" height="18.016311920580208px" id="GKXyVanMq" stroke-dasharray="0" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgb(0, 0, 0)" transform="translate(3 3)" width="18px"/></svg>)
"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient><linearGradient id="CBS1bzkxF-2031533640-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgb(255, 255, 255)"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient><linearGradient id="Jd7AK81w9-2031533640-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgb(255, 255, 255)"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient></defs><g d="M 0 16 L 0 0 L 16 0 L 16 16 Z M 9.167 5.167 C 9.167 4.891 8.943 4.667 8.667 4.667 C 8.391 4.667 8.167 4.891 8.167 5.167 C 8.167 6.784 7.809 7.834 7.155 8.488 C 6.501 9.143 5.451 9.5 3.833 9.5 C 3.557 9.5 3.333 9.724 3.333 10 C 3.333 10.276 3.557 10.5 3.833 10.5 C 5.451 10.5 6.501 10.857 7.155 11.512 C 7.809 12.166 8.167 13.216 8.167 14.833 C 8.167 15.109 8.391 15.333 8.667 15.333 C 8.943 15.333 9.167 15.109 9.167 14.833 C 9.167 13.216 9.524 12.166 10.178 11.512 C 10.832 10.857 11.883 10.5 13.5 10.5 C 13.776 10.5 14 10.276 14 10 C 14 9.724 13.776 9.5 13.5 9.5 C 11.883 9.5 10.832 9.143 10.178 8.488 C 9.524 7.834 9.167 6.784 9.167 5.167 Z M 4 3.667 C 4 3.483 3.851 3.333 3.667 3.333 C 3.483 3.333 3.333 3.483 3.333 3.667 C 3.333 4.32 3.189 4.715 2.952 4.952 C 2.715 5.189 2.32 5.333 1.667 5.333 C 1.483 5.333 1.333 5.483 1.333 5.667 C 1.333 5.851 1.483 6 1.667 6 C 2.32 6 2.715 6.145 2.952 6.382 C 3.189 6.618 3.333 7.013 3.333 7.667 C 3.333 7.851 3.483 8 3.667 8 C 3.851 8 4 7.851 4 7.667 C 4 7.013 4.145 6.618 4.382 6.382 C 4.618 6.145 5.013 6 5.667 6 C 5.851 6 6 5.851 6 5.667 C 6 5.483 5.851 5.333 5.667 5.333 C 5.013 5.333 4.618 5.189 4.382 4.952 C 4.145 4.715 4 4.32 4 3.667 Z M 7.333 1 C 7.333 0.816 7.184 0.667 7 0.667 C 6.816 0.667 6.667 0.816 6.667 1 C 6.667 1.422 6.573 1.65 6.445 1.778 C 6.317 1.906 6.089 2 5.667 2 C 5.483 2 5.333 2.149 5.333 2.333 C 5.333 2.517 5.483 2.667 5.667 2.667 C 6.089 2.667 6.317 2.761 6.445 2.889 C 6.573 3.016 6.667 3.244 6.667 3.667 C 6.667 3.851 6.816 4 7 4 C 7.184 4 7.333 3.851 7.333 3.667 C 7.333 3.244 7.427 3.016 7.555 2.889 C 7.683 2.761 7.911 2.667 8.333 2.667 C 8.517 2.667 8.667 2.517 8.667 2.333 C 8.667 2.149 8.517 2 8.333 2 C 7.911 2 7.683 1.906 7.555 1.778 C 7.427 1.65 7.333 1.422 7.333 1 Z" fill="transparent" height="16px" id="aoZYv33vR" width="16px"><path d="M 0 16 L 0 0 L 16 0 L 16 16 Z" fill="transparent" height="16px" id="Z2uGmhW9f" width="16px"/><g d="M 7.833 4.5 C 7.833 4.224 7.609 4 7.333 4 C 7.057 4 6.833 4.224 6.833 4.5 C 6.833 6.117 6.476 7.168 5.822 7.822 C 5.168 8.476 4.117 8.833 2.5 8.833 C 2.224 8.833 2 9.057 2 9.333 C 2 9.61 2.224 9.833 2.5 9.833 C 4.117 9.833 5.168 10.191 5.822 10.845 C 6.476 11.499 6.833 12.549 6.833 14.167 C 6.833 14.443 7.057 14.667 7.333 14.667 C 7.609 14.667 7.833 14.443 7.833 14.167 C 7.833 12.549 8.191 11.499 8.845 10.845 C 9.499 10.191 10.549 9.833 12.167 9.833 C 12.443 9.833 12.667 9.61 12.667 9.333 C 12.667 9.057 12.443 8.833 12.167 8.833 C 10.549 8.833 9.499 8.476 8.845 7.822 C 8.191 7.168 7.833 6.117 7.833 4.5 Z M 2.667 3 C 2.667 2.816 2.517 2.667 2.333 2.667 C 2.149 2.667 2 2.816 2 3 C 2 3.654 1.855 4.048 1.618 4.285 C 1.382 4.522 0.987 4.667 0.333 4.667 C 0.149 4.667 0 4.816 0 5 C 0 5.184 0.149 5.333 0.333 5.333 C 0.987 5.333 1.382 5.478 1.618 5.715 C 1.855 5.952 2 6.346 2 7 C 2 7.184 2.149 7.333 2.333 7.333 C 2.517 7.333 2.667 7.184 2.667 7 C 2.667 6.346 2.811 5.952 3.048 5.715 C 3.285 5.478 3.68 5.333 4.333 5.333 C 4.517 5.333 4.667 5.184 4.667 5 C 4.667 4.816 4.517 4.667 4.333 4.667 C 3.68 4.667 3.285 4.522 3.048 4.285 C 2.811 4.048 2.667 3.654 2.667 3 Z M 6 0.333 C 6 0.149 5.851 0 5.667 0 C 5.483 0 5.333 0.149 5.333 0.333 C 5.333 0.756 5.239 0.984 5.112 1.112 C 4.984 1.239 4.756 1.333 4.333 1.333 C 4.149 1.333 4 1.483 4 1.667 C 4 1.851 4.149 2 4.333 2 C 4.756 2 4.984 2.094 5.112 2.222 C 5.239 2.35 5.333 2.578 5.333 3 C 5.333 3.184 5.483 3.333 5.667 3.333 C 5.851 3.333 6 3.184 6 3 C 6 2.578 6.094 2.35 6.222 2.222 C 6.35 2.094 6.578 2 7 2 C 7.184 2 7.333 1.851 7.333 1.667 C 7.333 1.483 7.184 1.333 7 1.333 C 6.578 1.333 6.35 1.239 6.222 1.112 C 6.094 0.984 6 0.756 6 0.333 Z" fill="transparent" height="14.66671286102295px" id="ae6ccdFme" transform="translate(1.333 0.667)" width="12.66663px"><path d="M 5.833 0.5 C 5.833 0.224 5.609 0 5.333 0 C 5.057 0 4.833 0.224 4.833 0.5 C 4.833 2.117 4.476 3.168 3.822 3.822 C 3.168 4.476 