logique de facturation de l'organisation, vous ne touchez que
OrganizationBillingPortalService. Vous ne risquez pas de casser la facturation d'équipe ou d'utilisateur. Vous n'avez pas besoin de suivre à travers des conditionnels imbriqués pour découvrir quel chemin votre code prend.
Les tests sont simples
Testez chaque service indépendamment avec ses scénarios spécifiques. Pas besoin de tester chaque combinaison de conditionnels à travers des contextes différents.
Les nouvelles exigences ne polluent pas le code existant
par exemple, lorsque vous devez ajouter une facturation d'entreprise avec des règles différentes, vous créez
EnterpriseBillingPortalService. La fabrique gagne un conditionnel de plus, mais les services existants restent intacts et concentrés.
Comment y parvenir
Poussez les conditionnels vers les contrôleurs, les fabriques ou la logique de routage. Laissez ces points d'entrée décider du service à utiliser.
Laissez les services purs et concentrés sur une seule responsabilité. Si un service a besoin de vérifier "quel type suis-je ?", vous avez probablement besoin de plusieurs services.
Préférez le polymorphisme aux conditionnels
Les interfaces définissent le contrat. Les mises en œuvre concrètes fournissent les spécificités.
Surveillez l'accumulation des instructions if
Lors de la revue de code, si vous voyez un service gagner des conditionnels pour différents scénarios, c'est un signal pour refactorer en services spécialisés.
Conception d'API : Contrôleurs fins et Abstraction HTTP
Les contrôleurs sont des couches fines qui ne gèrent que les préoccupations HTTP.
Ils reçoivent les demandes, les traitent, et mappent les données en DTOs qui sont passés à la logique d'application de base. À l'avenir, aucune logique d'application ou de base ne devrait être vue dans les routes d'API ou les gestionnaires tRPC.
Nous devons détacher la technologie HTTP de notre application.
La façon dont nous transférons les données entre le client et le serveur (qu'il s'agisse de REST, tRPC, etc.) ne devrait pas influencer la manière dont notre application de base fonctionne. HTTP est un mécanisme de livraison, pas un moteur architectural.
Responsabilités des contrôleurs (et SEULEMENT celles-ci) :
Recevoir et valider les demandes entrantes
Extraire les données des paramètres de la demande, du corps, des en-têtes
Transformer les données de la demande en DTOs
Appeler les services d'application appropriés avec ces DTOs
Transformer les réponses des services d'application en DTOs de réponse
Retourner des réponses HTTP avec des codes de statut appropriés
Les contrôleurs ne doivent PAS :
Contenir de la logique métier ou des règles de domaine
Accéder directement à des bases de données ou à des services externes
Effectuer des transformations de données complexes ou des calculs
Prendre des décisions sur ce que l'application devrait faire
Connaître les détails d'implémentation du domaine
Exemple de patron de contrôleur fin :
Versionnage d'API et Modifications Casseuses
Aucune modification cassante. C'est essentiel. Une fois qu'un point d'accès API est publique, il doit rester stable. Les modifications cassantes détruisent la confiance des développeurs et créent des cauchemars d'intégration pour nos utilisateurs.
Stratégies pour éviter les modifications cassantes :
Ajoutez toujours de nouveaux champs comme optionnels
Utilisez le versionnage de l'API lorsque vous devez changer le comportement existant
Dépréciez les anciens points de terminaison gracieusement avec des chemins de migration clairs
Maintenez la rétrocompatibilité pour au moins deux versions majeures
Lorsque vous devez apporter des modifications cassantes :
Créez une nouvelle version d'API en utilisant le versionning basé sur la date dans l'API v2 (peut-être allons-nous également étudier le versionning nommé que Stripe a récemment introduit)
Exécutez les deux versions simultanément pendant la transition (nous le faisons déjà dans l'API v2)
Fournissez des outils de migration automatisés lorsque cela est possible
Laissez aux utilisateurs le temps de migrer (minimum 6 mois pour les API publiques)
Documentez exactement ce qui a changé et pourquoi
Performance et Complexité Algoritmique
Nous construisons pour les grandes organisations et équipes. Ce qui fonctionne bien avec 10 utilisateurs ou 50 enregistrements peut s'effondrer sous la charge de l'échelle d'entreprise. La performance n'est pas quelque chose que nous optimisons plus tard. C'est quelque chose que nous construisons correctement dès le départ.
