" height="18.016311920580208px" id="GKXyVanMq" stroke-dasharray="0" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgb(0, 0, 0)" transform="translate(3 3)" width="18px"/></svg>)
"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient><linearGradient id="CBS1bzkxF-2031533640-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgb(255, 255, 255)"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient><linearGradient id="Jd7AK81w9-2031533640-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgb(255, 255, 255)"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient></defs><g d="M 0 16 L 0 0 L 16 0 L 16 16 Z M 9.167 5.167 C 9.167 4.891 8.943 4.667 8.667 4.667 C 8.391 4.667 8.167 4.891 8.167 5.167 C 8.167 6.784 7.809 7.834 7.155 8.488 C 6.501 9.143 5.451 9.5 3.833 9.5 C 3.557 9.5 3.333 9.724 3.333 10 C 3.333 10.276 3.557 10.5 3.833 10.5 C 5.451 10.5 6.501 10.857 7.155 11.512 C 7.809 12.166 8.167 13.216 8.167 14.833 C 8.167 15.109 8.391 15.333 8.667 15.333 C 8.943 15.333 9.167 15.109 9.167 14.833 C 9.167 13.216 9.524 12.166 10.178 11.512 C 10.832 10.857 11.883 10.5 13.5 10.5 C 13.776 10.5 14 10.276 14 10 C 14 9.724 13.776 9.5 13.5 9.5 C 11.883 9.5 10.832 9.143 10.178 8.488 C 9.524 7.834 9.167 6.784 9.167 5.167 Z M 4 3.667 C 4 3.483 3.851 3.333 3.667 3.333 C 3.483 3.333 3.333 3.483 3.333 3.667 C 3.333 4.32 3.189 4.715 2.952 4.952 C 2.715 5.189 2.32 5.333 1.667 5.333 C 1.483 5.333 1.333 5.483 1.333 5.667 C 1.333 5.851 1.483 6 1.667 6 C 2.32 6 2.715 6.145 2.952 6.382 C 3.189 6.618 3.333 7.013 3.333 7.667 C 3.333 7.851 3.483 8 3.667 8 C 3.851 8 4 7.851 4 7.667 C 4 7.013 4.145 6.618 4.382 6.382 C 4.618 6.145 5.013 6 5.667 6 C 5.851 6 6 5.851 6 5.667 C 6 5.483 5.851 5.333 5.667 5.333 C 5.013 5.333 4.618 5.189 4.382 4.952 C 4.145 4.715 4 4.32 4 3.667 Z M 7.333 1 C 7.333 0.816 7.184 0.667 7 0.667 C 6.816 0.667 6.667 0.816 6.667 1 C 6.667 1.422 6.573 1.65 6.445 1.778 C 6.317 1.906 6.089 2 5.667 2 C 5.483 2 5.333 2.149 5.333 2.333 C 5.333 2.517 5.483 2.667 5.667 2.667 C 6.089 2.667 6.317 2.761 6.445 2.889 C 6.573 3.016 6.667 3.244 6.667 3.667 C 6.667 3.851 6.816 4 7 4 C 7.184 4 7.333 3.851 7.333 3.667 C 7.333 3.244 7.427 3.016 7.555 2.889 C 7.683 2.761 7.911 2.667 8.333 2.667 C 8.517 2.667 8.667 2.517 8.667 2.333 C 8.667 2.149 8.517 2 8.333 2 C 7.911 2 7.683 1.906 7.555 1.778 C 7.427 1.65 7.333 1.422 7.333 1 Z" fill="transparent" height="16px" id="aoZYv33vR" width="16px"><path d="M 0 16 L 0 0 L 16 0 L 16 16 Z" fill="transparent" height="16px" id="Z2uGmhW9f" width="16px"/><g d="M 7.833 4.5 C 7.833 4.224 7.609 4 7.333 4 C 7.057 4 6.833 4.224 6.833 4.5 C 6.833 6.117 6.476 7.168 5.822 7.822 C 5.168 8.476 4.117 8.833 2.5 8.833 C 2.224 8.833 2 9.057 2 9.333 C 2 9.61 2.224 9.833 2.5 9.833 C 4.117 9.833 5.168 10.191 5.822 10.845 C 6.476 11.499 6.833 12.549 6.833 14.167 C 6.833 14.443 7.057 14.667 7.333 14.667 C 7.609 14.667 7.833 14.443 7.833 14.167 C 7.833 12.549 8.191 11.499 8.845 10.845 C 9.499 10.191 10.549 9.833 12.167 9.833 C 12.443 9.833 12.667 9.61 12.667 9.333 C 12.667 9.057 12.443 8.833 12.167 8.833 C 10.549 8.833 9.499 8.476 8.845 7.822 C 8.191 7.168 7.833 6.117 7.833 4.5 Z M 2.667 3 C 2.667 2.816 2.517 2.667 2.333 2.667 C 2.149 2.667 2 2.816 2 3 C 2 3.654 1.855 4.048 1.618 4.285 C 1.382 4.522 0.987 4.667 0.333 4.667 C 0.149 4.667 0 4.816 0 5 C 0 5.184 0.149 5.333 0.333 5.333 C 0.987 5.333 1.382 5.478 1.618 5.715 C 1.855 5.952 2 6.346 2 7 C 2 7.184 2.149 7.333 2.333 7.333 C 2.517 7.333 2.667 7.184 2.667 7 C 2.667 6.346 2.811 5.952 3.048 5.715 C 3.285 5.478 3.68 5.333 4.333 5.333 C 4.517 5.333 4.667 5.184 4.667 5 C 4.667 4.816 4.517 4.667 4.333 4.667 C 3.68 4.667 3.285 4.522 3.048 4.285 C 2.811 4.048 2.667 3.654 2.667 3 Z M 6 0.333 C 6 0.149 5.851 0 5.667 0 C 5.483 0 5.333 0.149 5.333 0.333 C 5.333 0.756 5.239 0.984 5.112 1.112 C 4.984 1.239 4.756 1.333 4.333 1.333 C 4.149 1.333 4 1.483 4 1.667 C 4 1.851 4.149 2 4.333 2 C 4.756 2 4.984 2.094 5.112 2.222 C 5.239 2.35 5.333 2.578 5.333 3 C 5.333 3.184 5.483 3.333 5.667 3.333 C 5.851 3.333 6 3.184 6 3 C 6 2.578 6.094 2.35 6.222 2.222 C 6.35 2.094 6.578 2 7 2 C 7.184 2 7.333 1.851 7.333 1.667 C 7.333 1.483 7.184 1.333 7 1.333 C 6.578 1.333 6.35 1.239 6.222 1.112 C 6.094 0.984 6 0.756 6 0.333 Z" fill="transparent" height="14.66671286102295px" id="ae6ccdFme" transform="translate(1.333 