2.117 4.833 0.5 4.833 C 0.224 4.833 0 5.057 0 5.333 C 0 5.61 0.224 5.833 0.5 5.833 C 2.117 5.833 3.168 6.191 3.822 6.845 C 4.476 7.499 4.833 8.549 4.833 10.167 C 4.833 10.443 5.057 10.667 5.333 10.667 C 5.609 10.667 5.833 10.443 5.833 10.167 C 5.833 8.549 6.191 7.499 6.845 6.845 C 7.499 6.191 8.549 5.833 10.167 5.833 C 10.443 5.833 10.667 5.61 10.667 5.333 C 10.667 5.057 10.443 4.833 10.167 4.833 C 8.549 4.833 7.499 4.476 6.845 3.822 C 6.191 3.168 5.833 2.117 5.833 0.5 Z" fill="url(%23t2lXByE48-2031533640-linear-gradient)" height="10.66671px" id="t2lXByE48" transform="translate(2 4)" width="10.66663px"/><path d="M 2.667 0.333 C 2.667 0.149 2.517 0 2.333 0 C 2.149 0 2 0.149 2 0.333 C 2 0.987 1.855 1.382 1.618 1.618 C 1.382 1.855 0.987 2 0.333 2 C 0.149 2 0 2.149 0 2.333 C 0 2.517 0.149 2.667 0.333 2.667 C 0.987 2.667 1.382 2.811 1.618 3.048 C 1.855 3.285 2 3.68 2 4.333 C 2 4.517 2.149 4.667 2.333 4.667 C 2.517 4.667 2.667 4.517 2.667 4.333 C 2.667 3.68 2.811 3.285 3.048 3.048 C 3.285 2.811 3.68 2.667 4.333 2.667 C 4.517 2.667 4.667 2.517 4.667 2.333 C 4.667 2.149 4.517 2 4.333 2 C 3.68 2 3.285 1.855 3.048 1.618 C 2.811 1.382 2.667 0.987 2.667 0.333 Z" fill="url(%23CBS1bzkxF-2031533640-linear-gradient)" height="4.66667px" id="CBS1bzkxF" transform="translate(0 2.667)" width="4.66667px"/><path d="M 2 0.333 C 2 0.149 1.851 0 1.667 0 C 1.483 0 1.333 0.149 1.333 0.333 C 1.333 0.756 1.239 0.984 1.112 1.112 C 0.984 1.239 0.756 1.333 0.333 1.333 C 0.149 1.333 0 1.483 0 1.667 C 0 1.851 0.149 2 0.333 2 C 0.756 2 0.984 2.094 1.112 2.222 C 1.239 2.35 1.333 2.578 1.333 3 C 1.333 3.184 1.483 3.333 1.667 3.333 C 1.851 3.333 2 3.184 2 3 C 2 2.578 2.094 2.35 2.222 2.222 C 2.35 2.094 2.578 2 3 2 C 3.184 2 3.333 1.851 3.333 1.667 C 3.333 1.483 3.184 1.333 3 1.333 C 2.578 1.333 2.35 1.239 2.222 1.112 C 2.094 0.984 2 0.756 2 0.333 Z" fill="url(%23Jd7AK81w9-2031533640-linear-gradient)" height="3.333333px" id="Jd7AK81w9" transform="translate(4 0)" width="3.3333399999999997px"/></g></g></svg>)
" height="24px" id="WCm44spAV" width="24px"/><path d="M 3.892 7.742 C 1.674 7.742 0 6.014 0 3.882 C 0 1.738 1.589 0 3.892 0 C 5.107 0 5.951 0.374 6.623 1.173 L 5.566 2.09 C 5.118 1.621 4.564 1.386 3.892 1.386 C 2.452 1.386 1.547 2.517 1.547 3.882 C 1.547 5.246 2.452 6.356 3.924 6.356 C 4.649 6.356 5.193 6.111 5.63 5.63 L 6.718 6.558 C 6.153 7.24 5.193 7.742 3.892 7.742 Z" fill="rgb(255, 255, 255)" height="7.741500000000002px" id="XEPpGD7l5" transform="translate(4 8.25)" width="6.717999999999989px"/><path d="M 2.74 7.922 C 1.215 7.922 0 6.632 0 5.032 C 0 3.433 1.215 2.122 2.74 2.122 C 3.7 2.122 4.201 2.516 4.5 3.113 L 4.5 2.239 L 5.928 2.239 L 5.928 7.784 L 4.531 7.784 L 4.531 6.877 C 4.233 7.507 3.731 7.922 2.74 7.922 Z M 1.439 5.023 C 1.439 5.865 2.057 6.622 2.975 6.622 C 3.924 6.622 4.531 5.897 4.531 5.033 C 4.531 4.169 3.924 3.423 2.975 3.423 C 2.057 3.423 1.439 4.159 1.439 5.022 Z M 6.784 7.784 L 6.784 0 L 8.224 0 L 8.224 7.784 L 6.784 7.784 Z" fill="rgb(255, 255, 255)" height="7.9224997406005855px" id="lGDJupIUR" transform="translate(10.5 8)" width="8.223500194549558px"/></g></svg>)
" width="18px"><path d="M 2 8 C 0.895 8 0 7.105 0 6 L 0 2 C 0 0.895 0.895 0 2 0 L 6 0 C 7.105 0 8 0.895 8 2 L 8 6 C 8 7.105 7.105 8 6 8 Z" fill="transparent" height="8px" id="ZrCrI93dV" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" width="8px"/><path d="M 0 0 L 0 4 C 0 5.105 0.895 6 2 6 L 6 6" fill="transparent" height="6px" id="emltWYAiE" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" transform="translate(4 8)" width="6px"/><path d="M 2 8 C 0.895 8 0 7.105 0 6 L 0 2 C 0 0.895 0.895 0 2 0 L 6 0 C 7.105 0 8 0.895 8 2 L 8 6 C 8 7.105 7.105 8 6 8 Z" fill="transparent" height="8px" id="WpBecYDfi" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" transform="translate(10 10)" width="8px"/></g></svg>)

Ingenieurswetenschappen in 2026 en daarna
We bouwen infrastructuur die vrijwel nooit mag falen. Om dit te bereiken, bewegen we snel terwijl we geweldige kwaliteitssoftware leveren zonder ergens op te beknibbelen of concessies te doen. Dit document schetst de engineeringstandaarden die ons zullen begeleiden tot 2026 en verder.

Teamstructuur
Onze ingenieursorganisatie bestaat uit vijf kernteams, elk met verschillende verantwoordelijkheden:
Foundation Team: Richt zich op het vaststellen en onderhouden van coderingsnormen en architectuurpatronen. Dit team werkt samen met andere teams om beste praktijken organisatiebreed vast te stellen.
