" height="18.016311920580208px" id="GKXyVanMq" stroke-dasharray="0" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgb(0, 0, 0)" transform="translate(3 3)" width="18px"/></svg>)
"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient><linearGradient id="CBS1bzkxF-2031533640-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgb(255, 255, 255)"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient><linearGradient id="Jd7AK81w9-2031533640-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgb(255, 255, 255)"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient></defs><g d="M 0 16 L 0 0 L 16 0 L 16 16 Z M 9.167 5.167 C 9.167 4.891 8.943 4.667 8.667 4.667 C 8.391 4.667 8.167 4.891 8.167 5.167 C 8.167 6.784 7.809 7.834 7.155 8.488 C 6.501 9.143 5.451 9.5 3.833 9.5 C 3.557 9.5 3.333 9.724 3.333 10 C 3.333 10.276 3.557 10.5 3.833 10.5 C 5.451 10.5 6.501 10.857 7.155 11.512 C 7.809 12.166 8.167 13.216 8.167 14.833 C 8.167 15.109 8.391 15.333 8.667 15.333 C 8.943 15.333 9.167 15.109 9.167 14.833 C 9.167 13.216 9.524 12.166 10.178 11.512 C 10.832 10.857 11.883 10.5 13.5 10.5 C 13.776 10.5 14 10.276 14 10 C 14 9.724 13.776 9.5 13.5 9.5 C 11.883 9.5 10.832 9.143 10.178 8.488 C 9.524 7.834 9.167 6.784 9.167 5.167 Z M 4 3.667 C 4 3.483 3.851 3.333 3.667 3.333 C 3.483 3.333 3.333 3.483 3.333 3.667 C 3.333 4.32 3.189 4.715 2.952 4.952 C 2.715 5.189 2.32 5.333 1.667 5.333 C 1.483 5.333 1.333 5.483 1.333 5.667 C 1.333 5.851 1.483 6 1.667 6 C 2.32 6 2.715 6.145 2.952 6.382 C 3.189 6.618 3.333 7.013 3.333 7.667 C 3.333 7.851 3.483 8 3.667 8 C 3.851 8 4 7.851 4 7.667 C 4 7.013 4.145 6.618 4.382 6.382 C 4.618 6.145 5.013 6 5.667 6 C 5.851 6 6 5.851 6 5.667 C 6 5.483 5.851 5.333 5.667 5.333 C 5.013 5.333 4.618 5.189 4.382 4.952 C 4.145 4.715 4 4.32 4 3.667 Z M 7.333 1 C 7.333 0.816 7.184 0.667 7 0.667 C 6.816 0.667 6.667 0.816 6.667 1 C 6.667 1.422 6.573 1.65 6.445 1.778 C 6.317 1.906 6.089 2 5.667 2 C 5.483 2 5.333 2.149 5.333 2.333 C 5.333 2.517 5.483 2.667 5.667 2.667 C 6.089 2.667 6.317 2.761 6.445 2.889 C 6.573 3.016 6.667 3.244 6.667 3.667 C 6.667 3.851 6.816 4 7 4 C 7.184 4 7.333 3.851 7.333 3.667 C 7.333 3.244 7.427 3.016 7.555 2.889 C 7.683 2.761 7.911 2.667 8.333 2.667 C 8.517 2.667 8.667 2.517 8.667 2.333 C 8.667 2.149 8.517 2 8.333 2 C 7.911 2 7.683 1.906 7.555 1.778 C 7.427 1.65 7.333 1.422 7.333 1 Z" fill="transparent" height="16px" id="aoZYv33vR" width="16px"><path d="M 0 16 L 0 0 L 16 0 L 16 16 Z" fill="transparent" height="16px" id="Z2uGmhW9f" width="16px"/><g d="M 7.833 4.5 C 7.833 4.224 7.609 4 7.333 4 C 7.057 4 6.833 4.224 6.833 4.5 C 6.833 6.117 6.476 7.168 5.822 7.822 C 5.168 8.476 4.117 8.833 2.5 8.833 C 2.224 8.833 2 9.057 2 9.333 C 2 9.61 2.224 9.833 2.5 9.833 C 4.117 9.833 5.168 10.191 5.822 10.845 C 6.476 11.499 6.833 12.549 6.833 14.167 C 6.833 14.443 7.057 14.667 7.333 14.667 C 7.609 14.667 7.833 14.443 7.833 14.167 C 7.833 12.549 8.191 11.499 8.845 10.845 C 9.499 10.191 10.549 9.833 12.167 9.833 C 12.443 9.833 12.667 9.61 12.667 9.333 C 12.667 9.057 12.443 8.833 12.167 8.833 C 10.549 8.833 9.499 8.476 8.845 7.822 C 8.191 7.168 7.833 6.117 7.833 4.5 Z M 2.667 3 C 2.667 2.816 2.517 2.667 2.333 2.667 C 2.149 2.667 2 2.816 2 3 C 2 3.654 1.855 4.048 1.618 4.285 C 1.382 4.522 0.987 4.667 0.333 4.667 C 0.149 4.667 0 4.816 0 5 C 0 5.184 0.149 5.333 0.333 5.333 C 0.987 5.333 1.382 5.478 1.618 5.715 C 1.855 5.952 2 6.346 2 7 C 2 7.184 2.149 7.333 2.333 7.333 C 2.517 7.333 2.667 7.184 2.667 7 C 2.667 6.346 2.811 5.952 3.048 5.715 C 3.285 5.478 3.68 5.333 4.333 5.333 C 4.517 5.333 4.667 5.184 4.667 5 C 4.667 4.816 4.517 4.667 4.333 4.667 C 3.68 4.667 3.285 4.522 3.048 4.285 C 2.811 4.048 2.667 3.654 2.667 3 Z M 6 0.333 C 6 0.149 5.851 0 5.667 0 C 5.483 0 5.333 0.149 5.333 0.333 C 5.333 0.756 5.239 0.984 5.112 1.112 C 4.984 1.239 4.756 1.333 4.333 1.333 C 4.149 1.333 4 1.483 4 1.667 C 4 1.851 4.149 2 4.333 2 C 4.756 2 4.984 2.094 5.112 2.222 C 5.239 2.35 5.333 2.578 5.333 3 C 5.333 3.184 5.483 3.333 5.667 3.333 C 5.851 3.333 6 3.184 6 3 C 6 2.578 6.094 2.35 6.222 2.222 C 6.35 2.094 6.578 2 7 2 C 7.184 2 7.333 1.851 7.333 1.667 C 7.333 1.483 7.184 1.333 7 1.333 C 6.578 1.333 6.35 1.239 6.222 1.112 C 6.094 0.984 6 0.756 6 0.333 Z" fill="transparent" height="14.66671286102295px" id="ae6ccdFme" transform="translate(1.333 