0.667)" width="12.66663px"><path d="M 5.833 0.5 C 5.833 0.224 5.609 0 5.333 0 C 5.057 0 4.833 0.224 4.833 0.5 C 4.833 2.117 4.476 3.168 3.822 3.822 C 3.168 4.476 2.117 4.833 0.5 4.833 C 0.224 4.833 0 5.057 0 5.333 C 0 5.61 0.224 5.833 0.5 5.833 C 2.117 5.833 3.168 6.191 3.822 6.845 C 4.476 7.499 4.833 8.549 4.833 10.167 C 4.833 10.443 5.057 10.667 5.333 10.667 C 5.609 10.667 5.833 10.443 5.833 10.167 C 5.833 8.549 6.191 7.499 6.845 6.845 C 7.499 6.191 8.549 5.833 10.167 5.833 C 10.443 5.833 10.667 5.61 10.667 5.333 C 10.667 5.057 10.443 4.833 10.167 4.833 C 8.549 4.833 7.499 4.476 6.845 3.822 C 6.191 3.168 5.833 2.117 5.833 0.5 Z" fill="url(%23t2lXByE48-2031533640-linear-gradient)" height="10.66671px" id="t2lXByE48" transform="translate(2 4)" width="10.66663px"/><path d="M 2.667 0.333 C 2.667 0.149 2.517 0 2.333 0 C 2.149 0 2 0.149 2 0.333 C 2 0.987 1.855 1.382 1.618 1.618 C 1.382 1.855 0.987 2 0.333 2 C 0.149 2 0 2.149 0 2.333 C 0 2.517 0.149 2.667 0.333 2.667 C 0.987 2.667 1.382 2.811 1.618 3.048 C 1.855 3.285 2 3.68 2 4.333 C 2 4.517 2.149 4.667 2.333 4.667 C 2.517 4.667 2.667 4.517 2.667 4.333 C 2.667 3.68 2.811 3.285 3.048 3.048 C 3.285 2.811 3.68 2.667 4.333 2.667 C 4.517 2.667 4.667 2.517 4.667 2.333 C 4.667 2.149 4.517 2 4.333 2 C 3.68 2 3.285 1.855 3.048 1.618 C 2.811 1.382 2.667 0.987 2.667 0.333 Z" fill="url(%23CBS1bzkxF-2031533640-linear-gradient)" height="4.66667px" id="CBS1bzkxF" transform="translate(0 2.667)" width="4.66667px"/><path d="M 2 0.333 C 2 0.149 1.851 0 1.667 0 C 1.483 0 1.333 0.149 1.333 0.333 C 1.333 0.756 1.239 0.984 1.112 1.112 C 0.984 1.239 0.756 1.333 0.333 1.333 C 0.149 1.333 0 1.483 0 1.667 C 0 1.851 0.149 2 0.333 2 C 0.756 2 0.984 2.094 1.112 2.222 C 1.239 2.35 1.333 2.578 1.333 3 C 1.333 3.184 1.483 3.333 1.667 3.333 C 1.851 3.333 2 3.184 2 3 C 2 2.578 2.094 2.35 2.222 2.222 C 2.35 2.094 2.578 2 3 2 C 3.184 2 3.333 1.851 3.333 1.667 C 3.333 1.483 3.184 1.333 3 1.333 C 2.578 1.333 2.35 1.239 2.222 1.112 C 2.094 0.984 2 0.756 2 0.333 Z" fill="url(%23Jd7AK81w9-2031533640-linear-gradient)" height="3.333333px" id="Jd7AK81w9" transform="translate(4 0)" width="3.3333399999999997px"/></g></g></svg>)
" height="24px" id="WCm44spAV" width="24px"/><path d="M 3.892 7.742 C 1.674 7.742 0 6.014 0 3.882 C 0 1.738 1.589 0 3.892 0 C 5.107 0 5.951 0.374 6.623 1.173 L 5.566 2.09 C 5.118 1.621 4.564 1.386 3.892 1.386 C 2.452 1.386 1.547 2.517 1.547 3.882 C 1.547 5.246 2.452 6.356 3.924 6.356 C 4.649 6.356 5.193 6.111 5.63 5.63 L 6.718 6.558 C 6.153 7.24 5.193 7.742 3.892 7.742 Z" fill="rgb(255, 255, 255)" height="7.741500000000002px" id="XEPpGD7l5" transform="translate(4 8.25)" width="6.717999999999989px"/><path d="M 2.74 7.922 C 1.215 7.922 0 6.632 0 5.032 C 0 3.433 1.215 2.122 2.74 2.122 C 3.7 2.122 4.201 2.516 4.5 3.113 L 4.5 2.239 L 5.928 2.239 L 5.928 7.784 L 4.531 7.784 L 4.531 6.877 C 4.233 7.507 3.731 7.922 2.74 7.922 Z M 1.439 5.023 C 1.439 5.865 2.057 6.622 2.975 6.622 C 3.924 6.622 4.531 5.897 4.531 5.033 C 4.531 4.169 3.924 3.423 2.975 3.423 C 2.057 3.423 1.439 4.159 1.439 5.022 Z M 6.784 7.784 L 6.784 0 L 8.224 0 L 8.224 7.784 L 6.784 7.784 Z" fill="rgb(255, 255, 255)" height="7.9224997406005855px" id="lGDJupIUR" transform="translate(10.5 8)" width="8.223500194549558px"/></g></svg>)
" width="18px"><path d="M 2 8 C 0.895 8 0 7.105 0 6 L 0 2 C 0 0.895 0.895 0 2 0 L 6 0 C 7.105 0 8 0.895 8 2 L 8 6 C 8 7.105 7.105 8 6 8 Z" fill="transparent" height="8px" id="ZrCrI93dV" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" width="8px"/><path d="M 0 0 L 0 4 C 0 5.105 0.895 6 2 6 L 6 6" fill="transparent" height="6px" id="emltWYAiE" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" transform="translate(4 8)" width="6px"/><path d="M 2 8 C 0.895 8 0 7.105 0 6 L 0 2 C 0 0.895 0.895 0 2 0 L 6 0 C 7.105 0 8 0.895 8 2 L 8 6 C 8 7.105 7.105 8 6 8 Z" fill="transparent" height="8px" id="WpBecYDfi" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" transform="translate(10 10)" width="8px"/></g></svg>)

Engenharia em 2026 e além
Estamos a construir uma infraestrutura que deve quase nunca falhar. Para alcançar isso, movemo-nos rapidamente enquanto lançamos software de qualidade incrível, sem atalhos ou compromissos. Este documento delineia os padrões de engenharia que nos guiarão até 2026 e além.