Consumenten-, Ondernemings- en Platformteams: Productgerichte teams die snel functies leveren terwijl ze voldoen aan de kwaliteitsnormen die in dit document zijn vastgelegd. Deze teams bewijzen dat snelheid en kwaliteit niet elkaar uitsluiten.
Community Team: Verantwoordelijk voor het snel beoordelen van PR's van de open-source community, het geven van feedback en het begeleiden van dat werk naar merge. Dit team zorgt ervoor dat onze open-source bijdragers een geweldige ervaring hebben en dat hun bijdragen voldoen aan onze kwaliteitsnormen.
Onze Resultaten Tot Nu Toe
De data spreekt voor zich. In het afgelopen anderhalf jaar hebben we fundamenteel getransformeerd hoe we software bouwen:
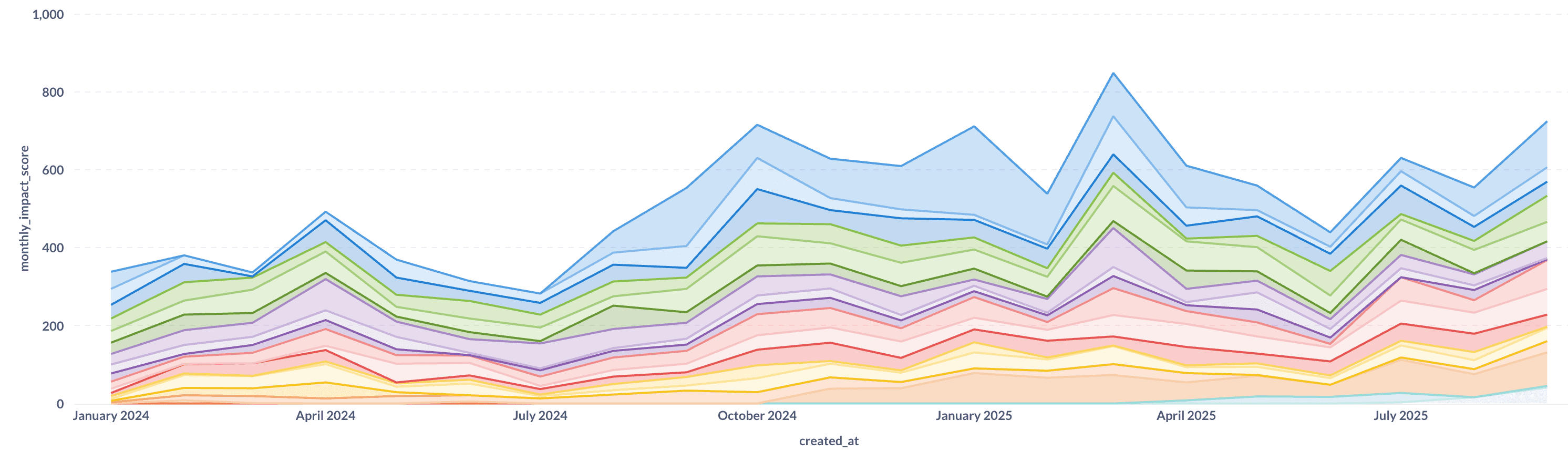
We hebben ons ingenieursresultaat ongeveer verdubbeld terwijl we tegelijkertijd de kwaliteit verbeterden. Nog indrukwekkender is de verschuiving in wat we bouwen:
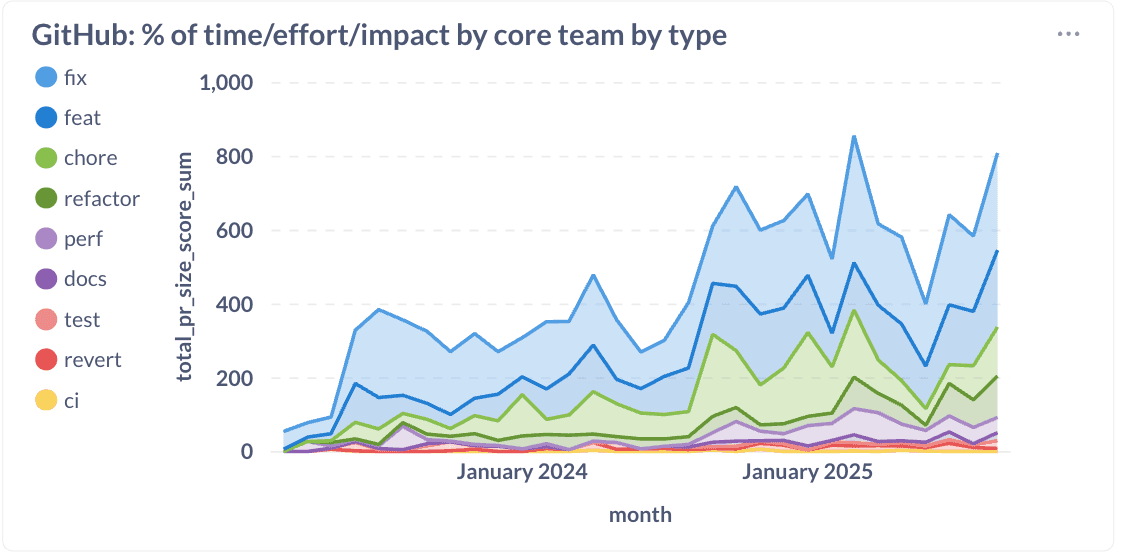
We hebben met succes ongeveer 20% van de inspanning van ingenieurs herverdeeld van fixes naar functies, prestatieverbeteringen, refactors, en klussen. Deze verschuiving toont aan dat investeren in kwaliteit en architectuur je niet vertraagt. Het versnelt je.
Cal.com's Basis Maakt Uitmuntendheid Mogelijk voor coss.com
Cal.com is een stabiel, winstgevend bedrijf dat we zullen blijven laten groeien.
Dit succes geeft ons een uniek voordeel bij het bouwen van coss.com. In tegenstelling tot de vroege dagen van Cal.com, waar we snel moesten handelen om product-markt fit te bereiken en een duurzaam bedrijf op te bouwen, begint coss.com vanuit een sterke positie.
We hoeven ons niet te haasten met coss.com.
De stabiliteit van Cal.com betekent dat we ons kunnen veroorloven om coss.com vanaf dag één op de juiste manier te bouwen. We hebben het voorrecht om deze ingenieursnormen te implementeren zonder de druk van directe markteisen of financieringsbeperkingen. Dit is een fundamenteel andere startpositie.
De 'traagheid' is een investering, geen kosten.
Ja, het volgen van deze normen kan initieel langzamer aanvoelen en kan zelfs frustrerend zijn voor sommige ingenieurs. Het schrijven van DTO's kost meer tijd dan het rechtstreeks naar de frontend doorgeven van database typen. Het creëren van goede abstracties en dependency-injectie vereist meer voorafgaande ontwerp. Het aanhouden van 80%+ testdekking voor nieuwe code vraagt discipline. Maar deze schijnbare traagheid is tijdelijk, en de beloning is exponentieel.