0.667)" width="12.66663px"><path d="M 5.833 0.5 C 5.833 0.224 5.609 0 5.333 0 C 5.057 0 4.833 0.224 4.833 0.5 C 4.833 2.117 4.476 3.168 3.822 3.822 C 3.168 4.476 2.117 4.833 0.5 4.833 C 0.224 4.833 0 5.057 0 5.333 C 0 5.61 0.224 5.833 0.5 5.833 C 2.117 5.833 3.168 6.191 3.822 6.845 C 4.476 7.499 4.833 8.549 4.833 10.167 C 4.833 10.443 5.057 10.667 5.333 10.667 C 5.609 10.667 5.833 10.443 5.833 10.167 C 5.833 8.549 6.191 7.499 6.845 6.845 C 7.499 6.191 8.549 5.833 10.167 5.833 C 10.443 5.833 10.667 5.61 10.667 5.333 C 10.667 5.057 10.443 4.833 10.167 4.833 C 8.549 4.833 7.499 4.476 6.845 3.822 C 6.191 3.168 5.833 2.117 5.833 0.5 Z" fill="url(%23t2lXByE48-2031533640-linear-gradient)" height="10.66671px" id="t2lXByE48" transform="translate(2 4)" width="10.66663px"/><path d="M 2.667 0.333 C 2.667 0.149 2.517 0 2.333 0 C 2.149 0 2 0.149 2 0.333 C 2 0.987 1.855 1.382 1.618 1.618 C 1.382 1.855 0.987 2 0.333 2 C 0.149 2 0 2.149 0 2.333 C 0 2.517 0.149 2.667 0.333 2.667 C 0.987 2.667 1.382 2.811 1.618 3.048 C 1.855 3.285 2 3.68 2 4.333 C 2 4.517 2.149 4.667 2.333 4.667 C 2.517 4.667 2.667 4.517 2.667 4.333 C 2.667 3.68 2.811 3.285 3.048 3.048 C 3.285 2.811 3.68 2.667 4.333 2.667 C 4.517 2.667 4.667 2.517 4.667 2.333 C 4.667 2.149 4.517 2 4.333 2 C 3.68 2 3.285 1.855 3.048 1.618 C 2.811 1.382 2.667 0.987 2.667 0.333 Z" fill="url(%23CBS1bzkxF-2031533640-linear-gradient)" height="4.66667px" id="CBS1bzkxF" transform="translate(0 2.667)" width="4.66667px"/><path d="M 2 0.333 C 2 0.149 1.851 0 1.667 0 C 1.483 0 1.333 0.149 1.333 0.333 C 1.333 0.756 1.239 0.984 1.112 1.112 C 0.984 1.239 0.756 1.333 0.333 1.333 C 0.149 1.333 0 1.483 0 1.667 C 0 1.851 0.149 2 0.333 2 C 0.756 2 0.984 2.094 1.112 2.222 C 1.239 2.35 1.333 2.578 1.333 3 C 1.333 3.184 1.483 3.333 1.667 3.333 C 1.851 3.333 2 3.184 2 3 C 2 2.578 2.094 2.35 2.222 2.222 C 2.35 2.094 2.578 2 3 2 C 3.184 2 3.333 1.851 3.333 1.667 C 3.333 1.483 3.184 1.333 3 1.333 C 2.578 1.333 2.35 1.239 2.222 1.112 C 2.094 0.984 2 0.756 2 0.333 Z" fill="url(%23Jd7AK81w9-2031533640-linear-gradient)" height="3.333333px" id="Jd7AK81w9" transform="translate(4 0)" width="3.3333399999999997px"/></g></g></svg>)
" height="24px" id="WCm44spAV" width="24px"/><path d="M 3.892 7.742 C 1.674 7.742 0 6.014 0 3.882 C 0 1.738 1.589 0 3.892 0 C 5.107 0 5.951 0.374 6.623 1.173 L 5.566 2.09 C 5.118 1.621 4.564 1.386 3.892 1.386 C 2.452 1.386 1.547 2.517 1.547 3.882 C 1.547 5.246 2.452 6.356 3.924 6.356 C 4.649 6.356 5.193 6.111 5.63 5.63 L 6.718 6.558 C 6.153 7.24 5.193 7.742 3.892 7.742 Z" fill="rgb(255, 255, 255)" height="7.741500000000002px" id="XEPpGD7l5" transform="translate(4 8.25)" width="6.717999999999989px"/><path d="M 2.74 7.922 C 1.215 7.922 0 6.632 0 5.032 C 0 3.433 1.215 2.122 2.74 2.122 C 3.7 2.122 4.201 2.516 4.5 3.113 L 4.5 2.239 L 5.928 2.239 L 5.928 7.784 L 4.531 7.784 L 4.531 6.877 C 4.233 7.507 3.731 7.922 2.74 7.922 Z M 1.439 5.023 C 1.439 5.865 2.057 6.622 2.975 6.622 C 3.924 6.622 4.531 5.897 4.531 5.033 C 4.531 4.169 3.924 3.423 2.975 3.423 C 2.057 3.423 1.439 4.159 1.439 5.022 Z M 6.784 7.784 L 6.784 0 L 8.224 0 L 8.224 7.784 L 6.784 7.784 Z" fill="rgb(255, 255, 255)" height="7.9224997406005855px" id="lGDJupIUR" transform="translate(10.5 8)" width="8.223500194549558px"/></g></svg>)
" width="18px"><path d="M 2 8 C 0.895 8 0 7.105 0 6 L 0 2 C 0 0.895 0.895 0 2 0 L 6 0 C 7.105 0 8 0.895 8 2 L 8 6 C 8 7.105 7.105 8 6 8 Z" fill="transparent" height="8px" id="ZrCrI93dV" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" width="8px"/><path d="M 0 0 L 0 4 C 0 5.105 0.895 6 2 6 L 6 6" fill="transparent" height="6px" id="emltWYAiE" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" transform="translate(4 8)" width="6px"/><path d="M 2 8 C 0.895 8 0 7.105 0 6 L 0 2 C 0 0.895 0.895 0 2 0 L 6 0 C 7.105 0 8 0.895 8 2 L 8 6 C 8 7.105 7.105 8 6 8 Z" fill="transparent" height="8px" id="WpBecYDfi" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" transform="translate(10 10)" width="8px"/></g></svg>)

Ingeniería en 2026 y más allá
Estamos construyendo infraestructura que casi nunca debe fallar. Para lograrlo, nos movemos rápidamente mientras lanzamos software de calidad increíble sin atajos ni compromisos. Este documento describe los estándares de ingeniería que nos guiarán hasta 2026 y más allá.