Estrutura de Equipas
A nossa organização de engenharia é composta por cinco equipas principais, cada uma com responsabilidades distintas:
Equipa de Base (Foundation Team): Foca-se em estabelecer e manter padrões de codificação e padrões de arquitetura. Esta equipa trabalha em colaboração com outras equipas para estabelecer as melhores práticas em toda a organização.
Equipas de Consumidor, Enterprise e Plataforma: Equipas focadas no produto que lançam funcionalidades rapidamente, mantendo ao mesmo tempo os padrões de qualidade definidos neste documento. Estas equipas provam que a velocidade e a qualidade não se excluem mutuamente.
Equipa Comunitária: Responsável por rever rapidamente os PRs da comunidade open source, fornecer feedback e encaminhar esse trabalho até à junção (merge). Esta equipa garante que os nossos contribuidores open source tenham uma excelente experiência e que as suas contribuições cumpram os nossos padrões de qualidade. Manter uma cultura forte de open-source continua a moldar a forma como o Cal.com aborda a colaboração em engenharia e o desenvolvimento de produtos.
Os Nossos Resultados Até Agora
Os dados falam por si. Ao longo do último ano e meio, transformámos fundamentalmente a forma como construímos software:
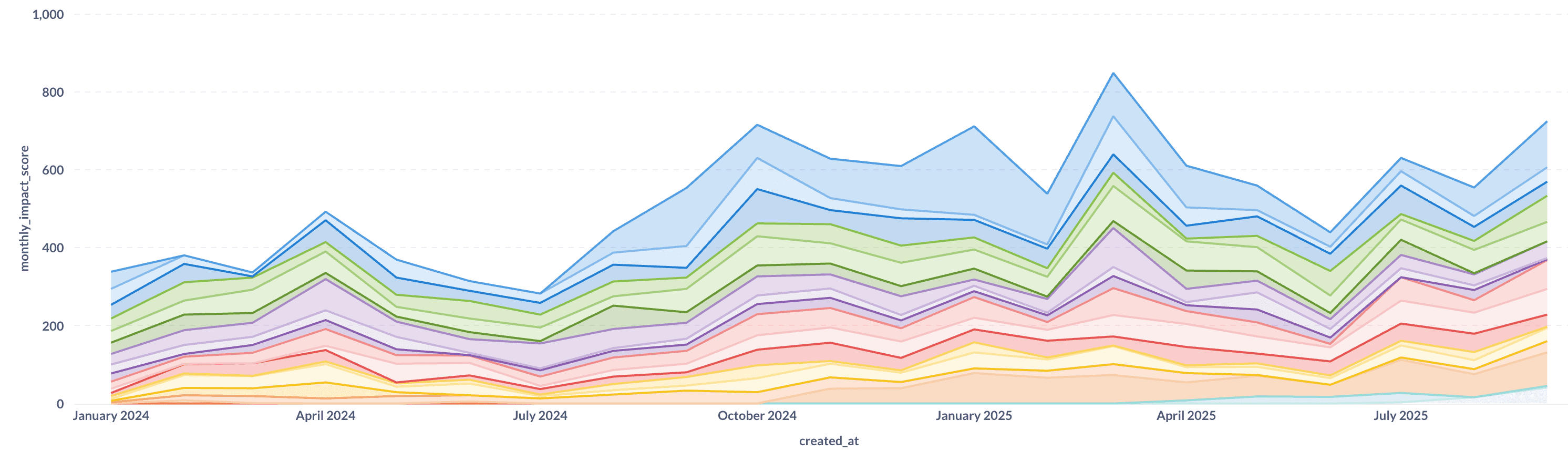
Aproximadamente duplicámos o nosso rendimento de engenharia e, simultaneamente, melhorámos a qualidade. Ainda mais impressionante é a mudança no que estamos a construir:
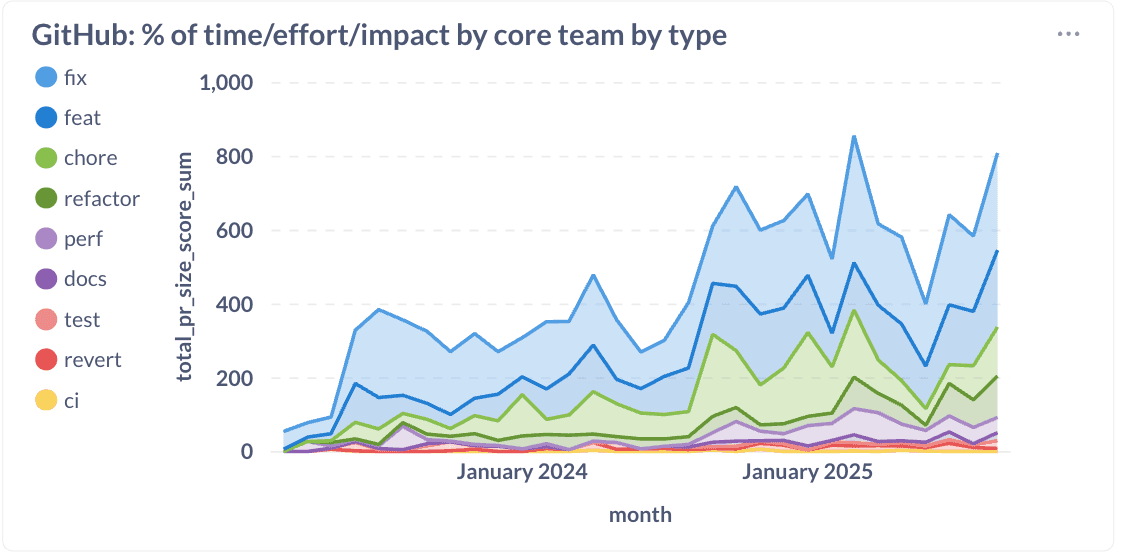
Realocámos com sucesso cerca de 20% do esforço de engenharia de correções para novas funcionalidades, melhorias de desempenho, refatorizações e tarefas de rotina. Esta mudança demonstra que investir em qualidade e arquitetura não o atrasa. Pelo contrário, acelera-o.
A Base do Cal.com Fornece Excelência para o coss.com
Cal.com é um negócio estável e lucrativo que continuaremos a fazer crescer.
Este sucesso dá-nos uma vantagem única à medida que construímos o coss.com. Ao contrário dos primeiros dias do Cal.com, onde precisávamos de nos mover rapidamente para estabelecer a adequação do produto ao mercado e construir um negócio sustentável, o coss.com começa a partir de uma posição de força.
Não precisamos de apressar o coss.com.
A estabilidade do Cal.com significa que nos podemos dar ao luxo de construir o coss.com da forma correta desde o primeiro dia. Temos o luxo de implementar estes padrões de engenharia sem a pressão de exigências imediatas do mercado ou restrições de financiamento. Esta é uma posição inicial fundamentalmente diferente.
A "lentidão" é um investimento, não um custo.
Sim, seguir estes padrões pode parecer mais lento inicialmente e pode até ser frustrante para alguns engenheiros. Escrever DTOs leva mais tempo do que passar tipos de base de dados diretamente para o frontend. Criar abstrações adequadas e injeção de dependências exige mais design inicial. Manter uma cobertura de testes superior a 80% para código novo exige disciplina. Mas esta aparente lentidão é temporária, e o retorno é exponencial.