Overweeg de samengestelde rendementen...
Code die vanaf het begin correct is ingericht, heeft later geen massale refactors nodig
Hoge testdekking voorkomt bugs die anders weken van debuggings- en hotfixes zouden vergen (zie 2023 tot midden 2024)
Goede abstracties maken het veel sneller toevoegen van nieuwe functies in de loop der tijd
Schone grenzen en DTO's voorkomen de architecturale erosie die uiteindelijk volledige herschrijvingen vereist
Het Cal.com traject laat zien wat er gebeurt als je optimaliseert voor onmiddellijke snelheid. Hoge aanvankelijke snelheid die geleidelijk afneemt, omdat technische schuld zich opstapelt, architecturale shortcuts knelpunten creëren, en meer tijd wordt besteed aan probleemoplossing dan aan het bouwen van functies (zie eerdere grafiek waar we 55-60% van de inspanning van ingenieurs aan fixes besteedden).
Het coss.com traject zal de kracht omarmen van vanaf dag één goed bouwen. Iets tragere initiële snelheid bij het vaststellen van goede patronen, gevolgd door exponentiële versnelling naarmate die patronen rendementen opleveren en snellere ontwikkeling met meer vertrouwen mogelijk maken.
Kernprincipes
1. Geen uitgestelde kwaliteit
We minimaliseren 'ik doe het in een vervolg-PR' voor kleine refactors.
Vervolg-PR's voor kleine verbeteringen worden zelden gerealiseerd. In plaats daarvan stapelen ze zich op als technische schuld die ons maanden of jaren later belast. Als er nu een kleine refactor gedaan kan worden, doe het dan nu. Vervolgacties moeten worden gereserveerd voor aanzienlijke veranderingen die daadwerkelijk aparte PR's rechtvaardigen of voor uitzonderlijke, dringende gevallen.
2. Hoge normen in code review
Laat PR’s niet door met veel kleinigheden alleen om te vermijden de ‘slecht persoon’ te zijn.
Dit is precies hoe codebases na verloop van tijd slordig worden. Code review gaat niet over aardig zijn. Het gaat over het handhaven van de kwaliteitseisen die onze infrastructuur vereist. Elke kleinigheid doet ertoe. Elke patroonovereenkomst doet ertoe. Pak ze aan voordat je merge, niet erna.
3. Duw elkaar om het juiste te doen
We houden elkaar verantwoordelijk voor kwaliteit
Hoeken afsnijden kan sneller aanvoelen op dat moment, maar het creëert problemen die iedereen later vertragen. Wanneer je ziet dat een teamgenoot op het punt staat een PR met duidelijke problemen te mergen, zeg er iets van. Wanneer iemand een quick hack voorstelt in plaats van de juiste oplossing, duw dan terug. Wanneer je in de verleiding komt om tests over te slaan of architecturale patronen te negeren, verwacht dan dat je teamgenoten je uitdagen.
Dit gaat niet over moeilijk zijn of mensen vertragen
Het gaat over collectief eigenaarschap van onze codebase en onze reputatie. Elke shortcut die een persoon neemt, wordt ieders probleem. Elke hoek die vandaag wordt afgesneden, betekent meer debuggingssessies, meer hotfixes, en meer gefrustreerde klanten morgen.
Maak het normaal om slechte beslissingen respectvol uit te dagen
Als iemand zegt "laten we dit nu even hard coden", moet de verwachte reactie zijn: "wat zou het vereisen om het meteen op de juiste manier te doen?" Als iemand onvergetest code wil committen, moet het team terugduwen. Als iemand voorstelt om te kopiëren en plakken in plaats van een goede abstractie te creëren, noem het dan respectvol.
We bouwen iets dat bijna nooit mag falen
Dat niveau van betrouwbaarheid gebeurt niet per ongeluk. Het gebeurt wanneer elke ingenieur zich verantwoordelijk voelt voor kwaliteit, niet alleen hun eigen code maar het hele systeem. We slagen als een team of falen als een team.
4. Streef naar eenvoud
Prioriteit geven aan duidelijkheid boven slimheid
Het doel is code die snel te lezen en te begrijpen is, niet elegante complexiteit. Simpele systemen verminderen de cognitieve belasting voor elke ingenieur.
Stel jezelf de juiste vragen
Los ik eigenlijk het probleem op dat ik moet oplossen?
Denk ik te veel na over mogelijke toekomstige use cases?
Heb ik ten minste één ander alternatief overwogen om dit op te lossen? Hoe vergelijkt het?
Eenvoudig betekent niet zonder functies
Alleen omdat ons doel is om eenvoudige systemen te maken, betekent dit niet dat ze anemisch moeten aanvoelen en voor de hand liggende functionaliteit moeten missen.
5. Automatiseer alles
Maak gebruik van AI
Genereer 80% van boilerplate en niet-kritieke code met AI, waardoor we ons volledig kunnen concentreren op complexe bedrijfslogica en kritische architecturen.
Creëer alarmen zonder ruis en slimme foutafhandeling.
Handmatig testen is steeds meer verleden tijd. AI kan snel en intelligent grote testsuites voor ons maken.
Onze CI is de eindbaas
Alles in dit standaarddocument wordt gecontroleerd voordat code wordt samengevoegd in PR's
Er komen geen verrassingen in main terecht
Checks zijn snel en nuttig
Architecturale Standaarden
We gaan over naar een strikt architecturaal model gebaseerd op Vertical Slice Architecture en Domain-Driven Design (DDD). De volgende patronen en principes zullen rigoureus worden afgedwongen in PR-reviews en via linting.
Vertical Slice Architecture: packages/features
Onze codebase is georganiseerd op basis van domein, niet door technische laag. De packages/features-directory is het hart van deze architectonische benadering. Elke map binnenin vertegenwoordigt een complete verticale slice van de applicatie, gedreven door het domein dat het raakt.
Structuur:
Elke functiemap is een zelfvoorzienende verticale slice die alles bevat wat nodig is voor dat domein:
Domeinlogica: De kernbedrijfregels en entiteiten die specifiek zijn voor die functie
Applicatiediensten: Use case-orkestratie voor dat domein
Repositories: Gegevens die specifiek zijn voor de behoeften van die functie
DTO's: Gegevensoverdrachtobjecten voor het oversteken van grenzen
UI-componenten: Frontend-componenten gerelateerd aan deze functie (waar van toepassing)
Tests: Unit-, integratie- en e2e-tests voor deze functie
Waarom Vertical Slices Belangrijk Zijn
Traditionele gelaagde architectuur is georganiseerd op technische kwesties:
Dit creëert verschillende problemen:
Wijzigingen in één functie vereisen het aanraken van bestanden verspreid over meerdere directories
Het is moeilijk om te begrijpen wat een functie doet omdat de code gefragmenteerd is
Teams lopen elkaar voor de voeten bij het werken aan verschillende functies
Je kunt niet gemakkelijk een functie extraheren of afschaffen
Verticale slice-architectuur is georganiseerd op basis van domein:
Dit lost deze problemen op:
Alles wat betrekking heeft op beschikbaarheid bevindt zich in
packages/features/availabilityJe kunt de hele beschikbaarheidsfunctie begrijpen door één directory te verkennen
Teams kunnen aan verschillende functies werken zonder conflicten (als het Cal.com ingenieursteam groeit, maar zeker in coss.com zullen we teams grote pakketten laten nemen)
Functies zijn losjes gekoppeld en kunnen onafhankelijk evolueren
Richtlijnen voor Het Organiseren van Functies
In theorie is elke functie onafhankelijk inzetbaar. Hoewel we ze misschien niet echt afzonderlijk inzetten, dwingt deze organisatie ons om de afhankelijkheden duidelijk te houden en de koppeling minimaal te houden. Dit is het uitgangspunt en het succes van microservices, hoewel we nog geen microservices zullen implementeren.