Estructura del Equipo
Nuestra organización de ingeniería consta de cinco equipos principales, cada uno con responsabilidades distintas:
Equipo de Fundación: Se enfoca en establecer y mantener estándares de codificación y patrones arquitectónicos. Este equipo trabaja de manera colaborativa con otros equipos para establecer las mejores prácticas a lo largo de la organización.
Equipos de Consumidor, Empresa y Plataforma: Equipos enfocados en el producto que lanzan características rápidamente mientras mantienen los estándares de calidad establecidos en este documento. Estos equipos demuestran que la velocidad y la calidad no son mutuamente excluyentes.
Equipo de Comunidad: Responsable de revisar rápidamente los PRs de la comunidad de código libre, proporcionar retroalimentación y guiar ese trabajo hasta la fusión. Este equipo se asegura de que nuestros colaboradores de código libre tengan una gran experiencia y de que sus contribuciones cumplan con nuestros estándares de calidad.
Nuestros Resultados Hasta Ahora
Los datos hablan por sí mismos. En el último año y medio, hemos transformado fundamentalmente cómo construimos software:
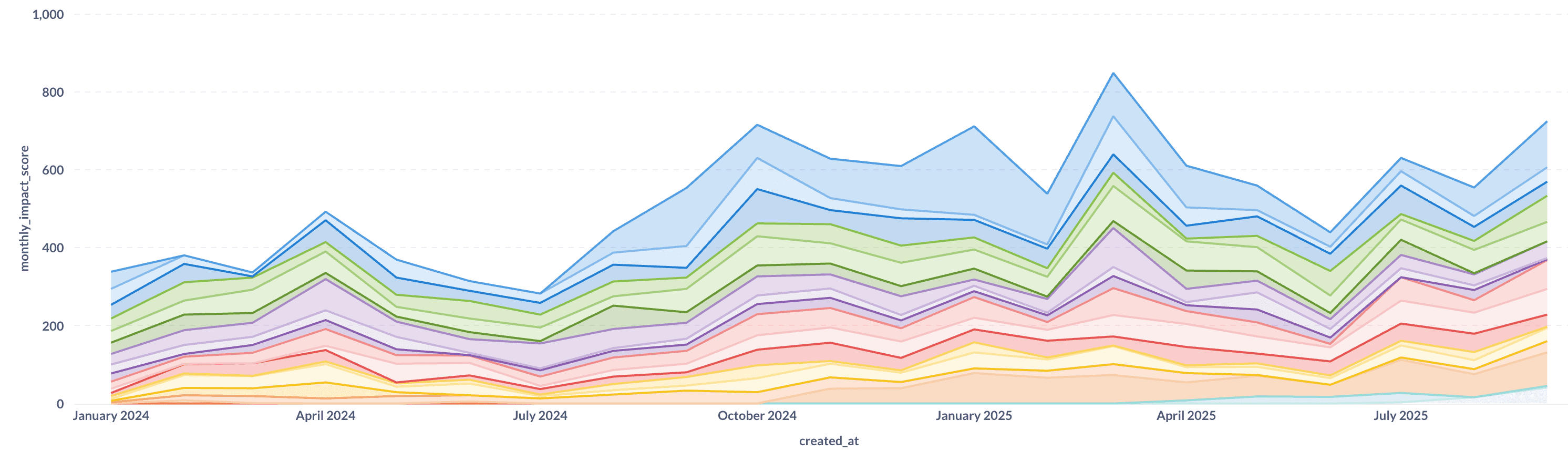
Hemos duplicado aproximadamente nuestro rendimiento de ingeniería mientras mejoramos simultáneamente la calidad. Aún más impresionante es el cambio en lo que estamos construyendo:
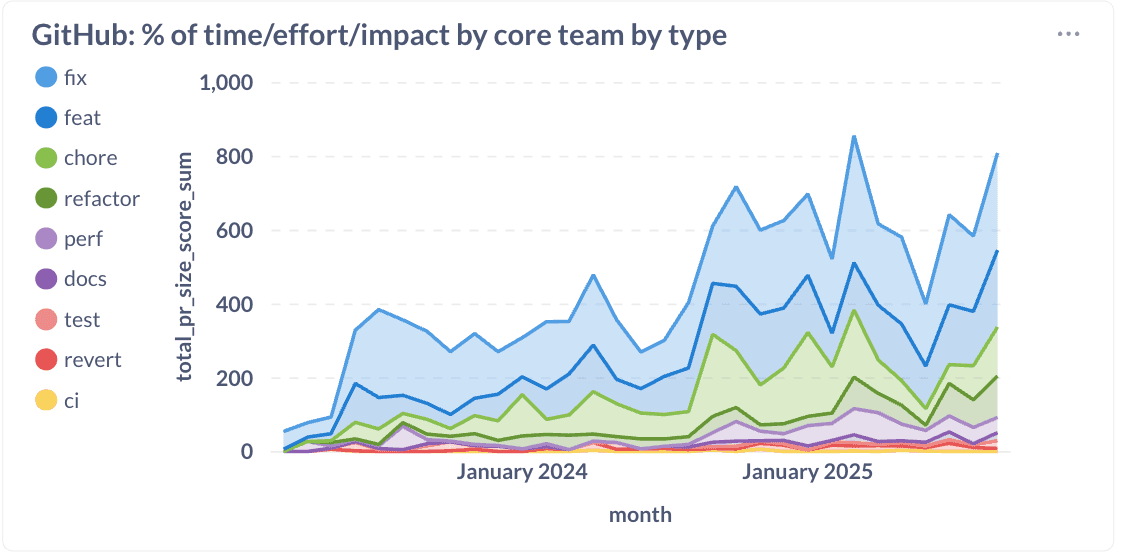
Hemos reasignado con éxito aproximadamente el 20% del esfuerzo de ingeniería de solucionarse problemas hacia características, mejoras de rendimiento, refactorizaciones y tareas. Este cambio demuestra que invertir en calidad y arquitectura no te ralentiza. Te acelera.
La Fundación de Cal.com Permite la Excelencia para coss.com
Cal.com es un negocio estable y rentable que continuaremos haciendo crecer.
Este éxito nos da una ventaja única mientras construimos coss.com. A diferencia de los primeros días de Cal.com, donde necesitábamos movernos rápidamente para establecer un ajuste producto-mercado y construir un negocio sostenible, coss.com comienza desde una posición de fuerza.
No necesitamos apresurar coss.com.
La estabilidad de Cal.com significa que podemos permitirnos construir coss.com de la manera correcta desde el primer día. Tenemos el lujo de implementar estos estándares de ingeniería sin la presión de las demandas inmediatas del mercado o restricciones de financiación. Esta es una posición de inicio fundamentalmente diferente.
La "lentitud" es una inversión, no un costo.
