" height="18.016311920580208px" id="GKXyVanMq" stroke-dasharray="0" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgb(0, 0, 0)" transform="translate(3 3)" width="18px"/></svg>)
"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient><linearGradient id="CBS1bzkxF-2031533640-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgb(255, 255, 255)"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient><linearGradient id="Jd7AK81w9-2031533640-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgb(255, 255, 255)"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient></defs><g d="M 0 16 L 0 0 L 16 0 L 16 16 Z M 9.167 5.167 C 9.167 4.891 8.943 4.667 8.667 4.667 C 8.391 4.667 8.167 4.891 8.167 5.167 C 8.167 6.784 7.809 7.834 7.155 8.488 C 6.501 9.143 5.451 9.5 3.833 9.5 C 3.557 9.5 3.333 9.724 3.333 10 C 3.333 10.276 3.557 10.5 3.833 10.5 C 5.451 10.5 6.501 10.857 7.155 11.512 C 7.809 12.166 8.167 13.216 8.167 14.833 C 8.167 15.109 8.391 15.333 8.667 15.333 C 8.943 15.333 9.167 15.109 9.167 14.833 C 9.167 13.216 9.524 12.166 10.178 11.512 C 10.832 10.857 11.883 10.5 13.5 10.5 C 13.776 10.5 14 10.276 14 10 C 14 9.724 13.776 9.5 13.5 9.5 C 11.883 9.5 10.832 9.143 10.178 8.488 C 9.524 7.834 9.167 6.784 9.167 5.167 Z M 4 3.667 C 4 3.483 3.851 3.333 3.667 3.333 C 3.483 3.333 3.333 3.483 3.333 3.667 C 3.333 4.32 3.189 4.715 2.952 4.952 C 2.715 5.189 2.32 5.333 1.667 5.333 C 1.483 5.333 1.333 5.483 1.333 5.667 C 1.333 5.851 1.483 6 1.667 6 C 2.32 6 2.715 6.145 2.952 6.382 C 3.189 6.618 3.333 7.013 3.333 7.667 C 3.333 7.851 3.483 8 3.667 8 C 3.851 8 4 7.851 4 7.667 C 4 7.013 4.145 6.618 4.382 6.382 C 4.618 6.145 5.013 6 5.667 6 C 5.851 6 6 5.851 6 5.667 C 6 5.483 5.851 5.333 5.667 5.333 C 5.013 5.333 4.618 5.189 4.382 4.952 C 4.145 4.715 4 4.32 4 3.667 Z M 7.333 1 C 7.333 0.816 7.184 0.667 7 0.667 C 6.816 0.667 6.667 0.816 6.667 1 C 6.667 1.422 6.573 1.65 6.445 1.778 C 6.317 1.906 6.089 2 5.667 2 C 5.483 2 5.333 2.149 5.333 2.333 C 5.333 2.517 5.483 2.667 5.667 2.667 C 6.089 2.667 6.317 2.761 6.445 2.889 C 6.573 3.016 6.667 3.244 6.667 3.667 C 6.667 3.851 6.816 4 7 4 C 7.184 4 7.333 3.851 7.333 3.667 C 7.333 3.244 7.427 3.016 7.555 2.889 C 7.683 2.761 7.911 2.667 8.333 2.667 C 8.517 2.667 8.667 2.517 8.667 2.333 C 8.667 2.149 8.517 2 8.333 2 C 7.911 2 7.683 1.906 7.555 1.778 C 7.427 1.65 7.333 1.422 7.333 1 Z" fill="transparent" height="16px" id="aoZYv33vR" width="16px"><path d="M 0 16 L 0 0 L 16 0 L 16 16 Z" fill="transparent" height="16px" id="Z2uGmhW9f" width="16px"/><g d="M 7.833 4.5 C 7.833 4.224 7.609 4 7.333 4 C 7.057 4 6.833 4.224 6.833 4.5 C 6.833 6.117 6.476 7.168 5.822 7.822 C 5.168 8.476 4.117 8.833 2.5 8.833 C 2.224 8.833 2 9.057 2 9.333 C 2 9.61 2.224 9.833 2.5 9.833 C 4.117 9.833 5.168 10.191 5.822 10.845 C 6.476 11.499 6.833 12.549 6.833 14.167 C 6.833 14.443 7.057 14.667 7.333 14.667 C 7.609 14.667 7.833 14.443 7.833 