Functies communiceren via goed gedefinieerde interfaces. Als boekingen beschikbaarheidsgegevens nodig heeft, importeert het van @calcom/features/availability via geëxporteerde interfaces, niet door in interne implementatiedetails te duiken.
Gedeelde code leeft op geschikte plaatsen:
Domeinonafhankelijke hulpprogramma's en cross-cutting concerns (authenticatie, loggen) :
packages/libGedeelde UI-primitieven:
packages/ui(en binnenkort coss.com ui)
Domeingrenzen worden automatisch afgedwongen. We zullen linting bouwen die voorkomt dat u de interne van functies binnendringt waar u niet mag komen. Als packages/features/bookings probeert te importeren van packages/features/availability/services/internal, blokkeert de linter het. Alle cross-feature afhankelijkheden moeten via de openbare API van de functie gaan.
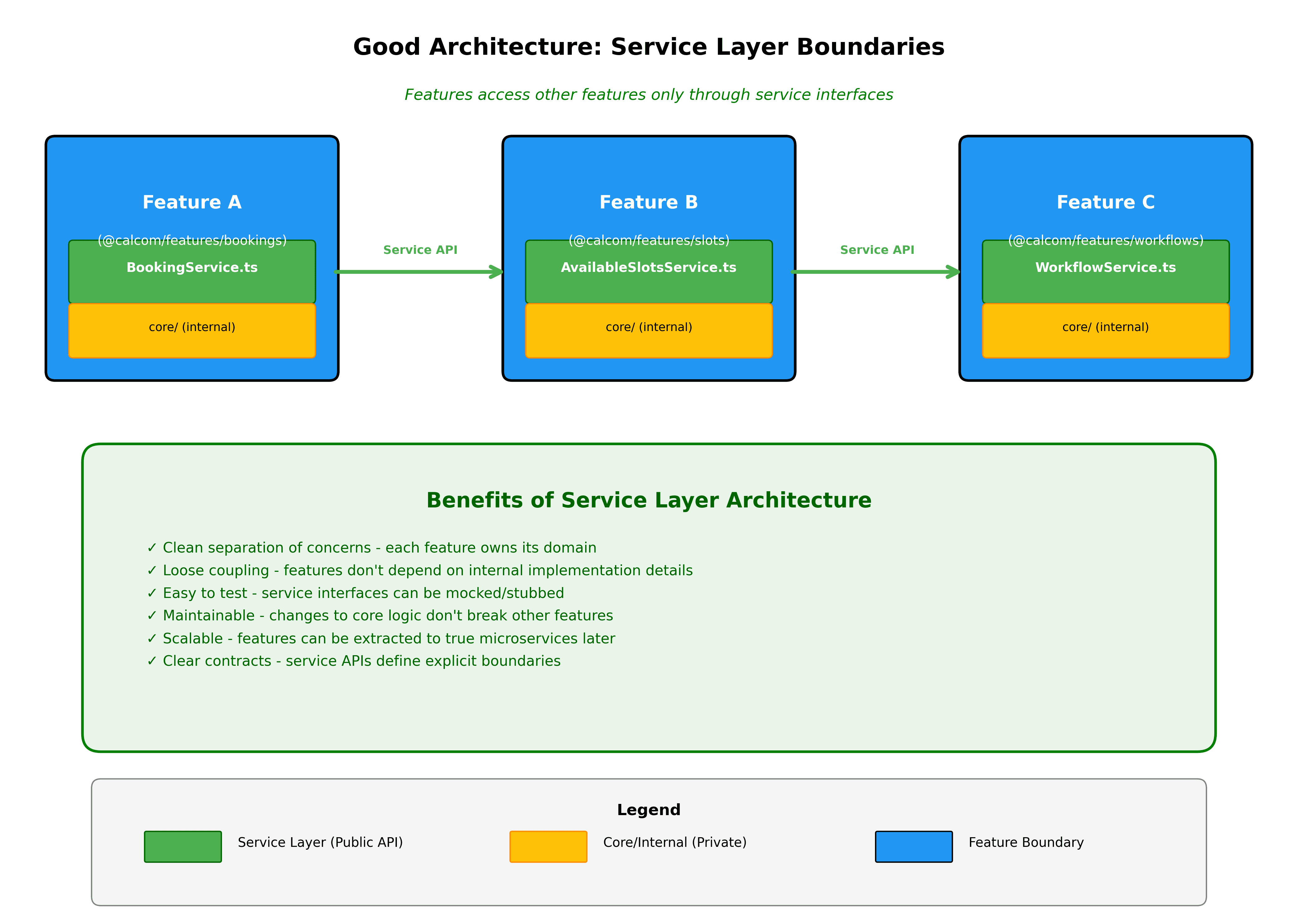
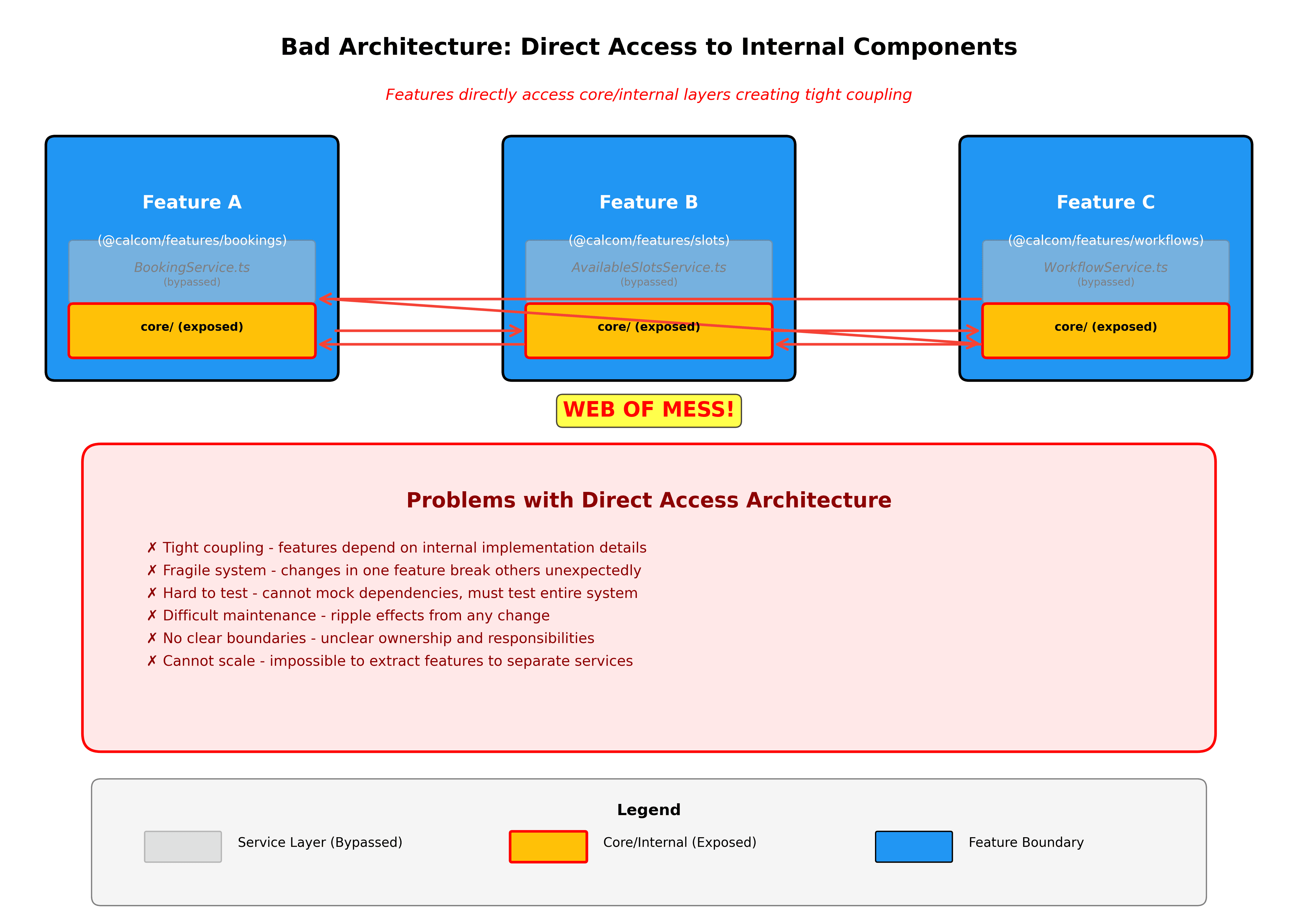
Nieuwe functies beginnen als verticale slices. Bij het bouwen van iets nieuws, maak een nieuwe map in packages/features met de complete verticale slice. Dit maakt het duidelijk wat je bouwt en houdt alles vanaf dag één georganiseerd.
Voordelen
Ontdekbaarheid
Zoek je boekingslogica? Het staat allemaal in
packages/features/bookings. Niet nodig om te zoeken door controllers, services, repositories en hulpprogramma's verspreid over de codebase.
Eenvoudiger testen
Test de hele functie als een eenheid. Je hebt alle stukken op één plek, waardoor integratietesten natuurlijk en eenvoudig worden.
Duidelijkere afhankelijkheden
Wanneer je ziet
import { getAvailability } from '@calcom/features/availability', weet je precies op welke functie je vertrouwt. Wanneer afhankelijkheden te complex worden, is het duidelijk en kan het worden aangepakt.
Repositorypatroon en Dependency Injection
Technologische keuzes mogen niet doorsijpelen door de applicatie. Het Prisma-probleem illustreert dit perfect. We hebben momenteel verwijzingen naar Prisma verspreid over honderden bestanden. Dit creëert enorme koppeling en maakt technologieveranderingen onbetaalbaar duur. We voelen de pijn hiervan nu bij de upgrade van Prisma naar v6.16. Iets dat alleen een lokale refactor achter afgeschermde repositories had moeten zijn, is een meanderende, bijna eindeloze jacht op problemen over meerdere apps geworden.
De standaard vanaf nu:
Alle database-toegang moet via Repository-klassen gaan. We hebben hier al een mooie voorsprong mee.
Repositories zijn de enige code die weet van Prisma (of een andere ORM). Er mag geen logica in zitten.
Repositories worden geïnjecteerd via Dependency Injection containers