Sí, seguir estos estándares puede parecer más lento inicialmente e incluso puede ser frustrante para algunos ingenieros. Escribir DTOs lleva más tiempo que pasar tipos de base de datos directamente al frontend. Crear abstracciones adecuadas e inyección de dependencias requiere más diseño inicial. Mantener una cobertura de pruebas de más del 80% para el nuevo código requiere disciplina. Pero esta aparente lentitud es temporal y el beneficio es exponencial.
Considera los rendimientos compuestos...
El código que está arquitectado correctamente desde el principio no necesita grandes refactorizaciones más adelante
El alta cobertura de pruebas previene errores que de otro modo consumirían semanas de depuración y correcciones rápidas (ver 2023 a mediados de 2024)
Las abstracciones adecuadas hacen que agregar nuevas características sea mucho más rápido con el tiempo
Los límites claros y los DTOs prevenen la erosión arquitectónica que eventualmente exige reescrituras completas
La trayectoria de Cal.com muestra lo que ocurre cuando optimizas para la velocidad inmediata. Alta velocidad inicial que gradualmente se degrada a medida que la deuda técnica se acumula, los atajos arquitectónicos crean cuellos de botella y más tiempo se dedica a solucionar problemas que a construir características (ver gráfico anterior donde estábamos dedicando el 55-60% del esfuerzo de ingeniería a arreglos).
La trayectoria de coss.com abrazará el poder de construir correctamente desde el primer día. Velocidad inicial ligeramente más lenta mientras se establecen los patrones adecuados, seguida de una aceleración exponencial a medida que estos patrones dan dividendos y permiten un desarrollo más rápido con mayor confianza.
Principios Fundamentales
1. No diferir la calidad
Minimizaremos "Lo haré en un PR de seguimiento" para pequeñas refactorizaciones.
Los PRs de seguimiento para mejoras menores rara vez se materializan. En cambio, se acumulan como deuda técnica que nos agobia meses o años después. Si se puede hacer una pequeña refactorización ahora, hazlo ahora. Los seguimientos deben reservarse para cambios importantes que genuinamente justifiquen PRs separados o para casos excepcionales y urgentes.
2. Altos estándares en la revisión de código
No dejes pasar PRs con muchos detalles solo para evitar ser "la persona mala".
Esto es precisamente como se vuelven descuidados los bases de código con el tiempo. La revisión de código no se trata de ser amable. Se trata de mantener los estándares de calidad que demanda nuestra infraestructura. Cada detalle importa. Cada violación de patrón importa. Abórdalos antes de hacer la fusión, no después.
3. Empujarnos mutuamente a hacer lo correcto
Nos responsabilizamos mutuamente por la calidad
Tomar atajos podría parecer más rápido en el momento, pero crea problemas que ralentizan a todos más adelante. Cuando veas a un compañero de equipo a punto de fusionar un PR con problemas evidentes, habla. Cuando alguien sugiera un hack rápido en lugar de la solución adecuada, opónte. Cuando tengas la tentación de omitir pruebas o ignorar patrones arquitectónicos, espera que tus compañeros te desafíen.
Esto no se trata de ser difícil o ralentizar a las personas
Se trata de propiedad colectiva de nuestro base de código y nuestra reputación. Cada atajo que toma una persona se convierte en problema de todos. Cada esquina cortada hoy significa más sesiones de depuración, más correcciones rápidas y más clientes frustrados mañana.
Hacer que sea normal desafiar decisiones pobres, respetuosamente
Si alguien dice "simplemente codifiquemos esto por ahora", la respuesta esperada debe ser "¿qué se necesitaría para hacerlo bien la primera vez?". Si alguien quiere comprometer código que no ha sido probado, el equipo debe oponerse. Si alguien sugiere copiar y pegar en lugar de crear una abstracción adecuada, resáltalo respetuosamente.
Estamos construyendo algo que casi nunca debe fallar
Esa nivel de fiabilidad no ocurre por accidente. Ocurre cuando cada ingeniero se siente responsable de la calidad, no solo del propio código sino del sistema completo. Triunfamos como equipo o fallamos como equipo.
4. Apuntar a la simplicidad
Priorizar la claridad sobre la astucia
El objetivo es código fácil de leer y entender rápidamente, no complejidad elegante. Los sistemas simples reducen la carga cognitiva para cada ingeniero.
Hacerte las preguntas correctas
¿Estoy realmente resolviendo el problema en cuestión?
¿Estoy pensando demasiado en posibles casos de uso futuros?
¿He considerado al menos 1 otra alternativa para resolver esto? ¿Cómo se compara?
Simplicidad no significa carencia de características
Solo porque nuestro objetivo es crear sistemas simples, esto no significa que deban sentirse anémicos y carentes de funcionalidades obvias.
5. Automatizar todo
Aprovechar la IA
Generar el 80% de código de plantilla y no crítico utilizando IA, permitiéndonos centrarnos únicamente en lógica empresarial compleja y arquitecturas críticas.
Construir manejo de errores inteligentes y alertas sin ruido.
Las pruebas manuales son cada vez más obsoletas. La IA puede construir rápidamente y de manera inteligente mega suites de pruebas para nosotros.
Nuestro CI es el jefe final
Todo en este documento de estándares se verifica antes de que el código sea fusionado en PRs
No hay sorpresas que lleguen a la rama principal
Las comprobaciones son rápidas y útiles
Estándares Arquitectónicos
Estamos en transición hacia un modelo arquitectónico estricto basado en Arquitectura de Corte Vertical y Diseño Orientado al Dominio (DDD). Los siguientes patrones y principios se aplicarán rigurosamente en las revisiones de PR y mediante linters.
Arquitectura de Corte Vertical: paquetes/características
Nuestra base de código está organizada por dominio, no por capa técnica. El directorio packages/features es el corazón de este enfoque arquitectónico. Cada carpeta dentro representa un corte vertical completo de la aplicación, impulsado por el dominio que toca.
Estructura:
Cada carpeta de características es un corte vertical autónomo que incluye todo lo necesario para ese dominio:
Lógica de dominio: Las reglas de negocio y entidades principales específicas de esa característica
Servicios de aplicación: Orquestación de casos de uso para ese dominio
Repositorios: Acceso a datos específicos para las necesidades de esa característica
DTOs: Objetos de transferencia de datos para cruzar límites
Componentes UI: Componentes frontend relacionados con esta característica (donde sea aplicable)
Pruebas: Pruebas de unidad, integración y E2E para esta característica
Por Qué Importan los Cortes Verticales
La arquitectura en capas tradicional se organiza por preocupaciones técnicas:
Esto crea varios problemas:
Los cambios en una característica requieren tocar archivos dispersos en múltiples directorios
Es difícil entender lo que hace una característica porque su código está fragmentado
Los equipos se pisan los pies cuando trabajan en diferentes características
No puedes extraer o desaprobar fácilmente una característica
La arquitectura de corte vertical se organiza por dominio:
Esto soluciona estos problemas:
Todo lo relacionado con la disponibilidad vive en
packages/features/availabilityPuedes entender toda la característica de disponibilidad explorando un solo directorio
Los equipos pueden trabajar en diferentes características sin conflictos (si el equipo de ingeniería de Cal.com crece, pero ciertamente en coss.com tendremos equipos que asuman paquetes importantes)
Las características están poco acopladas y pueden evolucionar de forma independiente
Guías para la Organización de Características
En teoría, cada característica es independientemente desplegable. Aunque quizás no las despleguemos por separado, organizarlas de esta manera nos obliga a mantener claros los dependencias y el acoplamiento mínimo. Esta es la premisa y el éxito de los micro-servicios, aunque aún no desplegaremos micro-servicios.
