" height="18.016311920580208px" id="GKXyVanMq" stroke-dasharray="0" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgb(0, 0, 0)" transform="translate(3 3)" width="18px"/></svg>)
"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient><linearGradient id="CBS1bzkxF-2031533640-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgb(255, 255, 255)"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient><linearGradient id="Jd7AK81w9-2031533640-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgb(255, 255, 255)"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient></defs><g d="M 0 16 L 0 0 L 16 0 L 16 16 Z M 9.167 5.167 C 9.167 4.891 8.943 4.667 8.667 4.667 C 8.391 4.667 8.167 4.891 8.167 5.167 C 8.167 6.784 7.809 7.834 7.155 8.488 C 6.501 9.143 5.451 9.5 3.833 9.5 C 3.557 9.5 3.333 9.724 3.333 10 C 3.333 10.276 3.557 10.5 3.833 10.5 C 5.451 10.5 6.501 10.857 7.155 11.512 C 7.809 12.166 8.167 13.216 8.167 14.833 C 8.167 15.109 8.391 15.333 8.667 15.333 C 8.943 15.333 9.167 15.109 9.167 14.833 C 9.167 13.216 9.524 12.166 10.178 11.512 C 10.832 10.857 11.883 10.5 13.5 10.5 C 13.776 10.5 14 10.276 14 10 C 14 9.724 13.776 9.5 13.5 9.5 C 11.883 9.5 10.832 9.143 10.178 8.488 C 9.524 7.834 9.167 6.784 9.167 5.167 Z M 4 3.667 C 4 3.483 3.851 3.333 3.667 3.333 C 3.483 3.333 3.333 3.483 3.333 3.667 C 3.333 4.32 3.189 4.715 2.952 4.952 C 2.715 5.189 2.32 5.333 1.667 5.333 C 1.483 5.333 1.333 5.483 1.333 5.667 C 1.333 5.851 1.483 6 1.667 6 C 2.32 6 2.715 6.145 2.952 6.382 C 3.189 6.618 3.333 7.013 3.333 7.667 C 3.333 7.851 3.483 8 3.667 8 C 3.851 8 4 7.851 4 7.667 C 4 7.013 4.145 6.618 4.382 6.382 C 4.618 6.145 5.013 6 5.667 6 C 5.851 6 6 5.851 6 5.667 C 6 5.483 5.851 5.333 5.667 5.333 C 5.013 5.333 4.618 5.189 4.382 4.952 C 4.145 4.715 4 4.32 4 3.667 Z M 7.333 1 C 7.333 0.816 7.184 0.667 7 0.667 C 6.816 0.667 6.667 0.816 6.667 1 C 6.667 1.422 6.573 1.65 6.445 1.778 C 6.317 1.906 6.089 2 5.667 2 C 5.483 2 5.333 2.149 5.333 2.333 C 5.333 2.517 5.483 2.667 5.667 2.667 C 6.089 2.667 6.317 2.761 6.445 2.889 C 6.573 3.016 6.667 3.244 6.667 3.667 C 6.667 3.851 6.816 4 7 4 C 7.184 4 7.333 3.851 7.333 3.667 C 7.333 3.244 7.427 3.016 7.555 2.889 C 7.683 2.761 7.911 2.667 8.333 2.667 C 8.517 2.667 8.667 2.517 8.667 2.333 C 8.667 2.149 8.517 2 8.333 2 C 7.911 2 7.683 1.906 7.555 1.778 C 7.427 1.65 7.333 1.422 7.333 1 Z" fill="transparent" height="16px" id="aoZYv33vR" width="16px"><path d="M 0 16 L 0 0 L 16 0 L 16 16 Z" fill="transparent" height="16px" id="Z2uGmhW9f" width="16px"/><g d="M 7.833 4.5 C 7.833 4.224 7.609 4 7.333 4 C 7.057 4 6.833 4.224 6.833 4.5 C 6.833 6.117 6.476 7.168 5.822 7.822 C 5.168 8.476 4.117 8.833 2.5 8.833 C 2.224 8.833 2 9.057 2 9.333 C 2 9.61 2.224 9.833 2.5 9.833 C 4.117 9.833 5.168 10.191 5.822 10.845 C 6.476 11.499 6.833 12.549 6.833 14.167 C 6.833 14.443 7.057 14.667 7.333 14.667 C 7.609 14.667 7.833 14.443 7.833 14.167 C 7.833 12.549 8.191 11.499 8.845 10.845 C 9.499 10.191 10.549 9.833 12.167 9.833 C 12.443 9.833 12.667 9.61 12.667 9.333 C 12.667 9.057 12.443 8.833 12.167 8.833 C 10.549 8.833 9.499 8.476 8.845 7.822 C 8.191 7.168 7.833 6.117 7.833 4.5 Z M 2.667 3 C 2.667 2.816 2.517 2.667 2.333 2.667 C 2.149 2.667 2 2.816 2 3 C 2 3.654 1.855 4.048 1.618 4.285 C 1.382 4.522 0.987 4.667 0.333 4.667 C 0.149 4.667 0 4.816 0 5 C 0 5.184 0.149 5.333 0.333 5.333 C 0.987 5.333 1.382 5.478 1.618 5.715 C 1.855 5.952 2 6.346 2 7 C 2 7.184 2.149 7.333 2.333 7.333 C 2.517 7.333 2.667 7.184 2.667 7 C 2.667 6.346 2.811 5.952 3.048 5.715 C 3.285 5.478 3.68 5.333 4.333 5.333 C 4.517 5.333 4.667 5.184 4.667 5 C 4.667 4.816 4.517 4.667 4.333 4.667 C 3.68 4.667 3.285 4.522 3.048 4.285 C 2.811 4.048 2.667 3.654 2.667 3 Z M 6 0.333 C 6 0.149 5.851 0 5.667 0 C 5.483 0 5.333 0.149 5.333 0.333 C 5.333 0.756 5.239 0.984 5.112 1.112 C 4.984 1.239 4.756 1.333 4.333 1.333 C 4.149 1.333 4 1.483 4 1.667 C 4 1.851 4.149 2 4.333 2 C 4.756 2 4.984 2.094 5.112 2.222 C 5.239 2.35 5.333 2.578 5.333 3 C 5.333 3.184 5.483 3.333 5.667 3.333 C 5.851 3.333 6 3.184 6 3 C 6 2.578 6.094 2.35 6.222 2.222 C 6.35 2.094 6.578 2 7 2 C 7.184 2 7.333 1.851 7.333 1.667 C 7.333 1.483 7.184 1.333 7 1.333 C 6.578 1.333 6.35 1.239 6.222 1.112 C 6.094 0.984 6 0.756 6 0.333 Z" fill="transparent" height="14.66671286102295px" id="ae6ccdFme" transform="translate(1.333 0.667)" width="12.66663px"><path d="M 5.833 0.5 C 5.833 0.224 5.609 0 5.333 0 C 5.057 0 4.833 0.224 4.833 0.5 C 4.833 2.117 4.476 3.168 3.822 3.822 C 3.168 4.476 2.117 4.833 0.5 4.833 C 0.224 