Als we ooit overschakelen van Prisma naar Drizzle of een andere ORM, zijn de enige vereiste veranderingen:
Repository-implementaties
DI-containterbekabeling voor nieuwe repositories
Niets anders in de codebase moet zich erom bekommeren of veranderen
Dit is niet theoretisch. Dit is hoe we onderhoudbare systemen bouwen.
Gegevensoverdrachtobjecten (DTO's)
Databasetypen mogen niet lekken naar de frontend. Dit is een populaire korte route geworden in ons techstack, maar het is een geur van code die meerdere problemen creëert.
Technologische koppeling (Prisma-typen eindigen in React-componenten)
Beveiligingsrisico's (onbedoeld lekken van gevoelige velden)
Fragiele contracten tussen server en client (dit is vooral problematisch naarmate we veel meer API's bouwen)
Onvermogen om het databaseschema onafhankelijk te evolueren
Alle DTO-conversies door Zod, zelfs voor een API-reactie om ervoor te zorgen dat alle gegevens worden gevalideerd voordat ze naar de gebruiker worden verzonden. Beter falen dan iets verkeerds terugsturen.
De standaard vanaf nu:
Maak expliciete DTO's bij elke architecturale grens.
Gegevenslaag → Applicatielaag → API: Transformeer databasemodellen in toepassingslaag-DTO's, transformeer vervolgens applicatielaag-DTO's in API-specifieke DTO's
API → Applicatielaag → Gegevenslaag: Transformeer API-DTO's via de applicatielaag en in gegeven-specifieke DTO's
Ja, dit vereist meer code. Ja, het is het waard. Expliciete grenzen voorkomen de architecturale erosie die lange termijn onderhoudsnachtmerries creëert.
Domain-Driven Design Patronen
De volgende patronen moeten correct en consistent worden gebruikt:
Applicatieservices
Orkestreer use cases, coördineer tussen domain diensten en repositories
Domain Diensten
Bevat zakelijke logica die niet van nature tot één entiteit behoort
Repositories
Abstracte gegevens, isoleren technologie keuzes
Dependency Injection
Mogelijk maken van losse koppeling, faciliteren van testen, isoleren van zorgen
Caching Proxy's
Omsluiten repositories of diensten om cachegedrag transparant toe te voegen
Natuurlijk niet de enige manier om caching te doen, maar een mooi startpunt
Decorators
Voeg cross-cutting concerns (logging, metrics, enz.) toe zonder domeinlogica te vervuilen
Consistentie van de Codebase
Onze codebases moeten aanvoelen alsof één persoon ze heeft geschreven. Dit niveau van consistentie vereist strikte naleving van vastgestelde patronen, uitgebreide lintregels die architectonische standaarden afdwingen code reviews die patroon schendingen afwijzen + de hulp van AI code reviewers.