Las características se comunican a través de interfaces bien definidas. Si bookings necesita datos de availability, los importa desde @calcom/features/availability a través de las interfaces exportadas, no accediendo a detalles de implementación internos.
El código compartido vive en los lugares apropiados:
Utilidades agnósticas de dominio e inquietudes transversales (auth, logging):
packages/libPrimitivos UI compartidos:
packages/ui(y próximamente coss.com ui)
Los límites de dominio se aplican automáticamente. Construiremos linting que prevenga acceder a los internos de las características donde no deberías estar permitido. Si packages/features/bookings intenta importar desde packages/features/availability/services/internal, el linter lo bloqueará. Todas las dependencias inter-características deben pasar a través de la API pública de la característica.
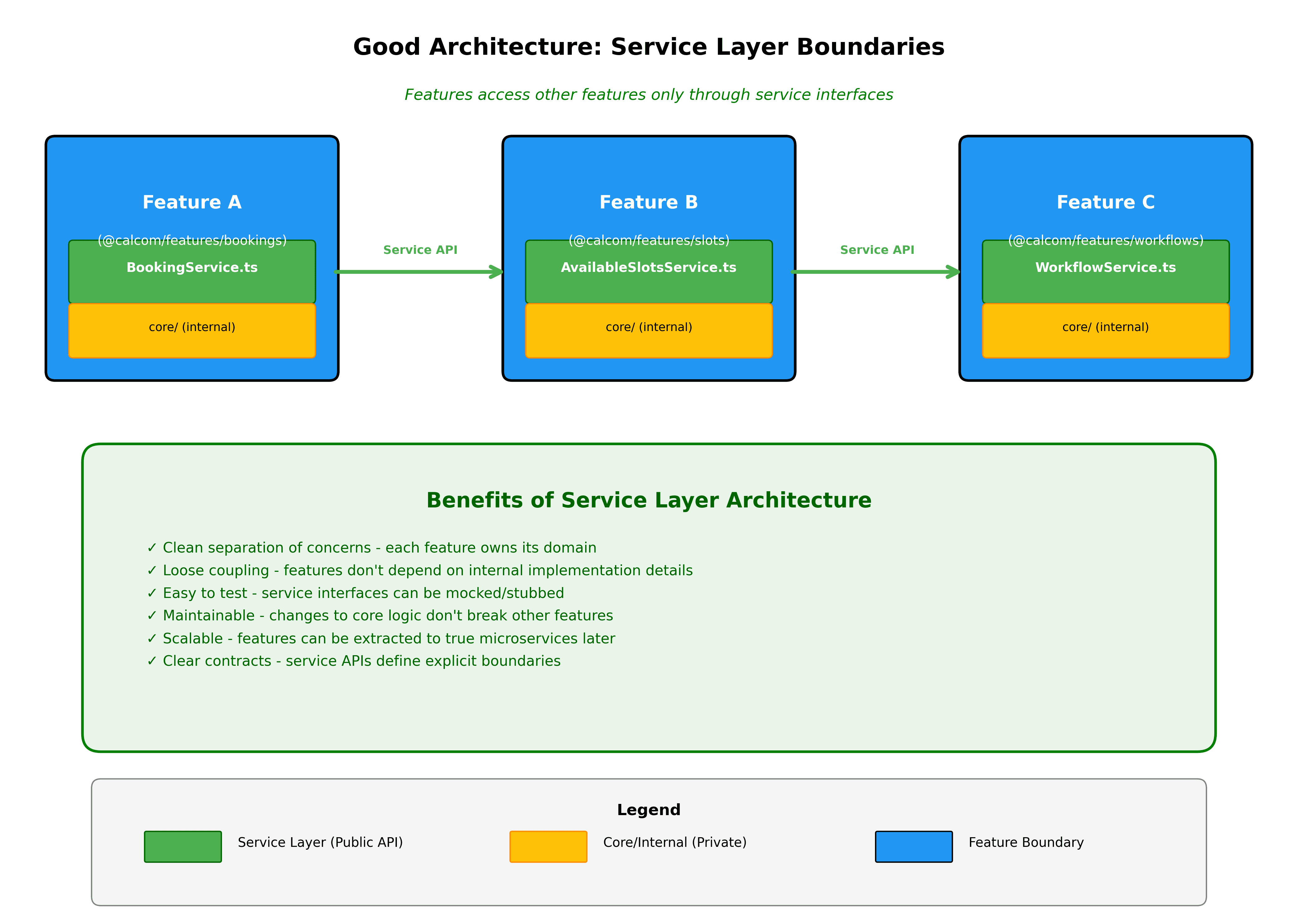
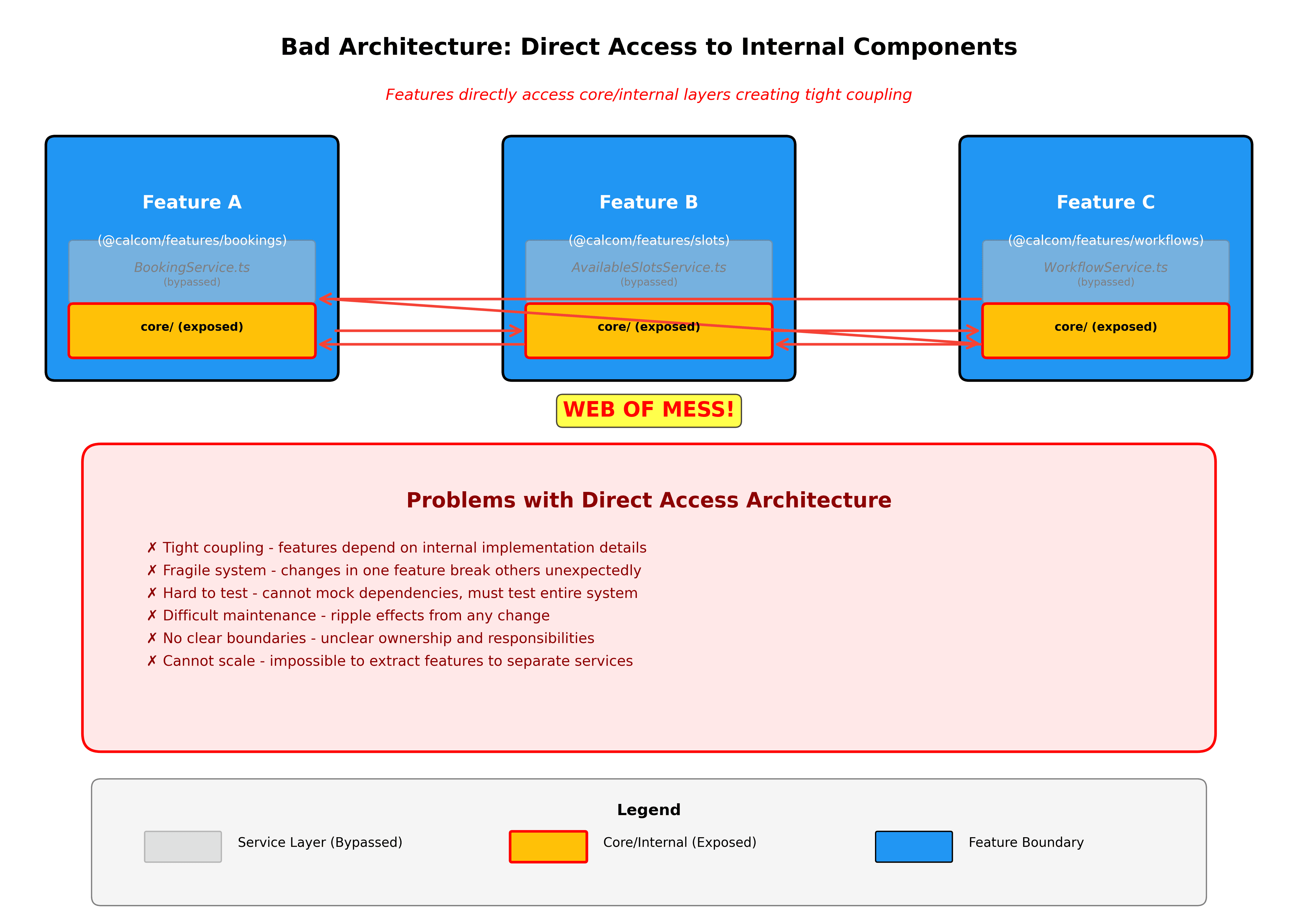
Las nuevas características comienzan como cortes verticales. Al construir algo nuevo, crea una nueva carpeta en packages/features con el corte vertical completo. Esto deja en claro qué estás construyendo y mantiene todo organizado desde el primer día.
Beneficios
Capacidad de descubrimiento
¿Buscas lógica de reserva? Está todo en
packages/features/bookings. No hay necesidad de buscar a través de controladores, servicios, repositorios y utilidades dispersas por toda la base de código.
Pruebas más fáciles
Pruébala característica completa como unidad. Tienes todas las piezas en un solo lugar, haciendo que las pruebas de integración sean naturales y sencillas.
Dependencias más claras
Cuando ves
import { getAvailability } from '@calcom/features/availability', sabes exactamente de qué característica estás dependiendo. Cuando las dependencias se vuelven demasiado complejas, es obvio y se puede abordar.
Patrón de Repositorio y Inyección de Dependencias
Las elecciones tecnológicas no deben filtrarse a través de la aplicación. El problema de Prisma lo ilustra perfectamente. Actualmente tenemos referencias a Prisma dispersas en cientos de archivos. Esto crea un gran acoplamiento y hace que los cambios tecnológicos sean prohibitivamente caros. Estamos sintiendo el dolor de esto ahora al actualizar Prisma a v6.16. Algo que debería haber sido solo un refactorización localizada detrás de repositorios protegidos se ha convertido en una persecución intrincada y casi interminable de problemas a través de múltiples aplicaciones.
El estándar en adelante:
Todo acceso a la base de datos debe pasar por clases de Repositorio. Ya tenemos una buena ventaja en esto.
Los repositorios son el único código que sabe sobre Prisma (o cualquier otro ORM). No debería haber lógica en ellos.
Los repositorios son inyectados a través de contenedores de Inyección de Dependencias