14.167 C 7.833 12.549 8.191 11.499 8.845 10.845 C 9.499 10.191 10.549 9.833 12.167 9.833 C 12.443 9.833 12.667 9.61 12.667 9.333 C 12.667 9.057 12.443 8.833 12.167 8.833 C 10.549 8.833 9.499 8.476 8.845 7.822 C 8.191 7.168 7.833 6.117 7.833 4.5 Z M 2.667 3 C 2.667 2.816 2.517 2.667 2.333 2.667 C 2.149 2.667 2 2.816 2 3 C 2 3.654 1.855 4.048 1.618 4.285 C 1.382 4.522 0.987 4.667 0.333 4.667 C 0.149 4.667 0 4.816 0 5 C 0 5.184 0.149 5.333 0.333 5.333 C 0.987 5.333 1.382 5.478 1.618 5.715 C 1.855 5.952 2 6.346 2 7 C 2 7.184 2.149 7.333 2.333 7.333 C 2.517 7.333 2.667 7.184 2.667 7 C 2.667 6.346 2.811 5.952 3.048 5.715 C 3.285 5.478 3.68 5.333 4.333 5.333 C 4.517 5.333 4.667 5.184 4.667 5 C 4.667 4.816 4.517 4.667 4.333 4.667 C 3.68 4.667 3.285 4.522 3.048 4.285 C 2.811 4.048 2.667 3.654 2.667 3 Z M 6 0.333 C 6 0.149 5.851 0 5.667 0 C 5.483 0 5.333 0.149 5.333 0.333 C 5.333 0.756 5.239 0.984 5.112 1.112 C 4.984 1.239 4.756 1.333 4.333 1.333 C 4.149 1.333 4 1.483 4 1.667 C 4 1.851 4.149 2 4.333 2 C 4.756 2 4.984 2.094 5.112 2.222 C 5.239 2.35 5.333 2.578 5.333 3 C 5.333 3.184 5.483 3.333 5.667 3.333 C 5.851 3.333 6 3.184 6 3 C 6 2.578 6.094 2.35 6.222 2.222 C 6.35 2.094 6.578 2 7 2 C 7.184 2 7.333 1.851 7.333 1.667 C 7.333 1.483 7.184 1.333 7 1.333 C 6.578 1.333 6.35 1.239 6.222 1.112 C 6.094 0.984 6 0.756 6 0.333 Z" fill="transparent" height="14.66671286102295px" id="ae6ccdFme" transform="translate(1.333 0.667)" width="12.66663px"><path d="M 5.833 0.5 C 5.833 0.224 5.609 0 5.333 0 C 5.057 0 4.833 0.224 4.833 0.5 C 4.833 2.117 4.476 3.168 3.822 3.822 C 3.168 4.476 2.117 4.833 0.5 4.833 C 0.224 4.833 0 5.057 0 5.333 C 0 5.61 0.224 5.833 0.5 5.833 C 2.117 5.833 3.168 6.191 3.822 6.845 C 4.476 7.499 4.833 8.549 4.833 10.167 C 4.833 10.443 5.057 10.667 5.333 10.667 C 5.609 10.667 5.833 10.443 5.833 10.167 C 5.833 8.549 6.191 7.499 6.845 6.845 C 7.499 6.191 8.549 5.833 10.167 5.833 C 10.443 5.833 10.667 5.61 10.667 5.333 C 10.667 5.057 10.443 4.833 10.167 4.833 C 8.549 4.833 7.499 4.476 6.845 3.822 C 6.191 3.168 5.833 2.117 5.833 0.5 Z" fill="url(%23t2lXByE48-2031533640-linear-gradient)" height="10.66671px" id="t2lXByE48" transform="translate(2 4)" width="10.66663px"/><path d="M 2.667 0.333 C 2.667 0.149 2.517 0 2.333 0 C 2.149 0 2 0.149 2 0.333 C 2 0.987 1.855 1.382 1.618 1.618 C 1.382 1.855 0.987 2 0.333 2 C 0.149 2 0 2.149 0 2.333 C 0 2.517 0.149 2.667 0.333 2.667 C 0.987 2.667 1.382 2.811 1.618 3.048 C 1.855 3.285 2 3.68 2 4.333 C 2 4.517 2.149 4.667 2.333 4.667 C 2.517 4.667 2.667 4.517 2.667 4.333 C 2.667 3.68 2.811 3.285 3.048 3.048 C 3.285 2.811 3.68 2.667 4.333 2.667 C 4.517 2.667 4.667 2.517 4.667 2.333 C 4.667 2.149 4.517 2 4.333 2 C 3.68 2 3.285 1.855 3.048 1.618 C 2.811 1.382 2.667 0.987 2.667 0.333 Z" fill="url(%23CBS1bzkxF-2031533640-linear-gradient)" height="4.66667px" id="CBS1bzkxF" transform="translate(0 2.667)" width="4.66667px"/><path