4.833 0 5.057 0 5.333 C 0 5.61 0.224 5.833 0.5 5.833 C 2.117 5.833 3.168 6.191 3.822 6.845 C 4.476 7.499 4.833 8.549 4.833 10.167 C 4.833 10.443 5.057 10.667 5.333 10.667 C 5.609 10.667 5.833 10.443 5.833 10.167 C 5.833 8.549 6.191 7.499 6.845 6.845 C 7.499 6.191 8.549 5.833 10.167 5.833 C 10.443 5.833 10.667 5.61 10.667 5.333 C 10.667 5.057 10.443 4.833 10.167 4.833 C 8.549 4.833 7.499 4.476 6.845 3.822 C 6.191 3.168 5.833 2.117 5.833 0.5 Z" fill="url(%23t2lXByE48-2031533640-linear-gradient)" height="10.66671px" id="t2lXByE48" transform="translate(2 4)" width="10.66663px"/><path d="M 2.667 0.333 C 2.667 0.149 2.517 0 2.333 0 C 2.149 0 2 0.149 2 0.333 C 2 0.987 1.855 1.382 1.618 1.618 C 1.382 1.855 0.987 2 0.333 2 C 0.149 2 0 2.149 0 2.333 C 0 2.517 0.149 2.667 0.333 2.667 C 0.987 2.667 1.382 2.811 1.618 3.048 C 1.855 3.285 2 3.68 2 4.333 C 2 4.517 2.149 4.667 2.333 4.667 C 2.517 4.667 2.667 4.517 2.667 4.333 C 2.667 3.68 2.811 3.285 3.048 3.048 C 3.285 2.811 3.68 2.667 4.333 2.667 C 4.517 2.667 4.667 2.517 4.667 2.333 C 4.667 2.149 4.517 2 4.333 2 C 3.68 2 3.285 1.855 3.048 1.618 C 2.811 1.382 2.667 0.987 2.667 0.333 Z" fill="url(%23CBS1bzkxF-2031533640-linear-gradient)" height="4.66667px" id="CBS1bzkxF" transform="translate(0 2.667)" width="4.66667px"/><path d="M 2 0.333 C 2 0.149 1.851 0 1.667 0 C 1.483 0 1.333 0.149 1.333 0.333 C 1.333 0.756 1.239 0.984 1.112 1.112 C 0.984 1.239 0.756 1.333 0.333 1.333 C 0.149 1.333 0 1.483 0 1.667 C 0 1.851 0.149 2 0.333 2 C 0.756 2 0.984 2.094 1.112 2.222 C 1.239 2.35 1.333 2.578 1.333 3 C 1.333 3.184 1.483 3.333 1.667 3.333 C 1.851 3.333 2 3.184 2 3 C 2 2.578 2.094 2.35 2.222 2.222 C 2.35 2.094 2.578 2 3 2 C 3.184 2 3.333 1.851 3.333 1.667 C 3.333 1.483 3.184 1.333 3 1.333 C 2.578 1.333 2.35 1.239 2.222 1.112 C 2.094 0.984 2 0.756 2 0.333 Z" fill="url(%23Jd7AK81w9-2031533640-linear-gradient)" height="3.333333px" id="Jd7AK81w9" transform="translate(4 0)" width="3.3333399999999997px"/></g></g></svg>)
" height="24px" id="WCm44spAV" width="24px"/><path d="M 3.892 7.742 C 1.674 7.742 0 6.014 0 3.882 C 0 1.738 1.589 0 3.892 0 C 5.107 0 5.951 0.374 6.623 1.173 L 5.566 2.09 C 5.118 1.621 4.564 1.386 3.892 1.386 C 2.452 1.386 1.547 2.517 1.547 3.882 C 1.547 5.246 2.452 6.356 3.924 6.356 C 4.649 6.356 5.193 6.111 5.63 5.63 L 6.718 6.558 C 6.153 7.24 5.193 7.742 3.892 7.742 Z" fill="rgb(255, 255, 255)" height="7.741500000000002px" id="XEPpGD7l5" transform="translate(4 8.25)" width="6.717999999999989px"/><path d="M 2.74 7.922 C 1.215 7.922 0 6.632 0 5.032 C 0 3.433 1.215 2.122 2.74 2.122 C 3.7 2.122 4.201 2.516 4.5 3.113 L 4.5 2.239 L 5.928 2.239 L 5.928 7.784 L 4.531 7.784 L 4.531 6.877 C 4.233 7.507 3.731 7.922 2.74 7.922 Z M 1.439 5.023 C 1.439 5.865 2.057 6.622 2.975 6.622 C 3.924 6.622 4.531 5.897 4.531 5.033 C 4.531 4.169 3.924 3.423 2.975 3.423 C 2.057 3.423 1.439 4.159 1.439 5.022 Z M 6.784 7.784 L 6.784 0 L 8.224 0 L 8.224 7.784 L 6.784 7.784 Z" fill="rgb(255, 255, 255)" height="7.9224997406005855px" id="lGDJupIUR" transform="translate(10.5 8)" width="8.223500194549558px"/></g></svg>)
" width="18px"><path d="M 2 8 C 0.895 8 0 7.105 0 6 L 0 2 C 0 0.895 0.895 0 2 0 L 6 0 C 7.105 0 8 0.895 8 2 L 8 6 C 8 7.105 7.105 8 6 8 Z" fill="transparent" height="8px" id="ZrCrI93dV" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" width="8px"/><path d="M 0 0 L 0 4 C 0 5.105 0.895 6 2 6 L 6 6" fill="transparent" height="6px" id="emltWYAiE" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" transform="translate(4 8)" width="6px"/><path d="M 2 8 C 0.895 8 0 7.105 0 6 L 0 2 C 0 0.895 0.895 0 2 0 L 6 0 C 7.105 0 8 0.895 8 2 L 8 6 C 8 7.105 7.105 8 6 8 Z" fill="transparent" height="8px" id="WpBecYDfi" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" transform="translate(10 10)" width="8px"/></g></svg>)

Ingegneria nel 2026 e oltre
Stiamo costruendo infrastrutture che devono quasi mai fallire. Per raggiungere questo obiettivo, ci muoviamo velocemente mentre spediamo software di qualità straordinaria senza scorciatoie o compromessi. Questo documento delinea gli standard ingegneristici che ci guideranno fino al 2026 e oltre.

Struttura del Team
La nostra organizzazione ingegneristica è composta da cinque team principali, ciascuno con responsabilità distinte:
Team di Fondazione: Si concentra sulla creazione e il mantenimento di standard di codifica e modelli architetturali. Questo team lavora in collaborazione con gli altri team per stabilire le migliori pratiche in tutta l'organizzazione.