Verplaats Conditionals naar het Toepassingsinvoerpunt
Als-instructies behoren thuis in het invoerpunt, niet verspreid over je services. Dit is een van de belangrijkste architectonische principes voor het behouden van schone, gerichte code die niet onhoudbaar complex wordt.
Dit is hoe code na verloop van tijd achteruitgaat: Een service is geschreven voor een duidelijk, specifiek doel. De logica is schoon en gefocust. Dan komt er een nieuwe productvereiste binnen, en iemand voegt een if-statement toe. Een paar jaar en nog een aantal vereisten later zit die service vol met conditionele controles voor verschillende scenario's. De service is geworden:
Gecompliceerd en moeilijk te lezen
Moeilijk te begrijpen en te doorgronden
Meer vatbaar voor bugs
Overtreding van enkelvoudige verantwoordelijkheid (handelt te veel verschillende gevallen af)
Vrijwel onmogelijk volledig te testen
De service is over zijn grenzen gegaan qua verantwoordelijkheden en logica.
Een Oplossing: Factory-patroon met Gespecialiseerde Services
Gebruik het factory-patroon om beslissingen te maken op het invoerpunt, en draag dan over aan gespecialiseerde services die hun specifieke logica zonder conditionals afhandelen.
Voorbeeld uit onze codebase:
De BillingPortalServiceFactory bepaalt of facturering is voor een organisatie, team of individuele gebruiker, en retourneert dan de juiste service:
Elke service behandelt zijn specifieke logica zonder te hoeven controleren "ben ik een organisatie of een team?":
Waarom Dit Belangrijk Is
Services blijven gefocust
Elke service heeft één verantwoordelijkheid en hoeft niets te weten over andere contexten. De
OrganizationBillingPortalServicebevat geen if-statement checksif (isTeam)ofif (isUser). Het weet alleen hoe het organisaties moet afhandelen.
Wijzigingen zijn geïsoleerd
Wanneer je de organisatie-logica voor facturering moet wijzigen, hoef je alleen maar
OrganizationBillingPortalServiceaan te raken. Je loopt geen risico om team- of gebruikersfacturering te breken. Je hoeft geen geneste conditionals te volgen om te begrijpen welk pad je code volgt.
Testen is eenvoudig
Test elke service onafhankelijk met zijn specifieke scenario's. Geen nood om elke combinatie van conditionals in verschillende contexten te testen.
Nieuwe vereisten vervuilen bestaande code niet
bijv. Wanneer je bedrijf-facturering met andere regels moet toevoegen, creëer je
EnterpriseBillingPortalService. De factory krijgt één voorwaarde meer, maar bestaande services blijven onaangeroerd en gefocust.
Hoe Te Bereiken
Duw conditionals omhoog naar controllers, factories of routeringslogica. Laat deze invoerpunten beslissingen nemen over welke service te gebruiken.
Houd services zuiver en gericht op één verantwoordelijkheid. Als een service moet controleren "welk type ben ik?", heb je waarschijnlijk meerdere services nodig.
Voorkeur voor polymorfisme boven conditionals
Interfaces definiëren het contract. Concrete implementaties bieden de specificaties.
Let op conditieophoping
Tijdens code review, als je ziet dat een service conditionals zich ophoopt voor verschillende scenario's, is dat een signaal om te refactoren naar gespecialiseerde services.
API Design: Dunne Controllers en HTTP Abstractie
Controllers zijn dunne lagen die zich alleen bezighouden met HTTP-zaken.
Ze nemen verzoeken aan, verwerken ze en mappen gegevens naar DTO's die aan kernapplicatielogica worden doorgegeven. Voortaan mag er geen applicatie- of kernlogica te zien zijn in API-routes of tRPC-handlers.
We moeten HTTP-technologie loskoppelen van onze applicatie.
De manier waarop we gegevens tussen client en server overdragen (of het nu REST, tRPC, enz. is) mag de werking van onze kernapplicatie niet beïnvloeden. HTTP is een leveringsmechanisme, geen architectonische driver.
Controller verantwoordelijkheden (en ALLEEN deze):
Ontvangen en valideren van binnenkomende verzoeken
Gegevens uit aanvraagparameters, body, headers halen
Verzoekgegevens omzetten in DTO's
Juist applicatiediensten aanroepen met die DTO's
Applicatieservice-antwoorden omzetten in respons-DTO's
HTTP-antwoorden retourneren met de juiste statuscodes
Controllers moeten NIET:
Bedrijfseigen logica of domeinregels bevatten
Direct toegang krijgen tot databases of externe diensten
Ingewikkelde gegevensomzettingen of berekeningen uitvoeren
Beslissingen nemen over wat de applicatie moet doen
Weten van implementatiedetails van het domein
Voorbeeld van het dunne controller-patroon:
API Versiebeheer en Brekende Veranderingen
Geen brekende veranderingen. Dit is cruciaal. Zodra een API-endpoint openbaar is, moet het stabiel blijven. Brekende veranderingen vernietigen het vertrouwen van ontwikkelaars en creëren integratie nachtmerries voor onze gebruikers.
Strategies voor het vermijden van brekende veranderingen:
Voeg altijd nieuwe velden toe als optioneel
Gebruik API-versiebeheer wanneer u bestaand gedrag moet wijzigen
Deprecieer oude endpoints op een sierlijke manier met duidelijke migratiepaden
Behoud achterwaartse compatibiliteit voor ten minste twee hoofdversies
Wanneer u brekende veranderingen moet maken:
Maak een nieuwe API-versie aan met behulp van het datum specifieke versiebeheer in API v2 (misschien zullen we ook naar het als recent geïntroduceerde noemversiebeheer van Stripe kijken)
Voer beide versies tegelijkertijd uit tijdens de overgang (we doen dit al in API v2)
Bied indien mogelijk geautomatiseerde migratietools aan
Geef gebruikers ruim de tijd om te migreren (minimaal 6 maanden voor openbare API's)
Documenteer precies wat er veranderd is en waarom
Prestatie en Algorithmische Complexiteit
We bouwen voor grote organisaties en teams. Wat prima werkt met 10 gebruikers of 50 records kan onder het gewicht van enterprise schaal instorten. Prestaties zijn geen iets wat we later optimaliseren. Het is iets wat we correct vanaf het begin bouwen.
Denk Aan Schaal Vanaf Dag Eén
Bij het bouwen van functies, vraag altijd: "Hoe gedraagt dit zich met 1.000 gebruikers? 10.000 records? 100.000 operaties?" Het verschil tussen O(n) en O(n²) algoritmen kan onzichtbaar zijn in ontwikkeling, maar rampzalig in productie.