Si alguna vez cambiáramos de Prisma a Drizzle u otro ORM, los únicos cambios requeridos serían:
Implementaciones de repositorios
Conexiones del contenedor DI para nuevos repositorios
Nada más en la base de código debería preocuparse o cambiar
Esto no es teórico. Así es como construimos sistemas mantenibles.
Objetos de Transferencia de Datos (DTOs)
Los tipos de base de datos no deben filtrarse al frontend. Esto se ha convertido en un atajo popular en nuestro stack tecnológico, pero es un olor a código que crea múltiples problemas.
Acoplamiento tecnológico (tipos de Prisma terminando en componentes de React)
Riesgos de seguridad (fuga accidental de campos sensibles)
Contratos frágiles entre servidor y cliente (esto es particularmente problemático a medida que construimos muchas más APIs)
Incapacidad para evolucionar el esquema de la base de datos de forma independiente
Todas las conversiones de DTOs a través de Zod, incluso para una respuesta API para asegurarnos de que se está validando toda la data antes de enviarla al usuario. Es mejor fallar que devolver algo incorrecto.
El estándar de ahora en adelante:
Crea DTOs explícitos en cada límite arquitectónico.
Capa de Datos → Capa de Aplicación → API: Transforma modelos de bases de datos en DTOs de la capa de aplicación, luego transforma DTOs de la aplicación en DTOs específicos de API
API → Capa de Aplicación → Capa de Datos: Transforma DTOs de API a través de la capa de aplicación y en DTOs específicos de datos
Sí, esto requiere más código. Sí, vale la pena. Los límites explícitos prevenen la erosión arquitectónica que crea pesadillas de mantenimiento a largo plazo.
Patrones de Diseño Orientado al Dominio
Los siguientes patrones deben ser usados correctamente y de manera consistente:
Servicios de Aplicación
Orquestar casos de uso, coordinar entre servicios de dominio y repositorios
Servicios de Dominio
Contienen lógica de negocios que no pertenece naturalmente a una sola entidad
Repositorios
Abstraer el acceso a datos, aislar elecciones tecnológicas
Inyección de Dependencias
Permitir un acoplamiento débil, facilitar las pruebas, aislar los intereses
Proxy de Caché
Envolver repositorios o servicios para agregar comportamiento de caché de manera transparente
No es la única forma de hacer caching, por supuesto, pero un buen punto de partida
Decoradores
Agregar preocupaciones transversales (registro, métricas, etc.) sin contaminar la lógica de dominio
Consistencia del Código
Nuestras bases de código deberían parecer como si una persona las escribiera. Este nivel de consistencia requiere una estricta adherencia a los patrones establecidos, reglas integrales de linting que impongan estándares arquitectónicos revisiones de código que rechacen violaciones de patrones + la ayuda de revisores de código AI.