Team Consumatori, Imprese e Piattaforma: Team focalizzati sui prodotti che rilasciano funzioni rapidamente mantenendo gli standard di qualità stabiliti in questo documento. Questi team dimostrano che velocità e qualità non sono mutuamente esclusive.
Team Comunitario: Responsabile di revisionare rapidamente le PR dalla comunità open source, fornendo feedback e guidando quel lavoro verso la fusione. Questo team garantisce che i nostri contributori open source abbiano una grande esperienza e che i loro contributi soddisfino i nostri standard di qualità.
I Nostri Risultati Finora
I dati parlano da soli. Negli ultimi diciotto mesi, abbiamo trasformato radicalmente il modo in cui costruiamo software:
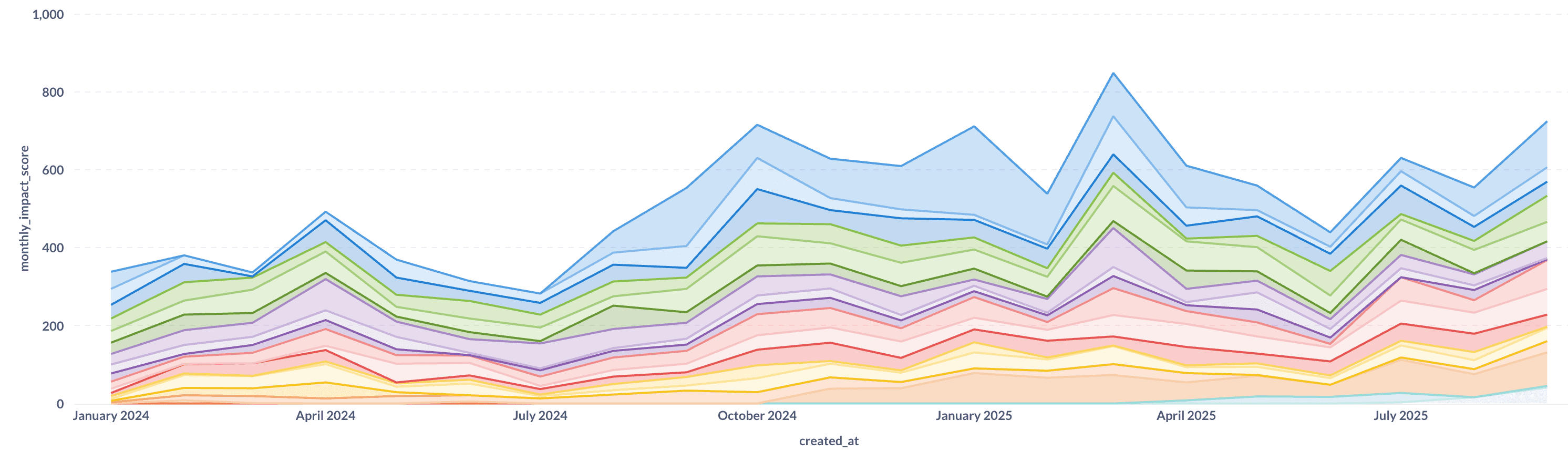
Abbiamo approssimativamente raddoppiato la nostra produttività ingegneristica migliorando contemporaneamente la qualità. Ancora più impressionante è il cambiamento di ciò che stiamo costruendo:
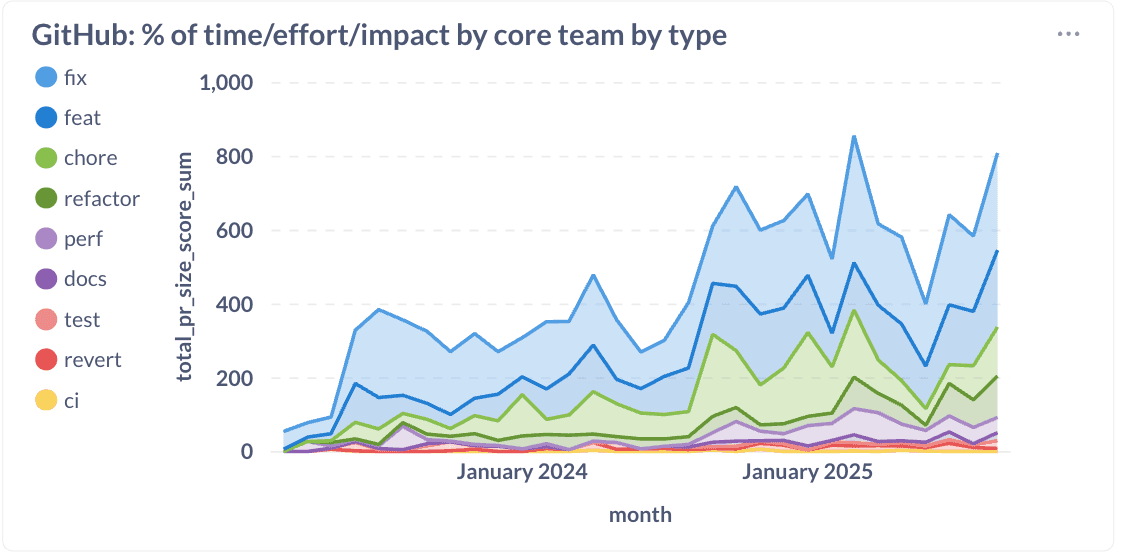
Siamo riusciti a riallocare approssimativamente il 20% dell'impegno ingegneristico dalle correzioni alle funzioni, ai miglioramenti delle prestazioni, ai rifattori e alle attività. Questo cambiamento dimostra che investire nella qualità e nell'architettura non ti rallenta. Ti accelera.
La Fondazione di Cal.com Abilita l'Eccellenza per coss.com
Cal.com è un'azienda stabile e redditizia che continueremo a far crescere.
Questo successo ci dà un vantaggio unico mentre costruiamo coss.com. A differenza dei primi giorni di Cal.com, dove dovevamo muoverci rapidamente per stabilire l'adattamento del prodotto al mercato e creare un business sostenibile, coss.com parte da una posizione di forza.
Non abbiamo bisogno di affrettare coss.com.
La stabilità di Cal.com significa che possiamo permetterci di costruire coss.com nel modo giusto fin dal primo giorno. Abbiamo il lusso di implementare questi standard ingegneristici senza la pressione delle immediate esigenze di mercato o dei vincoli di finanziamento. Questa è una posizione di partenza fondamentalmente diversa.
La "lentezza" è un investimento, non un costo.
Sì, seguire questi standard potrebbe sembrare più lento inizialmente e può addirittura essere frustrante per alcuni ingegneri. Scrivere DTO richiede più tempo rispetto al passaggio diretto dei tipi di database al frontend. Creare astrazioni adeguate e iniezione delle dipendenze richiede più progettazione iniziale. Mantenere una copertura del test del 80%+ per il nuovo codice richiede disciplina. Ma questa apparente lentezza è temporanea e il rendimento è esponenziale.