d="M 2 0.333 C 2 0.149 1.851 0 1.667 0 C 1.483 0 1.333 0.149 1.333 0.333 C 1.333 0.756 1.239 0.984 1.112 1.112 C 0.984 1.239 0.756 1.333 0.333 1.333 C 0.149 1.333 0 1.483 0 1.667 C 0 1.851 0.149 2 0.333 2 C 0.756 2 0.984 2.094 1.112 2.222 C 1.239 2.35 1.333 2.578 1.333 3 C 1.333 3.184 1.483 3.333 1.667 3.333 C 1.851 3.333 2 3.184 2 3 C 2 2.578 2.094 2.35 2.222 2.222 C 2.35 2.094 2.578 2 3 2 C 3.184 2 3.333 1.851 3.333 1.667 C 3.333 1.483 3.184 1.333 3 1.333 C 2.578 1.333 2.35 1.239 2.222 1.112 C 2.094 0.984 2 0.756 2 0.333 Z" fill="url(%23Jd7AK81w9-2031533640-linear-gradient)" height="3.333333px" id="Jd7AK81w9" transform="translate(4 0)" width="3.3333399999999997px"/></g></g></svg>)
" height="24px" id="WCm44spAV" width="24px"/><path d="M 3.892 7.742 C 1.674 7.742 0 6.014 0 3.882 C 0 1.738 1.589 0 3.892 0 C 5.107 0 5.951 0.374 6.623 1.173 L 5.566 2.09 C 5.118 1.621 4.564 1.386 3.892 1.386 C 2.452 1.386 1.547 2.517 1.547 3.882 C 1.547 5.246 2.452 6.356 3.924 6.356 C 4.649 6.356 5.193 6.111 5.63 5.63 L 6.718 6.558 C 6.153 7.24 5.193 7.742 3.892 7.742 Z" fill="rgb(255, 255, 255)" height="7.741500000000002px" id="XEPpGD7l5" transform="translate(4 8.25)" width="6.717999999999989px"/><path d="M 2.74 7.922 C 1.215 7.922 0 6.632 0 5.032 C 0 3.433 1.215 2.122 2.74 2.122 C 3.7 2.122 4.201 2.516 4.5 3.113 L 4.5 2.239 L 5.928 2.239 L 5.928 7.784 L 4.531 7.784 L 4.531 6.877 C 4.233 7.507 3.731 7.922 2.74 7.922 Z M 1.439 5.023 C 1.439 5.865 2.057 6.622 2.975 6.622 C 3.924 6.622 4.531 5.897 4.531 5.033 C 4.531 4.169 3.924 3.423 2.975 3.423 C 2.057 3.423 1.439 4.159 1.439 5.022 Z M 6.784 7.784 L 6.784 0 L 8.224 0 L 8.224 7.784 L 6.784 7.784 Z" fill="rgb(255, 255, 255)" height="7.9224997406005855px" id="lGDJupIUR" transform="translate(10.5 8)" width="8.223500194549558px"/></g></svg>)
" width="18px"><path d="M 2 8 C 0.895 8 0 7.105 0 6 L 0 2 C 0 0.895 0.895 0 2 0 L 6 0 C 7.105 0 8 0.895 8 2 L 8 6 C 8 7.105 7.105 8 6 8 Z" fill="transparent" height="8px" id="ZrCrI93dV" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" width="8px"/><path d="M 0 0 L 0 4 C 0 5.105 0.895 6 2 6 L 6 6" fill="transparent" height="6px" id="emltWYAiE" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" transform="translate(4 8)" width="6px"/><path d="M 2 8 C 0.895 8 0 7.105 0 6 L 0 2 C 0 0.895 0.895 0 2 0 L 6 0 C 7.105 0 8 0.895 8 2 L 8 6 C 8 7.105 7.105 8 6 8 Z" fill="transparent" height="8px" id="WpBecYDfi" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" transform="translate(10 10)" width="8px"/></g></svg>)

Revue de l'incident : charge de la base de données, défaillances en cascade et ce que nous avons appris - 27 janvier 2026
Le mardi 27 janvier, nous avons connu un incident de production qui a causé une dégradation des performances sur la plateforme et un temps d'arrêt complet pour certains clients entreprise ayant des types d'événements à fort volume.