Mover Condicionales al Punto de Entrada de la Aplicación
Las sentencias If pertenecen al punto de entrada, no dispersas por tus servicios. Este es uno de los principios arquitectónicos más importantes para mantener un código limpio y enfocado que no se torne en complejidad inmantenible.
Así es como un código se degrada con el tiempo: Un servicio se escribe para un propósito claro y específico. La lógica es limpia y enfocada. Luego llega un nuevo requisito de producto, y alguien agrega una sentencia if. Unos años y varios requisitos después, ese servicio está plagado de comprobaciones condicionales para diferentes escenarios. El servicio se ha convertido en:
Complicado y difícil de leer
Dificultoso de entender y razonar
Más susceptible a errores
Violando la responsabilidad única (manejando demasiados casos diferentes)
Casi imposible de probar a fondo
El servicio ha excedido sus límites en términos de responsabilidades y lógica.
Una Solución: Patrón de Fábrica con Servicios Especializados
Utiliza el patrón de fábrica para tomar decisiones en el punto de entrada, luego delega a servicios especializados que manejan su lógica específica sin condicionales.
Ejemplo de nuestro base de código:
El BillingPortalServiceFactory determina si la facturación es para una organización, equipo o usuario individual, luego devuelve el servicio apropiado:
Cada servicio maneja su lógica específica sin necesidad de comprobar "¿soy una organización o un equipo?":
Por Qué Esto Importa
Los servicios mantienen su enfoque
Cada servicio tiene una responsabilidad y no necesita saber sobre otros contextos. El
OrganizationBillingPortalServiceno contiene sentencias if verificandoif (isTeam)oif (isUser). Solo sabe cómo manejar organizaciones.
Los cambios están aislados
Cuando necesitas modificar la lógica de facturación de la organización, solo tocas
OrganizationBillingPortalService. No corres el riesgo de romper la facturación de equipos o usuarios. No necesitas seguir condicionales anidados para averiguar qué camino toma tu código.
Las pruebas son directas
Prueba cada servicio independientemente con sus escenarios específicos. No necesitas probar cada combinación de condicionales en diferentes contextos.
Los nuevos requisitos no contaminan el código existente
por ejemplo, cuando necesitas agregar facturación empresarial con reglas diferentes, creas
EnterpriseBillingPortalService. La fábrica gana una condicional más, pero los servicios existentes permanecen intocados y enfocados.
Cómo Lograrlo
Empuja las condicionales hacia los controladores, fábricas o lógica de enrutamiento. Deja que estos puntos de entrada tomen decisiones sobre qué servicio usar.
Mantén los servicios puros y enfocados en una única responsabilidad. Si un servicio necesita comprobar "¿qué tipo soy?", probablemente necesites múltiples servicios.
Prefiere polimorfismo sobre condicionales
Las interfaces definen el contrato. Las implementaciones concretas proporcionan los detalles.
Vigila la acumulación de declaraciones if
Durante la revisión de código, si ves que un servicio gana condicionales para diferentes escenarios, esa es una señal de que debes refactorizar en servicios especializados.
Diseño de API: Controladores Delgados y Abstracción HTTP
Los controladores son capas delgadas que manejan solo preocupaciones HTTP.
Reciben solicitudes, las procesan, y mapean datos a DTOs que se pasan a la lógica central de la aplicación. De ahora en adelante, no se debe ver lógica de aplicación o central en rutas API o manejadores tRPC.
Debemos despegar la tecnología HTTP de nuestra aplicación.
La forma en que transferimos datos entre cliente y servidor (ya sea REST, tRPC, etc.) no debe influir en cómo funciona nuestra aplicación central. HTTP es un mecanismo de entrega, no un impulsor arquitectónico.
Responsabilidades del controlador (y SOLO estas):
Recibir y validar solicitudes entrantes
Extraer datos de parámetros de solicitud, cuerpo, encabezados
Transformar datos de solicitud en DTOs
Llamar a los servicios de aplicación apropiados con esos DTOs
Transformar las respuestas de los servicios de la aplicación en DTOs de respuesta
Devolver respuestas HTTP con códigos de estado apropiados
Los controladores no deben:
Contener lógica de negocio o reglas de dominio
Acceder directamente a bases de datos o servicios externos
Realizar transformaciones de datos complejas o cálculos
Tomar decisiones sobre lo que la aplicación debe hacer
Saber detalles de implementación del dominio
Ejemplo del patrón controlador delgado:
Versionado de API y Cambios críticos
No hay cambios críticos. Esto es crítico. Una vez que un endpoint de API es público, debe permanecer estable. Los cambios críticos destruyen la confianza del desarrollador y crean pesadillas de integración para nuestros usuarios.
Estrategias para evitar cambios críticos:
Sempre añadí novos campos como opcionales
Utiliza versionado de API cuando debes cambiar el comportamiento existente
Deprecia endpoints antiguos de manera elegante con caminos claros de migración
Mantén la compatibilidad hacia atrás durante al menos dos versiones mayores
Cuando debes hacer cambios críticos:
Crea una nueva versión de API utilizando el versionado específico por fecha en la API v2 (quizás también miremos el versionado por nombre que Stripe recientemente introdujo)
Ejecuta ambas versiones simultáneamente durante la transición (ya hacemos esto en la API v2)
Proporciona herramientas de migración automatizadas cuando sea posible
Da a los usuarios tiempo suficiente para migrarse (mínimo seis meses para API públicas)
Documenta exactamente qué cambió y por qué
Rendimiento y Complejidad Algorítmica
Construimos para grandes organizaciones y equipos. Lo que funciona bien con 10 usuarios o 50 registros puede colapsar bajo el peso de la escala empresarial. El rendimiento no es algo que optimizamos más tarde. Es algo que construimos correctamente desde el principio.
Pensar en la Escala Desde el Primer Día
Al construir características, pregúntate siempre: "¿Cómo se comporta esto con 1,000 usuarios? 10,000 registros? 100,000 operaciones?" La diferencia entre algoritmos O(n) y O(n²) puede ser imperceptible en desarrollo, pero catastrófica en producción.
Patrones comunes O(n²) a evitar:
Iteraciones anidadas de matriz (
.mapdentro de.map,.forEachdentro de.forEach)Métodos de matriz como
.some,.find, o.filterdentro de bucles o callbacksVerificar cada elemento contra cada otro elemento sin optimización
Filtros encadenados o mapeado anidados sobre listas grandes
Ejemplo del mundo real: Para 100 espacios disponibles y 50 períodos ocupados, un algoritmo O(n²) realiza 5,000 verificaciones. Aumenta eso a 500 espacios y 200 períodos ocupados, y estás realizando 100,000 operaciones. Eso es un aumento de carga computacional de 20 veces para solo un aumento de datos de 5 veces.