Considera i rendimenti composti...
Il codice architettato correttamente dall'inizio non necessita di massicci rifattori successivamente
Una copertura elevata dei test previene bug che altrimenti consumerebbero settimane di debugging e correzioni urgenti (vedi 2023 a metà 2024)
Le astrazioni corrette rendono l'aggiunta di nuove funzioni drammaticamente più veloce nel tempo
I confini puliti e i DTO prevengono l'erosione architetturale che alla fine richiede riscritture complete
La traiettoria Cal.com mostra cosa succede quando ottimizzi per la velocità immediata. Alta velocità iniziale che gradualmente degrada man mano che il debito tecnico si accumula, le scorciatoie architetturali creano colli di bottiglia e più tempo viene speso per risolvere problemi che per costruire caratteristiche (vedi grafico precedente dove spendevamo il 55-60% dell'impegno ingegneristico sulle correzioni).
La traiettoria di coss.com abbraccerà il potere di costruire correttamente fin dal primo giorno. Una velocità iniziale leggermente più lenta mentre si stabiliscono i modelli adeguati, seguita da un'accelerazione esponenziale man mano che quei modelli rendono e consentono uno sviluppo più rapido con maggiore fiducia.
Principi Fondamentali
1. Nessuna qualità rimandata
Minimizzeremo i "lo farò in una PR di follow-up" per i piccoli rifattori.
Le PR di follow-up per miglioramenti minori raramente si realizzano. Invece, si accumulano come debito tecnico che ci appesantisce mesi o anni dopo. Se un piccolo rifattore può essere fatto ora, fallo ora. I follow-up dovrebbero essere riservati a cambiamenti sostanziali che meritano veramente PR separate o per casi eccezionali e urgenti.
2. Alti standard nella revisione del codice
Non lasciare passare PR con molti difetti solo per evitare di essere "la persona cattiva."
È esattamente così che i codebase diventano disordinati col tempo. La revisione del codice non riguarda l'essere gentili. Riguarda il mantenimento degli standard di qualità che la nostra infrastruttura richiede. Ogni piccola imprecisione conta. Ogni violazione dei modelli conta. Affrontali prima di fare la fusione, non dopo.
3. Spronarsi a fare la cosa giusta
Ci teniamo reciprocamente responsabili per la qualità
Tagliare angoli potrebbe sembrare più veloce al momento, ma crea problemi che rallentano tutti in seguito. Quando vedi un collega che sta per unire una PR con evidenti problemi, esprimi la tua preoccupazione. Quando qualcuno suggerisce un trucco veloce invece della soluzione adeguata, rispondi. Quando sei tentato di saltare i test o ignorare i modelli architetturali, aspettati che i tuoi colleghi ti mettano in discussione.
Questo non riguarda l'essere difficili o rallentare le persone
Si tratta di una proprietà collettiva del nostro codice e della nostra reputazione. Ogni scorciatoia che una persona prende diventa un problema per tutti. Ogni angolo tagliato oggi significa più sessioni di debug, più hotfix e più clienti frustrati domani.
Rendilo normale sfidare le decisioni sbagliate, con rispetto
Se qualcuno dice "facciamo solo il codice fisso per ora", la risposta prevista dovrebbe essere "cosa ci vorrebbe per farlo nel modo giusto la prima volta?" Se qualcuno vuole commettere codice non testato, il team dovrebbe rispondere. Se qualcuno suggerisce di copiare e incollare invece di creare un'appropriata astrazione, fallo notare con rispetto.
Stiamo costruendo qualcosa che deve quasi mai fallire
Quel livello di affidabilità non accade per caso. Accade quando ogni ingegnere si sente responsabile della qualità, non solo del proprio codice ma dell'intero sistema. Riusciamo come team o falliamo come team.
4. Puntare alla semplicità
Priorità alla chiarezza sulla genialità
L'obiettivo è che il codice sia facile da leggere e capire rapidamente, non di una complessità elegante. I sistemi semplici riducono il carico cognitivo per ogni ingegnere.
Fatti le domande giuste
Sto realmente risolvendo il problema in questione?
Sto pensando troppo ai possibili casi d'uso futuri?
Ho considerato almeno un'altra alternativa per risolvere questo? Come si confronta?
Semplice non significa privo di funzionalità
Solo perché il nostro obiettivo è creare sistemi semplici, questo non significa che dovrebbero sembrare anemici e privi di funzionalità ovvie.
5. Automizzare tutto
Sfruttare l'IA
Genera l'80% del codice base e del codice non critico utilizzando l'IA, permettendoci di concentrarci solo sulla logica aziendale complessa e sulle architetture critiche.
Costruisci un'allerta senza rumore e una gestione intelligente degli errori.
Il testing manuale è sempre più una cosa del passato. L'IA può costruire rapidamente e intelligentemente mega suite di test per noi.
Il nostro CI è il boss finale
Tutto in questo documento sugli standard viene controllato prima che il codice venga unito nelle PR
Nessuna sorpresa entra in main
I controlli sono rapidi e utili
Standard Architetturali
Stiamo passando a un modello architetturale rigoroso basato su Architettura Vertical Slice e Domain-Driven Design (DDD). I seguenti modelli e principi saranno applicati rigorosamente nelle revisioni delle PR e tramite linting.
Vertical Slice Architecture: packages/features
Il nostro codice è organizzato per dominio, non per livello tecnico. La directory packages/features è il cuore di questo approccio architetturale. Ogni cartella al suo interno rappresenta una completa fetta verticale dell'applicazione, guidata dal dominio che tocca.
Struttura:
Ogni cartella delle funzioni è una fetta verticale indipendente che include tutto il necessario per quel dominio:
Logica di dominio: Le regole aziendali di base e le entità specifiche di quella funzione
Servizi applicativi: Orchestrazione dei casi d'uso per quel dominio
Repository: Accesso ai dati specifici delle esigenze di quella funzione
DTOs: Oggetti di trasferimento dati per attraversare i confini
Componenti UI: Componenti frontend relativi a questa funzione (ove applicabile)
Test: Test unitari, d'integrazione e di fine/continua 2e2 per questa funzione
Perché le Fette Verticali Contano
L'architettura tradizionale a strati è organizzata per preoccupazioni tecniche:
Questo crea diversi problemi:
Le modifiche a una funzione richiedono di toccare file sparsi in più directory
È difficile capire cosa fa una funzione perché il suo codice è frammentato
I team si ostacolano l'un l'altro quando lavorano su diverse funzioni
Non puoi facilmente estrarre o deprecare una funzione
L'architettura a fetta verticale è organizzata per dominio:
Questo risolve questi problemi:
Tutto ciò che riguarda la disponibilità si trova in
packages/features/availabilityPuoi comprendere l'intera funzione della disponibilità esplorando una directory
I team possono lavorare su diverse funzioni senza conflitti (se il team ingegneristico di Cal.com cresce ma sicuramente in coss.com avremo team che si occuperanno di pacchetti importanti)
Le funzioni sono debolmente accoppiate e possono evolvere in modo indipendente
Linee Guida per l'Organizzazione delle Funzioni
In teoria, ogni funzione è indipendentemente distribuibile. Anche se potremmo non distribuirli effettivamente separatamente, organizzare in questo modo ci obbliga a mantenere le dipendenze chiare e l'accoppiamento minimo. Questo è il presupposto e il successo dei microservizi, anche se non li stiamo ancora distribuendo.