Considere os retornos compostos...
O código que é arquitetado corretamente desde o início não precisa de refatorizações maciças mais tarde
Uma elevada cobertura de testes previne bugs que de outra forma consumiriam semanas de depuração e correções urgentes (ver de 2023 a meados de 2024)
As abstrações adequadas tornam a adição de novas funcionalidades dramaticamente mais rápida ao longo do tempo
Limites claros e DTOs previnem a erosão arquitetónica que eventualmente exige reescritas completas
A trajetória do Cal.com mostra o que acontece quando se otimiza para a velocidade imediata. Alta velocidade inicial que se degrada gradualmente à medida que a dívida técnica se acumula, atalhos arquitetónicos criam gargalos e mais tempo é gasto a corrigir problemas do que a construir funcionalidades (ver gráfico anterior onde estávamos a gastar 55-60% do esforço de engenharia em correções).
A trajetória do coss.com irá abraçar o poder de construir corretamente desde o primeiro dia. Uma velocidade inicial ligeiramente mais lenta enquanto se estabelecem os padrões adequados, seguida por uma aceleração exponencial à medida que esses padrões dão dividendos e permitem um desenvolvimento mais rápido com maior confiança.
Princípios Fundamentais
1. Sem qualidade diferida
Minimizaremos o "farei isso num PR de acompanhamento" para pequenas refatorizações.
Os PRs de acompanhamento para pequenas melhorias raramente se materializam. Em vez disso, acumulam-se como dívida técnica que nos sobrecarrega meses ou anos mais tarde. Se uma pequena refatorização puder ser feita agora, faça-a agora. Os acompanhamentos devem ser reservados para mudanças substanciais que genuinamente justifiquem PRs separados ou para casos excecionais e urgentes.
2. Altos padrões na revisão de código
Não deixe passar PRs com muitas pequenas objeções (nits) apenas para evitar ser "a pessoa má".
É precisamente assim que as bases de código se tornam descuidadas ao longo do tempo. A revisão de código não se trata de ser simpático. Trata-se de manter os padrões de qualidade que a nossa infraestrutura exige. Cada pequena correção importa. Cada violação de padrão importa. Resolva-as antes de fazer a junção (merge), não depois.
3. Impulsionar-se mutuamente a fazer a coisa certa
Responsabilizamo-nos mutuamente pela qualidade
Cortar caminhos pode parecer mais rápido no momento, mas cria problemas que atrasam toda a gente mais tarde. Quando vir um colega de equipa prestes a fundir um PR com problemas óbvios, fale. Quando alguém sugerir um truque rápido em vez da solução adequada, conteste. Quando se sentir tentado a saltar testes ou a ignorar padrões arquitetónicos, espere que os seus colegas o desafiem.