Veelvoorkomende O(n²) patronen om te vermijden:
Geneste array-iteraties (
.mapbinnen.map,.forEachbinnen.forEach)Array-methoden zoals
.some,.find, of.filterbinnen lussen of callbacksElk item vergelijken met elk ander item zonder optimalisatie
Gefilterde filters of geneste mapping over grote lijsten
Reëel wereld voorbeeld: Voor 100 beschikbare slots en 50 drukke periodes, presteert een O(n²) algoritme 5.000 controles. Schaal dit naar 500 slots en 200 drukke periodes, en je doet 100.000 operaties. Dat is een 20x toename in computationele lading voor slechts een 5x toename in gegevens.
Kies de Juiste Gegevensstructuren en Algoritmen
De meeste prestatieproblemen worden opgelost door betere gegevensstructuren en algoritmen te kiezen:
Sorteren + vroege uitgang: Sorteren je gegevens één keer, dan in lussenbreken wanneer je weet dat de rest van de items niet zal overeenkomen
Binaire zoekopdracht: Gebruik binaire zoekopdrachten voor doorzoekingen in gesorteerde arrays in plaats van lineaire scans
Twee-vinger technieken: Voor het samenvoegen of kruisen van gesorteerde sequenties, loop er doorheen met pointers in plaats van geneste loops
Hash-sets: Gebruik objecten of Sets voor O(1) zoekopdrachten in plaats van
.findof.includesop arraysInterval bomen: Voor planning, beschikbaarheid, en bereik aanvragen, gebruik goede boomstructuren in plaats van brute force vergelijkingen
Voorbeeld transformatie:
Geautomatiseerde Prestatietesten
We zullen meerdere lagen van verdediging implementeren tegen prestatieregressies:
Linting regels die vlaggen:
Functies met geneste loops of geneste array-methoden
Meerdere geneste
.some,.find, of.filtercallsRecursie zonder memoization
Bekende anti-patronen voor ons domein (planning, beschikbaarheidscontroles, enz.)
Prestatienormen in CI die:
Cruciale algoritmen uitvoeren op realistische, grootschalige gegevens
Uitvoeringstijden vergelijken met baseline bij elke PR
Samengaan blokkeren die prestatieregressies introduceren
Testen met gegevens op ondernemingsniveau (duizenden gebruikers, tienduizenden records)
Productiebewaking die:
Tracksuitvoeringstijd voor cruciale paden
Waarschuwingen bij vertraging van algoritmen naarmate gegevens groeien
Regressies vastleggen voordat gebruikers iets merken
Reële prestatiedata biedt om optimalisaties te informeren
Prestaties zijn een Kenmerk
Prestaties zijn niet optioneel. Het is niet iets wat we "later" doen. Voor zakelijke klanten die boeken over grote teams, betekenen trage reacties verloren productiviteit en gefrustreerde gebruikers (onze ervaring met sommige grotere zakelijke klanten kan hiervan getuigen).
Elke ingenieur moet:
Voer een profiel van uw code uit voordat u optimaliseert, maar denk vanaf het begin aan complexiteit
Test met realistische, grootschalige gegevens (niet alleen 5 test records). We hebben al zaaiprotocollen gebouwd. We moeten ze waarschijnlijk uitbreiden.
Kies efficiënte algoritmen en gegevensstructuren vooraf
Let op geneste iteraties in code review
Vraag naar elk algoritme dat met het product van twee variabelen schaalt
De NP-Harde Realiteit van Planning
Planproblemen zijn fundamenteel NP-moeilijk. Dit betekent dat naarmate het aantal beperkingen, deelnemers, of tijdslots groeit, de computationele complexiteit exponentieel kan toenemen. De meeste optimale planningsalgoritmen hebben een worst-case exponentiële tijdcomplexiteit, wat keuze van algoritmen cruciaal maakt.
Reële wereldimplicaties:
De optimale vergadertijd voor 10 mensen vinden over 3 tijdzones met afzonderlijke beschikbaarheidsbeperkingen is computationeel duur
Door conflictdetectie, buffers, en een veelheid aan andere opties toe te voegen, wordt het probleem versterkt
Slechte algoritmen die prima werken voor kleine teams worden volledig onbruikbaar voor grote organisaties
Wat milliseconden kost voor 5 gebruikers kan meerdere seconden duren voor ondernemingen
Strategies voor het beheren van NP-moeilijke complexiteit:
Gebruik benaderingsalgoritmen die "goed genoeg" oplossingen snel vinden in plaats van perfecte oplossingen langzaam
Implementeer agressieve caching van berekende schema's en beschikbaarheid
Pre-compute veelvoorkomende scenario's buiten drukke uren
Breek grote planningsproblemen op in kleinere, beter beheersbare stukken
Stel redelijke time-out limieten en val terug naar eenvoudigere algoritmen wanneer nodig
Dit is waarom prestaties niet alleen fijn zijn in planningssoftware. Het is de basis die bepaalt of je systeem kan opschalen naar enterprise-niveau of instort onder real-world gebruikspatronen.
Code Coverage Vereisten
Wereldwijde dekkingstracking
We volgen de algehele dekking van de codebase als een belangrijke metric die na verloop van tijd verbetert. Dit geeft ons inzicht in onze testvolwassenheid en helpt gebieden te identificeren die aandacht behoeven. Het wereldwijde dekkingpercentage wordt prominent weergegeven in onze dashboards.
80%+ dekking voor nieuwe code
Elke PR moet bijna 80%+ testdekking hebben voor de code die het introduceert of aanpast. Dit wordt automatisch afgedwongen in onze CI-pijplijn. Als je 50 regels nieuwe code toevoegt, moeten die 50 regels gedekt zijn door tests. Als je een bestaande functie aanpast, moeten je wijzigingen worden getest. Dit is de algehele testdekking. Unit-testdekking moet bijna 100% zijn, vooral met de mogelijkheid om AI te gebruiken om deze te genereren.
Inspreken tegen het "dekking is niet het hele verhaal" argument: Ja, we weten dat dekking geen perfecte tests garandeert. We weten dat je zinloze tests kunt schrijven die elke regel raken maar geen betekenisvolle test. We weten dat dekking maar één van de vele metrics is. Maar, het is zeker beter om te streven naar een hoog percentage dan geen idee te hebben waar je bent.
Succes Meten
"Snelheid" (geleend van Scrum hoewel we Scrum niet zullen gebruiken)
Voortdurende groei in maandstatistieken (functies, verbeteringen, refactors)
Kwaliteit
Verminder PR-inspanningen die aan fixes worden besteed van de huidige 35% tot 20% of lager eind 2026 (berekend op basis van bestandswijzigingen en toevoegingen/verwijderingen)
Architecturale gezondheid
Metric op patroon naleving, technologie koppeling, grensoverschrijdende schendingen
Review-efficiëntie
Kleinere PR's, snellere reviews, minder feedbackrondes
Applicatie en API uptime
Hoe dicht benaderen we 99,99%?

Begin vandaag nog gratis met Cal.com!
Ervaar naadloze planning en productiviteit zonder verborgen kosten. Meld je in enkele seconden aan en begin vandaag nog met het vereenvoudigen van je planning, geen creditcard vereist!