Le funzioni comunicano tramite interfacce ben definite. Se le prenotazioni necessitano di dati sulla disponibilità, importano da @calcom/features/availability tramite interfacce esportate, non accedendo ai dettagli dell'implementazione interna.
Il codice condiviso vive nei luoghi appropriati:
Utilità agnostiche del dominio e preoccupazioni trasversali (auth, logging):
packages/libPrimitive dell'UI condivisa:
packages/ui(e presto l'ui di coss.com)
I confini del dominio sono applicati automaticamente. Costruiremo un linting che impedisce di raggiungere l'interno delle funzioni dove non dovresti essere autorizzato. Se packages/features/bookings tenta di importare da packages/features/availability/services/internal, il linter lo bloccherà. Tutte le dipendenze tra funzioni devono passare attraverso l'API pubblica delle funzioni.
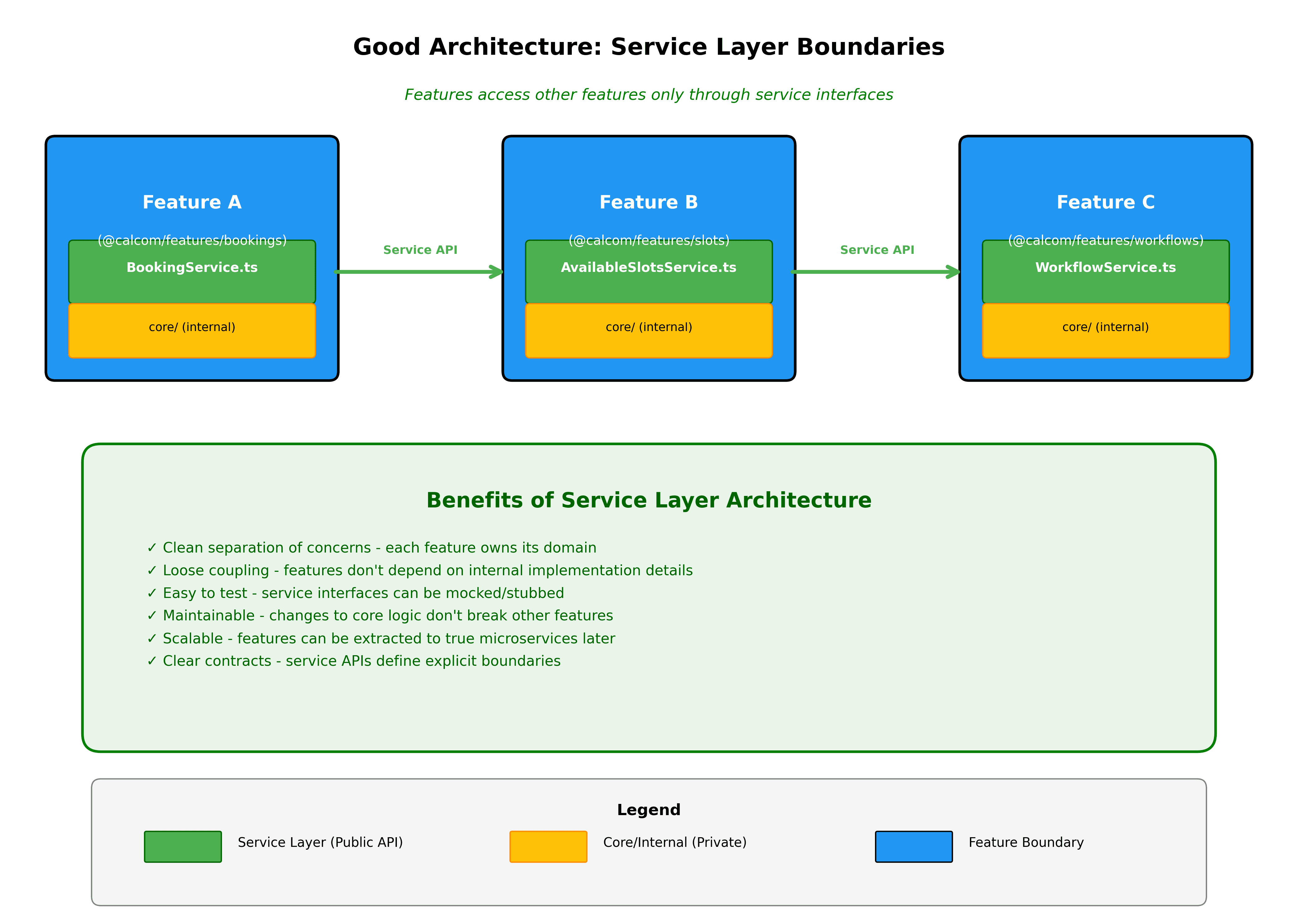
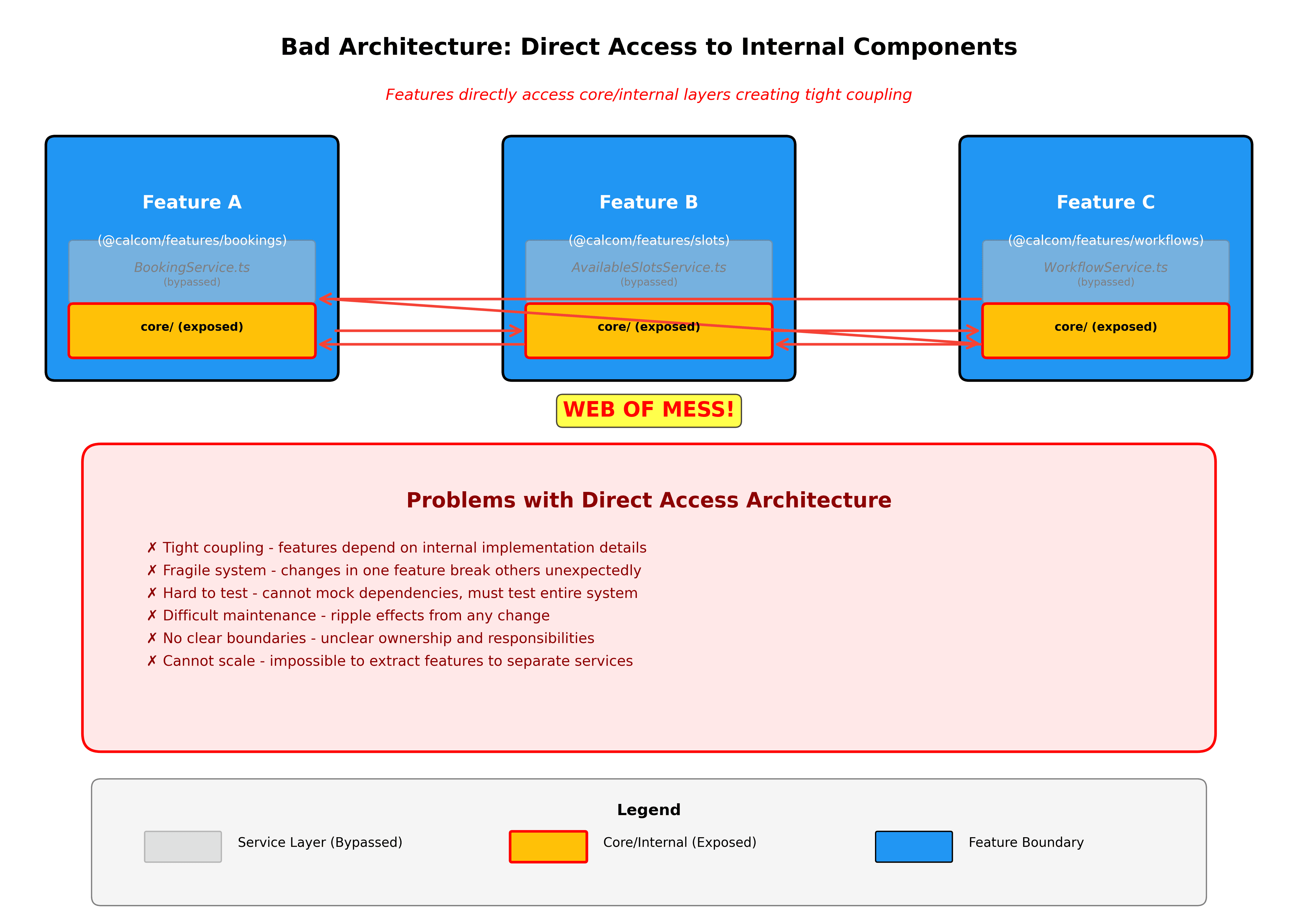
Nuove funzioni iniziano come fette verticali. Durante la creazione di qualcosa di nuovo, crea una nuova cartella in packages/features con l'intera fetta verticale. Questo rende chiaro cosa stai costruendo e mantiene tutto organizzato fin dal primo giorno.
Benefici
Scopribilità
Stai cercando la logica di prenotazione? È tutto in
packages/features/bookings. Non c'è bisogno di fare la caccia attraverso controller, servizi, repository e utilità sparsi in tutto il codice base.
Test più facili
Testa l'intera funzione come un'unità. Hai tutti i pezzi in un unico posto, rendendo naturale e semplice il testing di integrazione.
Dipendenze più chiare
Quando vedi
import { getAvailability } from '@calcom/features/availability', sai esattamente da quale funzione dipendi. Quando le dipendenze diventano troppo complesse, è evidente e può essere affrontato.
Pattern di Repository e Iniezione delle Dipendenze
Le scelte tecnologiche non devono insinuarsi attraverso l'applicazione. Il problema di Prisma lo illustra perfettamente. Attualmente abbiamo riferimenti a Prisma sparsi su centinaia di file. Questo crea un grande accoppiamento e rende i cambiamenti tecnologici proibitivamente costosi. Stiamo provando la gestione di questo aggiornamento a Prisma v6.16. Qualcosa che dovrebbe essere stato solo un rifattore localizzato dietro repository schermati è stata una caccia meandrica, quasi infinita ai problemi attraverso più app.
Lo standard per il futuro:
Tutti gli accessi al database devono passare per le classi Repository. Abbiamo già un buon punto di partenza su questo.
I repository sono l'unico codice che conosce Prisma (o qualsiasi altro ORM). Nessuna logica dovrebbe essere in loro.
I repository sono iniettati attraverso contenitori di Iniezione delle Dipendenze