Isto não é sobre ser difícil ou atrasar as pessoas
Trata-se de propriedade coletiva da nossa base de código e da nossa reputação. Cada atalho que uma pessoa toma torna-se um problema de todos. Cada caminho cortado hoje significa mais sessões de depuração, mais correções urgentes e mais clientes frustrados amanhã.
Tornar normal a contestação de más decisões, de forma respeitosa
Se alguém disser "vamos apenas codificar isto de forma rígida (hard-code) por agora", a resposta esperada deve ser "o que seria necessário para fazer da forma correta à primeira?". Se alguém quiser submeter código não testado, a equipa deve contestar. Se alguém sugerir copiar e colar em vez de criar uma abstração adequada, aponte isso de forma respeitosa.
Estamos a construir algo que não pode quase nunca falhar
Esse nível de fiabilidade não acontece por acaso. Acontece quando cada engenheiro se sente responsável pela qualidade, não apenas do seu próprio código, mas de todo o sistema. Vencemos como equipa ou falhamos como equipa.
4. Procurar a simplicidade
Priorizar a clareza em detrimento da astúcia
O objetivo é obter um código que seja fácil de ler e compreender rapidamente, e não uma complexidade elegante. Sistemas simples reduzem a carga cognitiva de cada engenheiro.
Faça a si próprio as perguntas certas
Estou realmente a resolver o problema em questão?
Estou a pensar demasiado em possíveis casos de utilização futuros?
Considerei pelo menos mais 1 alternativa para resolver isto? Como se compara?
Simples não significa sem funcionalidades
Só porque o nosso objetivo é criar sistemas simples, isso não significa que devam parecer anémicos e sem funcionalidades óbvias.
5. Automatizar tudo
Aproveitar a IA
Gerar 80% de código padrão (boilerplate) e não crítico utilizando IA, permitindo focarmo-nos exclusivamente em lógica de negócio complexa e arquiteturas críticas. As equipas que adotam fluxos de trabalho modernos assistidos por IA dependem cada vez mais de ferramentas como os melhores servidores MCP para melhorar a produtividade e a orquestração dos programadores.
Construir alertas sem ruído e tratamento de erros inteligente.
O teste manual pertence cada vez mais ao passado. A IA pode construir de forma rápida e inteligente mega suítes de testes para nós.
O nosso CI é o chefe final
Tudo o que consta neste documento de padrões é verificado antes de o código ser fundido nos PRs
Não entram surpresas no branch principal
As verificações são rápidas e úteis
Padrões Arquitetónicos
Estamos a transitar para um modelo arquitetónico rigoroso baseado em Vertical Slice Architecture e Domain-Driven Design (DDD). Os seguintes padrões e princípios serão aplicados rigorosamente nas revisões de PR e através de análise estática (linting).
Vertical Slice Architecture: packages/features
A nossa base de código está organizada por domínio, não por camada técnica. O diretório packages/features é o coração desta abordagem arquitetónica. Cada pasta no seu interior representa uma fatia vertical completa da aplicação, impulsionada pelo domínio que toca.
Estrutura:
Cada pasta de funcionalidade (feature) é uma fatia vertical auto-suficiente que inclui tudo o que é necessário para esse domínio:
Lógica de domínio: As regras de negócio fundamentais e entidades específicas desse recurso
Serviços de aplicação: Orquestração de casos de utilização para esse domínio
Repositórios: Acesso a dados específico para as necessidades dessa funcionalidade
DTOs: Objetos de transferência de dados para cruzar fronteiras
Componentes de UI: Componentes do frontend relacionados com esta funcionalidade (onde aplicável)
Testes: Testes unitários, de integração e e2e para esta funcionalidade
Por que as Fatias Verticais Importam
A arquitetura em camadas tradicional organiza por preocupações técnicas:
Isto cria vários problemas:
Mudanças numa funcionalidade exigem alterar ficheiros espalhados por múltiplos diretórios
É difícil perceber o que uma funcionalidade faz porque o seu código está fragmentado
As equipas interferem no trabalho umas das outras ao trabalhar em funcionalidades diferentes
Não se consegue extrair ou descontinuar uma funcionalidade facilmente
A arquitetura de fatias verticais organiza por domínio:
Isto resolve estes problemas:
Tudo o que se relaciona com disponibilidade vive em
packages/features/availabilityPode compreender toda a funcionalidade de disponibilidade explorando apenas um diretório
As equipas podem trabalhar em funcionalidades diferentes sem conflitos (se a equipa de engenharia do Cal.com crescer, mas com toda a certeza no coss.com teremos equipas a assumir pacotes importantes)
As funcionalidades são fracamente acopladas e podem evoluir de forma independente
Diretrizes para Organização de Funcionalidades
Teoricamente, cada funcionalidade é implementável de forma independente. Embora possamos não as implementar separadamente na realidade, organizar desta forma força-nos a manter as dependências claras e o acoplamento mínimo. Esta é a premissa de sucesso dos microsserviços, embora ainda não estejamos a implementar microsserviços.
As funcionalidades comunicam através de interfaces bem definidas. Se as reservas precisarem de dados de disponibilidade, importam de @calcom/features/availability através de interfaces exportadas, e não acedendo a detalhes de implementação interna.
O código partilhado reside nos locais apropriados:
Utilitários agnósticos de domínio e preocupações transversais (autenticação, registo de logs):
packages/libPrimitivas de UI partilhadas:
packages/ui(e em breve coss.com ui)
Os limites do domínio são aplicados automaticamente. Construiremos linters para evitar o acesso a detalhes internos de funcionalidades às quais não deve ser permitido aceder. Se packages/features/bookings tentar importar de packages/features/availability/services/internal, o linter irá bloqueá-lo. Todas as dependências entre funcionalidades devem passar pela API pública da funcionalidade.