L'incident a commencé par une charge élevée de la base de données, semblait résolu, puis a révélé des pannes secondaires dans les systèmes en aval. Cet article explique ce qui s'est passé, comment nous l'avons confirmé et ce que nous avons changé en conséquence.

Impact
Les utilisateurs à faible volume ont rencontré une latence élevée et des temps de chargement de page lents
Les clients d'entreprise avec des types d'événements lourds ont connu des délais d'attente et des temps d'arrêt
Plus tard dans l'incident, les utilisateurs ayant des intégrations avec Google Calendar ont constaté des défaillances intermittentes
Ce que nous avons vu en premier
À 15h30 UTC, des alertes automatiques ont été déclenchées en raison d'une charge de base de données élevée. Une première enquête a montré une augmentation des sessions actives moyennes (AAS) et une latence des déclarations en forte hausse, tandis que le trafic global restait dans des limites attendues.
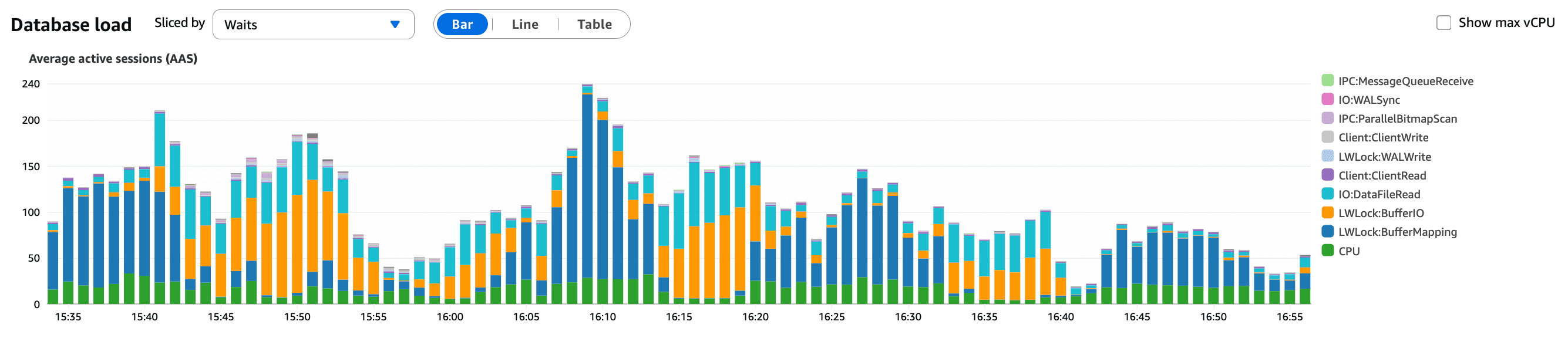
Ce que ce graphique montre :
Une augmentation soutenue des sessions actives de la base de données
Des sessions s'accumulant plutôt que de se terminer rapidement
Un signal fort que les requêtes devenaient plus lentes, et non que le trafic avait augmenté
Cela a suggéré un changement dans notre application plutôt qu'une augmentation de trafic, ce que l'analyse de trafic a confirmé.