Se mai passiamo da Prisma a Drizzle o un altro ORM, gli unici cambiamenti richiesti sono:
Implementazioni di repository
Cablaggio del contenitore DI per nuovi repository
Nient'altro nel codice dovrebbe preoccuparsi o cambiare
Questo non è teorico. Questo è come costruiamo sistemi mantenibili.
Data Transfer Objects (DTOs)
I tipi di database non devono trapelare al frontend. Questo è diventato un ascoltatore popolare nel nostro stack tecnologico, ma è un odore di codice che crea molti problemi.
Accoppiamento tecnologico (tipi Prisma che finiscono nei componenti React)
Rischi di sicurezza (fuga accidentale di campi sensibili)
Contratti fragili tra server e client (questo è particolarmente problematico man mano che costruiamo molte più API)
Impossibilità di evolvere lo schema del database indipendentemente
Tutte le conversioni DTO tramite Zod, anche per una risposta API, per garantire che tutti i dati vengano validati prima di inviarli all'utente. Meglio fallire che restituire qualcosa di sbagliato.
Lo standard per il futuro:
Crea espliciti DTO ad ogni confine architettonico.
Livello dati → Livello applicazione → API: Trasforma i modelli del database in DTO a livello di applicazione, poi trasforma i DTO applicativi in DTO specifici dell'API
API → Livello applicazione → Livello dati: Trasforma i DTO API attraverso il livello applicativo e in DTO specifici del dato
Sì, questo richiede più codice. Sì, ne vale la pena. Confini espliciti evitano l'erosione architetturale che crea incubi di manutenzione a lungo termine.
Pattern del Domain-Driven Design
I seguenti modelli devono essere utilizzati correttamente e consistentemente:
Servizi Applicativi
Orchestrano i casi d'uso, coordinano tra servizi di dominio e repository
Servizi di Dominio
Contengono la logica aziendale che non appartiene naturalmente a un'unica entità
Repository
Astraggono l'accesso ai dati, isolano le scelte tecnologiche
Iniezione delle Dipendenze
Consentono un accoppiamento libero, facilitano i test, isolano le preoccupazioni
Proxy di Caching
Avvolgono i repository o i servizi per aggiungere il comportamento di caching in modo trasparente
Non è l'unico modo per fare caching, ovviamente, ma un bel punto di partenza
Decoratori
Aggiungi preoccupazioni trasversali (logging, metriche, ecc.) senza inquinare la logica del dominio
Coerenza del Codice
I nostri codici base dovrebbero sembrare come se fossero scritti da una sola persona. Questo livello di coerenza richiede l'aderenza rigorosa ai modelli stabiliti, regole di linting complete che applicano gli standard architetturali, revisioni del codice che respingono le violazioni di schema + l'aiuto dei revisori di codice AI.