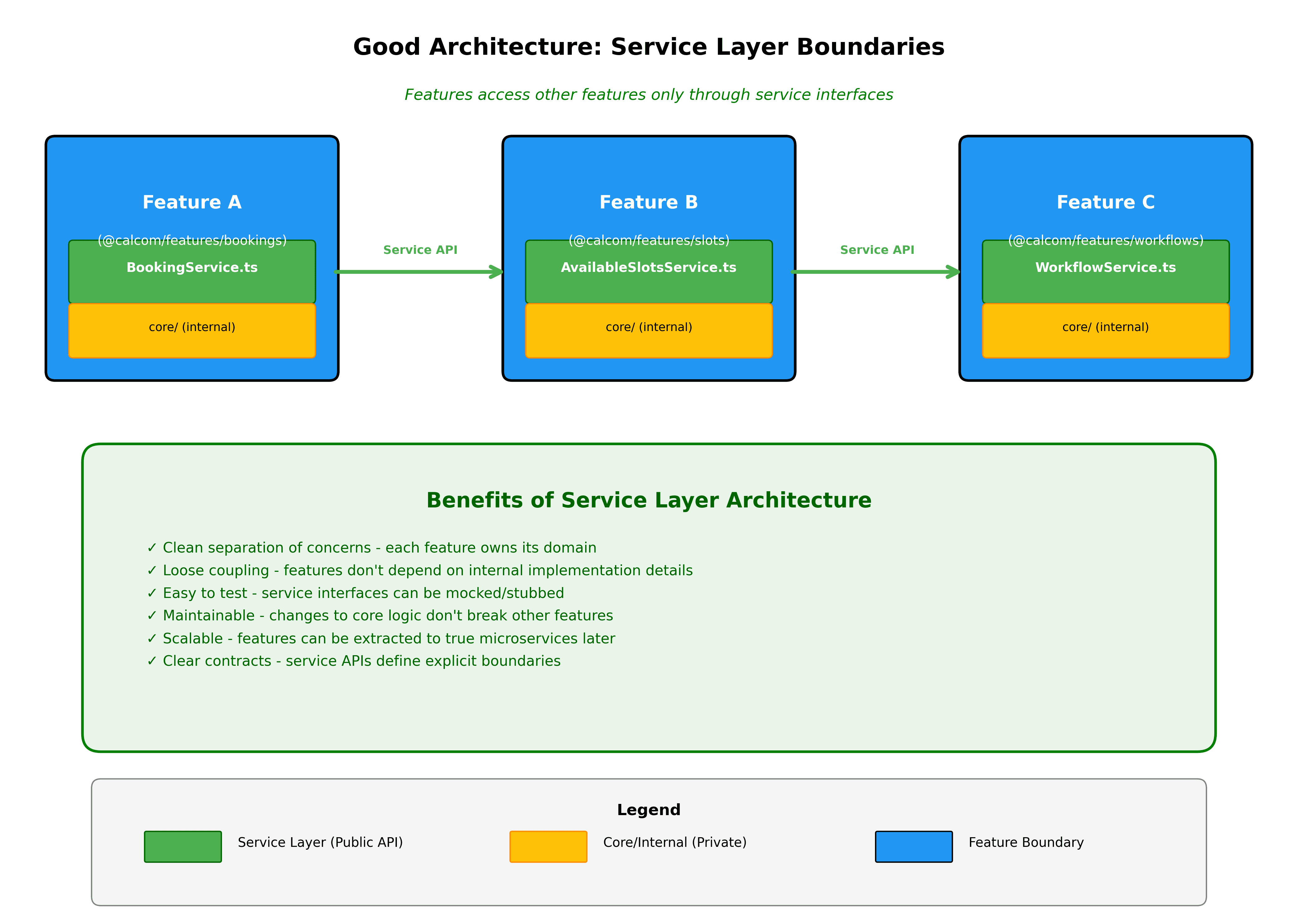
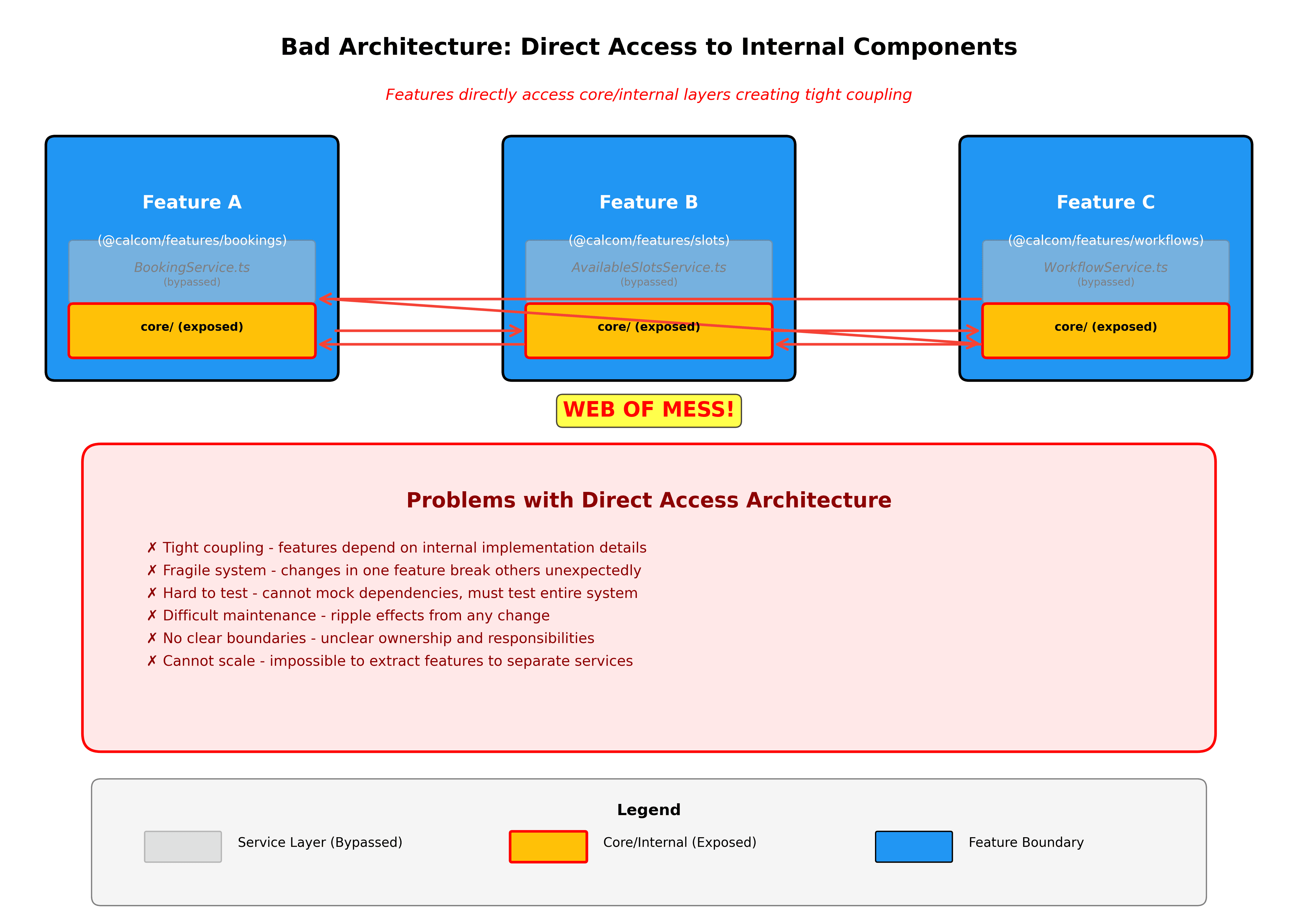
Novas funcionalidades começam como fatias verticais. Ao construir algo novo, crie uma nova pasta em packages/features com a fatia vertical completa. Isto torna claro o que está a construir e mantém tudo organizado desde o primeiro dia.
Benefícios
Facilidade de Descoberta
Procura lógica de reservas? Está tudo em
packages/features/bookings. Não há necessidade de procurar em controladores, serviços, repositórios e utilitários espalhados pela base de código.
Testes mais fáceis
Teste a funcionalidade completa como uma unidade. Tem todas as peças num só local, tornando os testes de integração naturais e descomplicados.
Dependências mais claras
Quando vê
import { getAvailability } from '@calcom/features/availability', sabe exatamente de que funcionalidade está a depender. Quando as dependências crescem e se tornam demasiado complexas, isso fica óbvio e pode ser resolvido.
Padrão Repositório e Injeção de Dependências
As escolhas tecnológicas não devem infiltrar-se na aplicação. O problema do Prisma ilustra isto perfeitamente. Atualmente, temos referências ao Prisma espalhadas por centenas de ficheiros. Isto cria um acoplamento maciço e torna as mudanças de tecnologia proibitivamente caras. Estamos a sentir a dor disso agora ao atualizar o Prisma para a v6.16. Algo que deveria ter sido apenas uma refatorização localizada atrás de repositórios protegidos tem sido uma busca sinuosa e quase interminável de problemas em várias aplicações.
O padrão daqui para a frente:
Todo o acesso à base de dados deve passar por classes Repositório. Já temos um bom avanço em relação a isto.
Os repositórios são o único código que sabe sobre o Prisma (ou qualquer outro ORM). Nenhuma lógica deve residir neles.
Os repositórios são injetados através de contentores de Injeção de Dependências (DI)
Se alguma vez mudarmos do Prisma para o Drizzle ou outro ORM, as únicas mudanças necessárias serão:
Implementações de repositório
Configuração do contentor de DI para novos repositórios
Mais nada na base de código se deve importar ou mudar
Isto não é teórico. É assim que construímos sistemas sustentáveis.
Objetos de Transferência de Dados (DTOs)