Pensez à l'échelle dès le premier jour
Lorsque vous construisez des fonctionnalités, demandez toujours : "Comment cela se comporte-t-il avec 1 000 utilisateurs ? 10 000 enregistrements ? 100 000 opérations ?" La différence entre les algorithmes O(n) et O(n²) peut être imperceptible en développement, mais catastrophique en production.
Modèles courants O(n²) à éviter :
Itérations de tableau imbriquées (
.mapà l'intérieur de.map,.forEachà l'intérieur de.forEach)Méthodes de tableau comme
.some,.find, ou.filterdans des boucles ou des callbacksVérification de chaque élément contre chaque autre élément sans optimisation
Filtres enchaînés ou mappage imbriqué sur de grandes listes
Exemple réel : Pour 100 créneaux disponibles et 50 périodes occupées, un algorithme O(n²) effectue 5 000 vérifications. Augmentez cela à 500 créneaux et 200 périodes occupées, et vous effectuez 100 000 opérations. Cela équivaut à une augmentation de 20x de la charge computationnelle pour seulement une augmentation de 5x des données.
Choisissez les bonnes structures de données et algorithmes
La plupart des problèmes de performance sont résolus en choisissant de meilleures structures de données et algorithmes :
Tri + sortie anticipée: Triez vos données une fois, puis sortez des boucles lorsque vous savez que les éléments restants ne correspondront pas
Recherche binaire: Utilisez la recherche binaire pour les recherches dans les tableaux triés au lieu des analyses linéaires
Techniques à deux pointeurs: Pour la fusion ou l'intersection de séquences triées, parcourez les deux avec des pointeurs au lieu de boucles imbriquées
Tableaux de hachage/ensembles: Utilisez des objets ou des ensembles pour des recherches O(1) au lieu de
.findou.includessur des tableauxArbres intervalle: Pour la planification, la disponibilité et les requêtes de plage, utilisez des structures d'arbre appropriées au lieu de la comparaison brute
Exemple de transformation :
Vérifications automatiques des performances
Nous allons mettre en place plusieurs couches de défense contre les régressions de performance :
Règles de linting qui signalent :
Fonctions avec des boucles imbriquées ou des méthodes de tableaux imbriquées
Appels imbriqués multiples de
.some,.find, ou.filterRécursion sans mémoïsation
Anti-patrons connus pour notre domaine (planification, vérification de disponibilité, etc.)
Bancs d'essai de performance dans CI qui :
Exécutent des algorithmes critiques sur des données réalistes et à grande échelle
Comparent les temps d'exécution par rapport à la ligne de base pour chaque PR
Bloquent les fusions qui introduisent des régressions de performance
Testent avec des données à l'échelle des entreprises (milliers d'utilisateurs, dizaines de milliers d'enregistrements)
Surveillance en production qui :
Suit le temps d'exécution des chemins critiques
Envoie des alertes lorsque les algorithmes ralentissent à mesure que les données augmentent
Attrape les régressions avant que les utilisateurs ne le remarquent
Fournit des données de performance du monde réel pour informer les optimisations
La performance est une fonctionnalité
La performance n'est pas optionnelle. Ce n'est pas quelque chose que nous "réglons plus tard." Pour les clients d'entreprise réservant dans de grandes équipes, des réponses lentes signifient une productivité perdue et des utilisateurs frustrés (notre expérience avec certains grands clients d'entreprise peut en témoigner).
Chaque ingénieur devrait :
Profiler votre code avant d'optimiser, mais pensez à la complexité dès le début
Tester avec des données réalistes et à grande échelle (pas seulement 5 enregistrements de test). Nous avons déjà construit des scripts de semis. Nous devons probablement les étendre.