Spostare le Condizioni al Punto di Ingresso dell'Applicazione
Le istruzioni If appartengono al punto di ingresso, non sparse tra i tuoi servizi. Questo è uno dei principi architetturali più importanti per mantenere codice chiaro e focalizzato che non si trasforma in una complessità ingestibile.
Ecco come il codice si degrada nel tempo: Un servizio è scritto per uno scopo chiaro e specifico. La logica è pulita e focalizzata. Poi arriva un nuovo requisito di prodotto, e qualcuno aggiunge un'istruzione if. Alcuni anni e diversi altri requisiti più tardi, quel servizio è pieno di controlli condizionali per scenari diversi. Il servizio è diventato:
Complicato e difficile da leggere
Difficile da comprendere e motivare su
Più suscettibile ai bug
Violando la responsabilità singola (gestendo troppi casi diversi)
Quasi impossibile da testare a fondo
Il servizio ha superato i suoi limiti in termini di responsabilità e logica.
Una Soluzione: Pattern Factory con Servizi Specializzati
Usa il pattern factory per prendere decisioni al punto di ingresso, poi delega a servizi specializzati che gestiscono la loro logica specifica senza condizionali.
Esempio dalla nostra base di codice:
Il BillingPortalServiceFactory determina se il fatturato è per un'organizzazione, un team o un singolo utente, quindi ritorna il servizio appropriato:
Ogni servizio gestisce poi la sua logica specifica senza bisogno di controllare "sono un'organizzazione o un team?":
Perché Questo è Importante
I servizi rimangono focalizzati
Ogni servizio ha una responsabilità e non ha bisogno di sapere di altri contesti. Il
OrganizationBillingPortalServicenon contiene istruzioni if controllandoif (isTeam)oif (isUser). Sa solo come gestire le organizzazioni.
I cambiamenti sono isolati
Quando devi modificare la logica di fatturazione delle organizzazioni, tocchi solo
OrganizationBillingPortalService. Non rischi di rompere la fatturazione del team o dell'utente. Non hai bisogno di seguire attraverso condizioni annidate per capire quale percorso segue il tuo codice.
Il testing è semplice
Testa ciascun servizio indipendentemente con i suoi specifici scenari. Non c'è bisogno di testare ogni combinazione di condizioni tra diversi contesti.
I nuovi requisiti non inquinano il codice esistente
e.g. Quando hai bisogno di aggiungere la fatturazione enterprise con regole diverse, crei
EnterpriseBillingPortalService. La factory guadagna un'altra condizione, ma i servizi esistenti rimangono intatti e focalizzati.
Come Ottenere Ciò
Sposta le condizioni verso controller, factory o logica di routing. Lascia che questi punti di ingresso prendano decisioni su quale servizio utilizzare.
Mantieni i servizi puri e focalizzati su una responsabilità singola. Se un servizio ha bisogno di controllare "che tipo sono?", probabilmente hai bisogno di più servizi.
Preferisci il polimorfismo ai condizionali
Le interfacce definiscono il contratto. Le implementazioni concrete forniscono le specifiche.
Fai attenzione all'accumulazione delle istruzioni if
Durante la revisione del codice, se vedi un servizio che ottiene condizioni per scenari diversi, questo segnala di rifattorizzare in servizi specializzati.
Progettazione delle API: Controller Sottili e Astrazione HTTP
I controller sono strati sottili che gestiscono solo preoccupazioni HTTP.
Prendono richieste, le elaborano e mappano i dati ai DTO che vengono passati alla logica applicativa centrale. Andando avanti, non dovrebbero essere viste logiche applicative o centrali nelle rotte API o nei gestori tRPC.
Dobbiamo staccare la tecnologia HTTP dalla nostra applicazione.
Il modo in cui trasferiamo i dati tra client e server (sia REST, tRPC, ecc.) non dovrebbe influenzare il funzionamento della nostra applicazione centrale. HTTP è un meccanismo di consegna, non un driver architetturale.
Responsabilità del controller (e SOLO queste):
Ricevere e validare le richieste in entrata
Estrarre i dati dai parametri delle richieste, dal corpo, dalle intestazioni
Trasformare i dati della richiesta in DTO
Chiamare i servizi applicativi appropriati con quei DTO
Trasformare le risposte dei servizi applicativi in DTO di risposta
Restituire risposte HTTP con i codici di stato corretti
I controller NON devono:
Contenere logica aziendale o regole di dominio
Accedere direttamente a database o servizi esterni
Eseguire trasformazioni o calcoli complessi sui dati
Prendere decisioni su ciò che l'applicazione dovrebbe fare
Conoscere i dettagli dell'implementazione del dominio
Esempio di pattern di controller sottile:
Versionamento dell'API e Modifiche di Rottura
Nessuna modifica di rottura. Questo è critico. Una volta che un endpoint API è pubblico, deve rimanere stabile. Le modifiche di rottura distruggono la fiducia degli sviluppatori e creano incubi di integrazione per i nostri utenti.
Strategie per evitare modifiche di rottura:
Aggiungi sempre i nuovi campi come opzionali
Usa il versionamento API quando devi cambiare comportamento esistente
Depreca gli endpoint vecchi graziosamente con percorsi di migrazione chiari
Mantieni la retrocompatibilità per almeno due versioni principali
Quando devi fare modifiche di rottura:
Crea una nuova versione API utilizzando il versionamento specifico per data in API v2 (forse esamineremo anche il versionamento nominato che Stripe ha recentemente introdotto)
Esegui entrambe le versioni contemporaneamente durante la transizione (lo facciamo già in API v2)
Fornisci strumenti di migrazione automatizzati quando possibile
Dai agli utenti ampio tempo per migrare (minimo 6 mesi per API pubbliche)
Documenta esattamente cosa è cambiato e perché
Prestazioni e Complessità dell'Algoritmo
Costruiamo per grandi organizzazioni e team. Ciò che funziona bene con 10 utenti o 50 record può collassare sotto il peso della scala enterprise. Le prestazioni non sono qualcosa che ottimizziamo più tardi. È qualcosa che costruiamo correttamente fin dall'inizio.
Pensa Alla Scala Sin Dal Primo Giorno
Quando costruisci funzioni, chiediti sempre: "Come si comporta questo con 1.000 utenti? 10.000 record? 100.000 operazioni?" La differenza tra algoritmi O(n) e O(n²) potrebbe essere impercettibile nello sviluppo, ma catastrofica in produzione.