Os tipos da base de dados não devem chegar ao frontend. Este tornou-se um atalho popular na nossa pilha tecnológica, mas é um sintoma de mau código (code smell) que cria múltiplos problemas.
Acoplamento tecnológico (tipos de Prisma acabam em componentes React)
Riscos de segurança (fuga acidental de campos confidenciais)
Contratos frágeis entre servidor e cliente (isto é particularmente problemático à medida que construímos muito mais APIs)
Incapacidade de evoluir o esquema da base de dados de forma independente
Todas as conversões de DTOs através de Zod, mesmo para respostas de API, para garantir que todos os dados são validados antes de serem enviados para o utilizador. É melhor falhar do que devolver algo errado.
O padrão daqui para a frente:
Criar DTOs explícitos em cada limite arquitetónico.
Camada de dados → Camada de aplicação → API: Transformar modelos de base de dados em DTOs da camada de aplicação e, em seguida, transformar DTOs da aplicação em DTOs específicos da API
API → Camada de aplicação → Camada de dados: Transformar DTOs de API através da camada de aplicação em DTOs específicos de dados
Sim, isto exige mais código. Sim, vale a pena. Limites explícitos previnem a erosão arquitetónica que cria pesadelos de manutenção a longo prazo.
Padrões de Domain-Driven Design
Os seguintes padrões devem ser utilizados de forma correta e consistente:
Serviços de Aplicação
Orquestrar casos de utilização, coordenar entre serviços de domínio e repositórios
Serviços de Domínio
Conter lógica de negócio que não pertence naturalmente a uma única entidade
Repositórios
Abstrair o acesso a dados, isolar escolhas tecnológicas
Injeção de Dependências
Permitir acoplamento fraco, facilitar testes, isolar preocupações
Proxies de Caching
Envolver repositórios ou serviços para adicionar comportamento de cache de forma transparente
Não é a única forma de fazer cache, claro, mas um excelente ponto de partida
Decorators
Adicionar preocupações transversais (logs, métricas, etc.) sem poluir a lógica de domínio
Consistência da Base de Código
As nossas bases de código devem dar a sensação de terem sido escritas por uma única pessoa. Este nível de consistência exige uma adesão estrita aos padrões estabelecidos, regras de linting abrangentes que imponham padrões arquitetónicos, revisões de código que rejeitem violações de padrões e a ajuda de revisores de código de IA.