La saturation du CPU confirme le goulet d'étranglement
À mesure que la charge augmentait, l'utilisation du CPU de la base de données augmentait également.
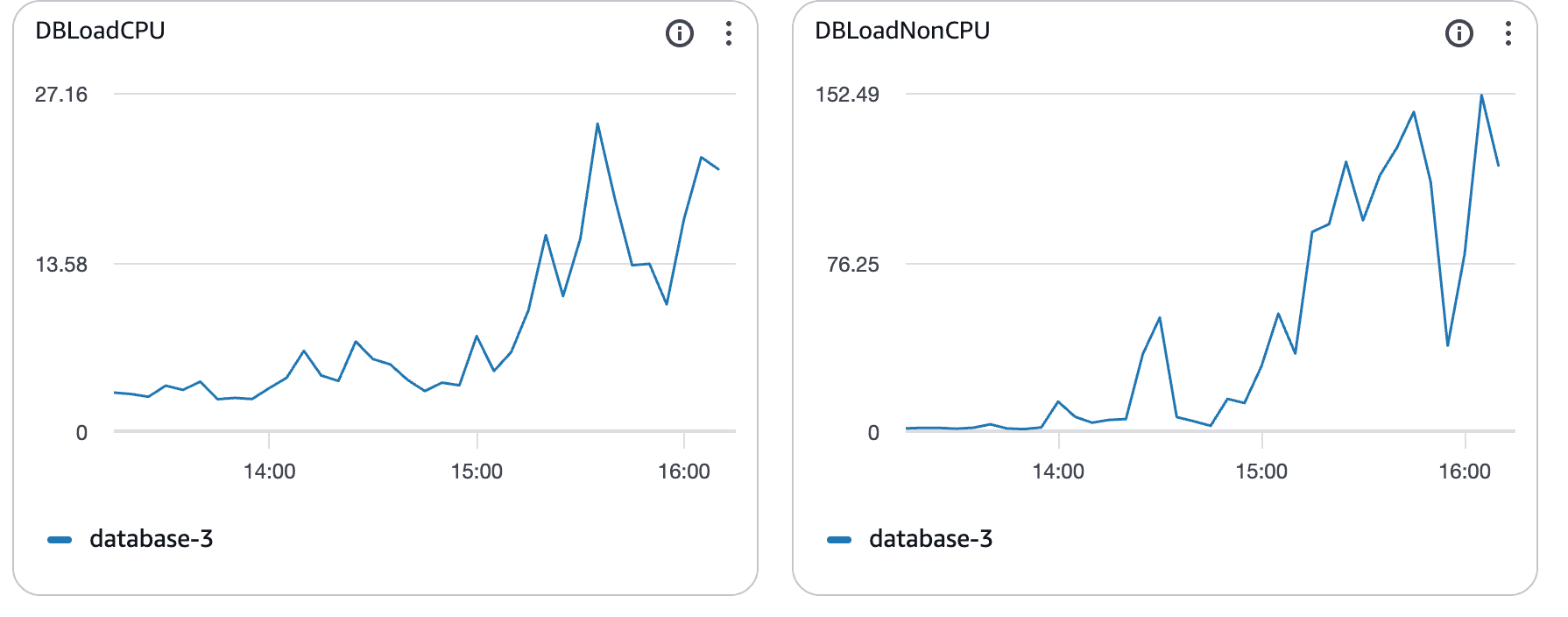
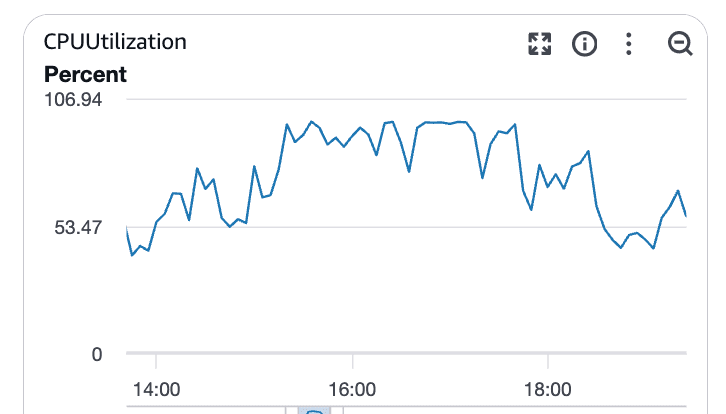
Ce que ces graphiques montrent :
L'utilisation du CPU dépassant largement la référence
Saturation soutenue plutôt que pics courts
Corrélation claire avec la latence des requêtes en augmentation
À ce stade, Postgres était limité par le CPU. Les requêtes prenaient plus de temps, bloquaient d'autres, et la latence se répandait dans le système.