Pattern comuni O(n²) da evitare:
Iterazioni annidate degli array (
.mapdentro.map,.forEachdentro.forEach)Metodi di array come
.some,.findo.filterdentro cicli o callbackControllare ogni elemento contro ogni altro elemento senza ottimizzazione
Filtri concatenati o mappature annidate su grandi liste
Esempio reale: Per 100 slot disponibili e 50 periodi occupati, un algoritmo O(n²) esegue 5.000 controlli. Escala a 500 slot e 200 periodi occupati, e stai facendo 100.000 operazioni. Questo è un aumento di 20x nel carico di elaborazione per solo un aumento di 5x nei dati.
Scegliere le Strutture Dati e Gli Algoritmi Giusti
La maggior parte dei problemi di prestazioni sono risolti scegliendo migliori strutture dati e algoritmi:
Sorting + uscita anticipata: Ordina i tuoi dati una volta, poi esci dai cicli quando sai che gli elementi rimanenti non corrisponderanno
Ricerca binaria: Usa la ricerca binaria per ricerche in array ordinati invece di scansioni lineari
Tecniche a doppio puntatore: Per unire o intersecare sequenze ordinate, attraversale entrambe con puntatori invece di cicli annidati
Hash map/set: Usa oggetti o Set per ricerche O(1) invece di
.findo.includessu arrayAlberi di intervallo: Per pianificazione, disponibilità e interrogazioni di intervalli, usa strutture ad albero adeguate invece di confronto a forza bruta
Esempio di trasformazione:
Controlli di Prestazione Automatizzati
Implementeremo più strati di difesa contro le regressioni prestazionali:
Regole di linting che segnalano:
Funzioni con cicli annidati o metodi di array annidati
Chiamate
.some,.find, o.filterannidate multipleRicorsione senza memoization
Noti anti-pattern per il nostro dominio (scheduling, controlli di disponibilità, ecc.)
Benchmark di prestazioni nel CI che:
Eseguono algoritmi critici su dati realistici e su larga scala
Confrontano i tempi di esecuzione con il benchmark su ogni PR
Bloccano le fusioni che introducono regressioni prestazionali
Test con dati su scala enterprise (migliaia di utenti, decine di migliaia di record)
Monitoraggio di produzione che:
Traccia il tempo di esecuzione per percorsi critici
Avvisa quando gli algoritmi rallentano man mano che i dati crescono
Cattura le regressioni prima che gli utenti le notino
Fornisce dati prestazionali reali per informare le ottimizzazioni
La Prestazione è una Caratteristica
Le prestazioni non sono opzionali. Non è qualcosa che affrontiamo "dopo". Per i clienti aziendali che prenotano per team su larga scala, risposte lente significano produttività persa e utenti frustrati (la nostra esperienza con alcuni grandi clienti aziendali può esserne una testimonianza).
Ogni ingegnere dovrebbe:
Profilare il tuo codice prima di ottimizzare, ma pensa alla complessità dall'inizio
Test con dati realistici su larga scala (non solo 5 record di test). Abbiamo già costruito script di seed. Probabilmente dobbiamo estendere.
Scegli algoritmi e strutture dati efficienti in modo predefinito
Fai attenzione alle iterazioni annidate durante la revisione del codice
Metti in discussione qualsiasi algoritmo che scala con il prodotto di due variabili
La Realtà NP-Hard della Pianificazione
I problemi di pianificazione sono fondamentalmente NP-hard. Ciò significa che man mano che il numero di vincoli, partecipanti o slot temporali cresce, la complessità computazionale può esplodere esponenzialmente. La maggior parte degli algoritmi di pianificazione ottimali ha un tempo complesso esponenziale nei casi peggiori, rendendo la scelta dell'algoritmo assolutamente critica.
Implicazioni reali:
Trovare il tempo di incontro ottimale per 10 persone in 3 fusi orari con vincoli di disponibilità individuale è costoso computazionalmente
Aggiungere rilevamento conflitti, buffer e una pletora di altre opzioni amplifica il problema
Scelte algoritmiche pessime che funzionano bene per piccoli team diventano completamente inutilizzabili per grandi organizzazioni
Ciò che richiede millisecondi per 5 utenti potrebbe richiedere molti secondi per le organizzazioni
Strategie per gestire la complessità NP-hard:
Usa algoritmi di approssimazione che trovano soluzioni "abbastanza buone" rapidamente anziché soluzioni perfette lentamente
Implementare il caching aggressivo di orari e disponibilità calcolati
Pre-calcolate scenari comuni durante le ore non di picco
Spezzare grandi problemi di pianificazione in pezzi più piccoli e gestibili
Impostare limiti di timeout ragionevoli e ripiegare su algoritmi più semplici quando necessario
Questo è il motivo per cui le prestazioni non sono solo un "nice-to-have" nel software di pianificazione. È la base che determina se il tuo sistema può scalare alle esigenze aziendali o collassare sotto i modelli di uso reali.
Requisiti di Copertura del Codice
Tracciamento di copertura globale
Tracciamo la copertura complessiva della base di codice come una metrica chiave che migliora nel tempo. Questo ci dà visibilità sulla nostra maturità nei test e aiuta a identificare le aree che necessitano di attenzione. La percentuale di copertura globale è visualizzata in modo prominente nei nostri dashboard.
Copertura dell'80%+ per nuovo codice
Ogni PR deve avere una copertura di test vicino all'80%+ per il codice che introduce o modifica. Questo è applicato automaticamente nel nostro ciclo CI. Se aggiungi 50 righe di nuovo codice, quelle 50 righe devono essere coperte dai test. Se modifichi una funzione esistente, le tue modifiche devono essere testate. Questa è una copertura complessiva dei test. La copertura dei test unitari deve essere vicino al 100 %, specialmente con la possibilità di sfruttare l'IA per aiutare a generare questi.
Rispondendo all'argomento "la copertura non è l'intera storia": Sì, sappiamo che la copertura non garantisce test perfetti. Sappiamo che puoi scrivere test privi di senso che colpiscono ogni riga ma non testano nulla di significativo. Sappiamo che la copertura è solo una metrica tra molte. Ma, certamente è meglio puntare a una percentuale alta che non avere idea di dove sei.
Misurare il Successo
"Velocità" (prendendola dallo Scrum anche se non utilizzeremo Scrum)
Crescita continua nelle statistiche mensili (funzioni, miglioramenti, rifattori)
Qualità
Ridurre l'impegno sulle PR sull'effettuare le correzioni dall'attuale 35 % a 20 % o meno entro la fine del 2026 (calcolato in base alle modifiche ai file e alle aggiunte/eliminazioni)
Salute architetturale
Metriche sull'aderenza agli schemi, accoppiamento tecnologico, violazioni di confini
Efficienza delle revisioni
PR più piccole, revisioni più veloci, meno giri di feedback
Uptime dell'applicazione e dell'API
Quanto siamo vicini al 99,99%?

Inizia subito gratuitamente con Cal.com!
Sperimenta una programmazione e produttività senza interruzioni senza spese nascoste. Iscriviti in pochi secondi e inizia a semplificare la tua programmazione oggi, senza bisogno di carta di credito!