Elige las Estructuras de Datos y Algoritmos Correctos
La mayoría de los problemas de rendimiento se resuelven eligiendo mejores estructuras de datos y algoritmos:
Ordenado + salida temprana: Ordena tus datos una vez, luego rompe los bucles cuando sepas que los elementos restantes no coincidirán
Búsqueda binaria: Utiliza búsqueda binaria para búsquedas en matrices ordenadas en lugar de escaneos lineales
Técnicas de dos pointers: Para fusionar o intersectar secuencias ordenadas, camina a través de ambas con pointers en lugar de bucles anidados
Mapas/sets hash: Usa objetos o conjuntos para búsquedas O(1) en lugar de
.findo.includesen matricesÁrboles de intervalos: Para programación de horarios, disponibilidad y consultas de rango, usa estructuras de árbol adecuadas en lugar de comparación exhaustiva
Transformación de ejemplo:
Comprobaciones de Rendimiento Automatizadas
Implementaremos múltiples capas de defensa contra regresiones de rendimiento:
Reglas de linting que marcan:
Funciones con bucles anidados o métodos de matriz anidados
Llamadas múltiples a
.someanidadas,.find, o.filterRecursión sin memoización
Patrones conocidos anti-patrón para nuestro dominio (programación, comprobaciones de disponibilidad, etc.)
Pruebas de rendimiento en CI que:
Ejecutan algoritmos críticos sobre datos realistas y a gran escala
Comparan tiempos de ejecución contra una línea base en cada PR
Bloquean fusiones que introducen regresiones de rendimiento
Prueba con datos a nivel empresarial (miles de usuarios, decenas de miles de registros)
Monitoreo de producción que:
Rastrea el tiempo de ejecución para rutas críticas
Alerta cuando los algoritmos se desaceleran a medida que crecen los datos
Detecta regresiones antes de que los usuarios lo noten
Proporciona datos de rendimiento del mundo real para informar las optimizaciones
El Rendimiento es una Característica
El rendimiento no es opcional. No es algo que "abordamos más tarde". Para clientes empresariales reservando a través de grandes equipos, respuestas lentas significan productividad perdida y usuarios frustrados (nuestra experiencia con algunos clientes empresariales más grandes puede dar testimonio de esto).
Cada ingeniero debería:
Perfila tu código antes de optimizar, pero piensa en la complejidad desde el principio
Prueba con datos realistas a gran escala (no solo 5 registros de prueba). Ya hemos construido scripts de seed. Probablemente necesitemos extenderlos.
Elige algoritmos y estructuras de datos eficientes desde el principio
Observa las iteraciones anidadas en la revisión de código
Cuestiona cualquier algoritmo que escale con el producto de dos variables
La Dura Realidad NP de la Programación
Los problemas de programación son fundamentalmente NP-duros. Esto significa que a medida que crece el número de restricciones, participantes, o espacios de tiempo, la complejidad computacional puede explotar exponencialmente. La mayoría de los algoritmos de programación óptima tienen un peor de los casos de complejidad de tiempo exponencial, lo que hace que la elección del algoritmo sea absolutamente crítica.
Implicaciones del mundo real:
Encontrar el tiempo de reunión óptimo para 10 personas a través de 3 zonas horarias con restricciones de disponibilidad individual es computacionalmente costoso
Agregar detección de conflictos, buffers, y una multitud de otras opciones amplifica el problema
Elecciones de algoritmos pobres que funcionan bien para equipos pequeños se vuelven completamente inusuales para grandes organizaciones
Lo que toma milisegundos para 5 usuarios puede tardar muchos segundos para organizaciones
Estrategias para manejar la complejidad NP-dura:
Usa algoritmos de aproximación que encuentran soluciones "suficientemente buenas" rápidamente en lugar de soluciones perfectas lentamente
Implementa un almacenamiento en caché agresivo de programas de computación y disponibilidad
Precomputar escenarios comunes durante horas no pico
Dividir problemas de programación grandes en trozos más pequeños y manejables
Establecer límites de tiempo razonables y recurrir a algoritmos más simples cuando sea necesario
Esta es la razón por la que el rendimiento no es solo algo agradable de tener en el software de programación de horarios. Es la base que determina si tu sistema puede escalar a las necesidades empresariales o colapsa bajo patrones de uso del mundo real.
Requisitos de Cobertura de Código
Rastreo de cobertura global
Rastrearemos la cobertura total de la base de código como una métrica clave que mejora con el tiempo. Esto nos da visibilidad en nuestra madurez de pruebas y ayuda a identificar áreas que necesitan atención. El porcentaje de cobertura global se muestra destacadamente en nuestros tableros.
80%+ de cobertura para nuevo código
Cada PR debe tener un 80%+ de cobertura de pruebas para el código que introduce o modifica. Esto se aplica automáticamente en nuestra canalización de CI. Si agregas 50 líneas de nuevo código, esas 50 líneas deben estar cubiertas por pruebas. Si modificas una función existente, tus cambios deben ser probados. Esta es la cobertura general de pruebas. La cobertura de pruebas unitarias necesita estar cerca del 100%, especialmente con la capacidad de aprovechar la IA para ayudar a generar estas.
Abordando el argumento de que "la cobertura no es la historia completa": Sí, sabemos que la cobertura no garantiza pruebas perfectas. Sabemos que puedes escribir pruebas sin sentido que golpean cada línea pero no prueban nada significativo. Sabemos que la cobertura es solo una métrica entre muchas. Pero, seguramente es mejor apuntar a un porcentaje alto que no tener idea de dónde estás en absoluto.
Midiendo el Éxito
"Velocidad" (robando esto de Scrum aunque no usaremos Scrum)
Crecimiento continuo en estadísticas mensuales (características, mejoras, refactorizaciones)
Calidad
Reduce el esfuerzo de PR dedicado a arreglos del 35% actual al 20% o menos para finales de 2026 (calculado en función de cambios de archivo y adiciones/eliminaciones)
Salud arquitectónica
Métricas sobre adherencia a patrones, acoplamiento tecnológico, violaciones de límites
Eficiencia de revisión
PRs más pequeños, revisiones más rápidas, menos rondas de retroalimentación
Tiempo de actividad de la aplicación y API
¿Qué tan cerca estamos de 99.99%?

¡Comienza con Cal.com gratis hoy!
Experimenta una programación y productividad sin problemas, sin tarifas ocultas. ¡Regístrate en segundos y comienza a simplificar tu programación hoy, sin necesidad de tarjeta de crédito!