Chronologie (UTC)
15h30 – Alertes automatiques pour charge élevée de la base de données. Les diagnostics initiaux ont montré une activité
DELETEélevée sur APIv2.15h49 – Nous avons renforcé les limites de taux de
DELETEpour réduire la pression immédiate.16h03 – Une enquête plus approfondie a montré que le trafic était normal. La charge sur la base de données continuait d'augmenter.
16h06 – Premiers rapports de clients d'entreprise incapables de charger des types d'événements.
16h18 – Incident déclaré. La saturation du CPU a causé une augmentation de la latence des déclarations dans tout le système.
17h07 – Nous avons commencé à réécrire une requête à charge élevée pour réduire la pression sur la base de données.
17h40 – Réécriture de requête déployée. Cela a aidé, mais n'a pas entièrement résolu le problème.
Le moment décisif
À 17h45, nous avons identifié une interaction imprévue :
Une fonctionnalité récemment publiée le lundi 26 a introduit la recherche de réservation dans KBar (CMD+K). Cela a entraîné un appel API lourd sur chaque chargement de page dans l'application web.
À 17h55, le changement de KBar a été annulé en production.
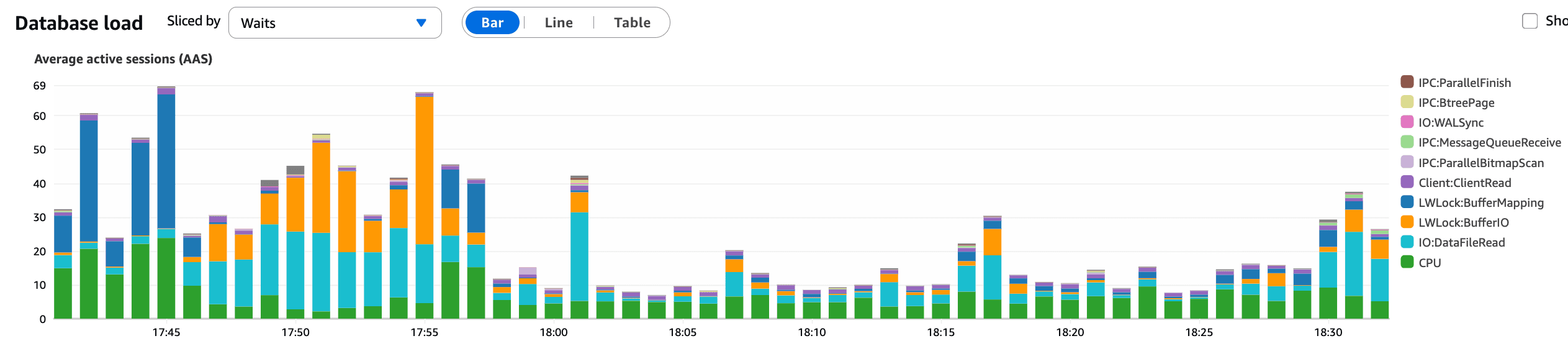
Ce que ce graphique confirme :
Une chute claire et immédiate des AAS après l'annulation
Pression de requête sur la base de données réduite
Latence se stabilisant peu après
Cela coïncide précisément avec le timing de l'annulation et a confirmé que l'interaction avec KBar était le principal déclencheur de l'incident de base de données.
18h15 – Performance de la base de données stabilisée.
L'incident principal de la base de données a été résolu à ce moment-là.
Problèmes secondaires dévoilés
Après la récupération de la base de données, un sous-ensemble plus petit d'utilisateurs est resté affecté.
Les utilisateurs avec des intégrations Google Calendar ont rencontré des défaillances à cause de l'épuisement du quota de l'API Google. Cela a été causé par un comportement de réessaie à travers plusieurs consommateurs pendant que des erreurs en amont se produisaient.