Choisissez des algorithmes efficaces et des structures de données dès le départ
Surveillez les itérations imbriquées lors de la revue de code
Remettez en question tout algorithme qui s'ajuste avec le produit de deux variables
La réalité NP-difficile de la planification
Les problèmes de planification sont fondamentalement NP-difficiles. Cela signifie que lorsque le nombre de contraintes, de participants ou de créneaux horaires augmente, la complexité computationnelle peut exploser exponentiellement. La plupart des algorithmes de planification optimaux ont une complexité temporelle exponentielle dans le pire des cas, rendant le choix de l'algorithme absolument crucial.
Implications réelles :
Trouver le bon moment de réunion pour 10 personnes dans 3 fuseaux horaires avec des contraintes de disponibilité individuelles est computationnellement coûteux
Ajouter la détection des conflits, les tampons, et une pléthore d'autres options amplifie le problème
Mauvais choix d'algorithmes qui fonctionnent bien pour les petites équipes deviennent complètement inutilisables pour les grandes organisations
Ce qui prend des millisecondes pour 5 utilisateurs pourrait prendre des secondes entières pour des organisations
Stratégies pour gérer la complexité NP-difficile :
Utilisez des algorithmes d'approximation qui trouvent des solutions "assez bonnes" rapidement plutôt que des solutions parfaites lentement
Implémentez une mise en cache agressive des emplois du temps et de la disponibilité calculés
Pré-calculer des scénarios courants pendant les heures creuses
Fragmenter les grands problèmes de planification en morceaux plus petits et plus maniables
Définir des limites raisonnables de temps d'exécution et revenir à des algorithmes plus simples si nécessaire
C'est pourquoi la performance n'est pas simplement un bel ajout dans les logiciels de planification. C'est la base qui détermine si votre système peut s'étendre aux besoins d'entreprise ou s'effondrer sous les modèles d'utilisation du monde réel.
Exigences de couverture de code
Suivi de couverture globale
Nous suivons la couverture globale de la base de code comme une métrique clé qui s'améliore avec le temps. Cela nous donne une visibilité sur notre maturité de test et aide à identifier les domaines qui nécessitent de l'attention. Le pourcentage de couverture globale est affiché de manière visible dans nos tableaux de bord.
Couverture de 80 % + pour le nouveau code
Chaque PR doit avoir une couverture de test proche de 80 % pour le code qu'il introduit ou modifie. Cela est appliqué automatiquement dans notre pipeline CI. Si vous ajoutez 50 lignes de nouveau code, ces 50 lignes doivent être couvertes par des tests. Si vous modifiez une fonction existante, vos changements doivent être testés. C'est une couverture de test en général. La couverture de test unitaire doit être proche de 100 %, surtout avec la possibilité de tirer parti de l'IA pour aider à générer ceux-ci.
Répondant à l'argument "la couverture n'est pas toute l'histoire" : Oui, nous savons que la couverture ne garantit pas des tests parfaits. Nous savons que vous pouvez écrire des tests insignifiants qui atteignent chaque ligne mais ne testent rien de significatif. Nous savons que la couverture n'est qu'une métrique parmi beaucoup d'autres. Mais il vaut certainement mieux viser un pourcentage élevé que de ne pas savoir où vous vous trouvez du tout.
Mesurer le succès
"Vélocité" (volé au Scrum bien que nous ne l'utiliserons pas)
Croissance continue des stats mensuelles (fonctionnalités, améliorations, refontes)
Qualité
Réduire l'effort de PR sur les corrections de 35 % actuellement à 20 % ou moins d'ici fin 2026 (calculé en fonction des modifications de fichiers et des ajouts/suppressions)
Santé architecturale
Métriques sur l'adhésion aux standards de design, couplage technologique, violations de limites
Efficacité des revues
PRs plus petits, revues plus rapides, moins de tours de rétroaction
Disponibilité de l'application et de l'API
À quel point sommes-nous proches de 99,99 % ?

Commencez avec Cal.com gratuitement dès aujourd'hui !
Découvrez une planification et une productivité sans faille sans frais cachés. Inscrivez-vous en quelques secondes et commencez à simplifier votre planification dès aujourd'hui, sans carte de crédit requise !