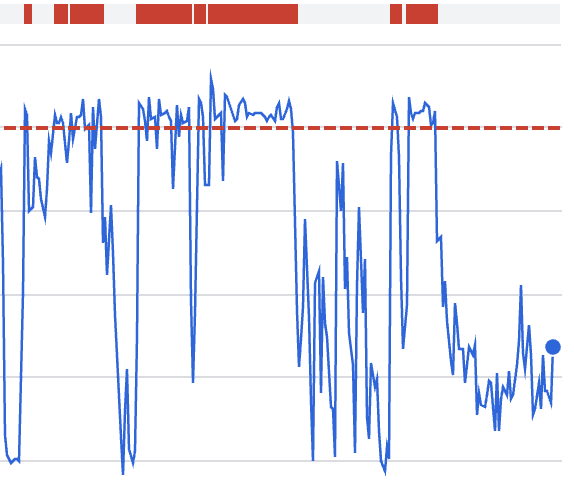
Ce que ce graphique montre :
Consommation rapide du quota pendant la fenêtre de l'incident
Corrélation avec le comportement de réessaie plutôt qu'un nouveau trafic
18h40 – Cause fondamentale identifiée : La logique de réessaie d'Atoms rafraîchissant les calendriers de manière agressive.
18h46 – La fonctionnalité d'Atoms a été temporairement interrompue. Les événements de calendrier ont été remplis et l'utilisation du quota a diminué.
18h54 – La performance de l'APIv2 est restée légèrement dégradée ; un certain trafic a été temporairement redirigé vers les points de terminaison Vercel.
19h30 – APIv2 et intégrations Google pleinement stabilisées.
Plus tard, nous avons identifié un autre problème contribuant :
Un appel promisifié non attendu a causé des plantages des processus Node lorsque les erreurs de l'API Google ont échappé au portée globale.
Cause fondamentale
La principale cause était une interaction inattendue entre les fonctionnalités :
KBar a déclenché un appel API lourd à chaque chargement de page
Ce chemin API s'appuyait sur des requêtes de base de données coûteuses ; particulièrement pour des utilisateurs à grande échelle avec de nombreuses réservations.
La saturation du CPU a augmenté la latence des requêtes dans tout le système
Les clients d'entreprise avec des types d'événements à fort volume ont été les plus touchés
Les défaillances secondaires (épuisement du quota Google et instabilité de l'APIv2) n'étaient pas la cause originale, mais ont été révélées une fois le système en stress.
Ce que nous avons changé
Depuis mardi, nous avons :
Supprimé le couplage KBar qui déclenchait des appels API lourds (#27314)
Livré plusieurs optimisations de requêtes pour réduire la charge sur la base de données (#27364, #27319, #27309, #27315)
Changé la pagination pour
/booking/{upcoming,…}de pré-rendu à la demande, réduisant l'utilisation de la base de données tout en continuant à optimiser le point de terminaison (#27351)Corrigé l'appel asynchrone non attendu causant des plantages de processus Node dans l'APIv2(#27313)
Mis en place diverses précautions au niveau de la base de données pour protéger notre base de données pendant les périodes d'utilisation extrême.
Limité les appels aux points de terminaison DELETE à 1 requête par seconde (#27359)
Conclusion
Cet incident n'a pas été causé par des pics de trafic ou une défaillance de l'infrastructure. Il a été causé par une interaction inattendue des fonctionnalités, avec des problèmes en cascade dus à un comportement de réessaie en aval et un bug subtil dans l'application.
Nous sommes désolés pour la perturbation, en particulier pour les clients opérant à grande échelle. L'incident de mardi a directement informé les améliorations apportées à la façon dont nous déployons des fonctionnalités, protégeons notre base de données et gérons les défaillances en cascade.
Merci pour votre patience et pour nous maintenir à un haut niveau d'exigence.

Commencez avec Cal.com gratuitement dès aujourd'hui !
Découvrez une planification et une productivité sans faille sans frais cachés. Inscrivez-vous en quelques secondes et commencez à simplifier votre planification dès aujourd'hui, sans carte de crédit requise !