Mover Condicionais para o Ponto de Entrada da Aplicação
As instruções "if" pertencem ao ponto de entrada, não distribuídas pelos seus serviços. Este é um dos princípios arquitetónicos mais importantes para manter o código limpo, focado e livre de complexidade insustentável.
Eis como o código se degrada ao longo do tempo: Um serviço é escrito para um propósito claro e específico. A lógica é limpa e focada. Em seguida, surge um novo requisito de produto e alguém adiciona uma instrução "if". Alguns anos e mais alguns requisitos depois, esse serviço fica repleto de verificações condicionais para diferentes cenários. O serviço tornou-se:
Complicado e difícil de ler
Difícil de compreender e raciocinar sobre
Mais suscetível a bugs
Umas violação de responsabilidade única (tratando de demasiados casos diferentes)
Quase impossível de testar exaustivamente
O serviço ultrapassou os seus limites em termos de responsabilidades e lógica.
Uma Solução: Padrão Factory com Serviços Especializados
Utilize o padrão factory para tomar decisões no ponto de entrada e, em seguida, delegue para serviços especializados que tratam da sua lógica específica sem condicionais.
Exemplo da nossa base de código:
O BillingPortalServiceFactory determina se a faturação é para uma organização, equipa ou utilizador individual e, em seguida, devolve o serviço apropriado:
Cada serviço passa a tratar da sua lógica específica sem precisar de verificar "sou uma organização ou uma equipa?":
Porque é que Isto Importa
Os serviços mantêm-se focados
Cada serviço tem uma única responsabilidade e não precisa de conhecer outros contextos. O
OrganizationBillingPortalServicenão contém instruções "if" a verificarif (isTeam)ouif (isUser). Apenas sabe lidar com organizações.
As alterações são isoladas
Quando precisa de modificar a lógica de faturação da organização, apenas mexe em
OrganizationBillingPortalService. Não corre o risco de quebrar a faturação da equipa ou do utilizador. Não precisa de rastrear condicionais aninhados para perceber qual o caminho que o seu código segue.
Os testes são diretos
Teste cada serviço individualmente com os seus cenários específicos. Não há necessidade de testar cada combinação de condicionais em diferentes contextos.
Novos requisitos não poluem o código existente
ex. Quando precisar de adicionar faturação enterprise com regras diferentes, cria o
EnterpriseBillingPortalService. A factory ganha mais uma condicional, mas os serviços existentes permanecem intocados e focados.
Como alcançar
Empurre as condicionais para controladores, factories ou lógica de encaminhamento (routing). Deixe que estes pontos de entrada tomem decisões sobre qual serviço utilizar.
Mantenha os serviços puros e focados numa única responsabilidade. Se um serviço precisa de verificar "que tipo sou eu?", provavelmente precisa de múltiplos serviços.
Prefira polimorfismo em vez de condicionais
As interfaces definem o contrato. As implementações concretas fornecem os detalhes específicos.
Atenção à acumulação de instruções "if"
Durante a revisão de código, se vir um serviço a ganhar condicionais para cenários diferentes, isso é um sinal de que deve refatorá-lo em serviços especializados.
Design de API: Controladores Finos e Abstração HTTP
Os controladores são camadas finas que tratam apenas de questões HTTP.
Eles recebem pedidos, processam-nos e mapeiam os dados para DTOs que são passados para a lógica principal da aplicação. Daqui para a frente, nenhuma aplicação ou lógica principal deve ser vista em rotas de API ou manipuladores (handlers) tRPC.
Devemos desvincular a tecnologia HTTP da nossa aplicação.
A forma como transferimos dados entre o cliente e o servidor (seja REST, tRPC, etc.) não deve influenciar o funcionamento do núcleo da nossa aplicação. O HTTP é um mecanismo de entrega, não um direcionador arquitetónico.
Responsabilidades do controlador (e APENAS estas):
Receber e validar pedidos recebidos
Extrair dados de parâmetros do pedido, corpo, cabeçalhos
Transformar dados do pedido em DTOs
Chamar os serviços de aplicação apropriados com esses DTOs
Transformar as respostas do serviço de aplicação em DTOs de resposta
Devolver respostas HTTP com os códigos de estado corretos
Os controladores NÃO devem:
Conter lógica de negócio ou regras de domínio
Aceder diretamente a bases de dados ou serviços externos
Realizar transformações ou cálculos de dados complexos
Tomar decisões sobre o que a aplicação deve fazer
Saber sobre detalhes de implementação do domínio
Exemplo do padrão de controlador fino (thin controller):
Versões de API e Alterações Incompatíveis
Sem alterações incompatíveis (breaking changes). Isto é crítico. Uma vez que um endpoint de API é público, ele deve permanecer estável. Alterações incompatíveis destroem a confiança do programador e criam pesadelos de integração para os nossos utilizadores.
Estratégias para evitar alterações incompatíveis:
Adicionar sempre novos campos como opcionais
Usar controlo de versões de API quando for estritamente necessário alterar o comportamento existente
Descontinuar endpoints antigos de forma harmoniosa com caminhos de migração claros
Manter a compatibilidade com versões anteriores por pelo menos duas versões principais
Quando tiver de fazer alterações incompatíveis:
Crie uma nova versão de API utilizando o controlo de versões por data na API v2 (talvez analisemos também a versão nomeada que a Stripe introduziu recentemente)
Execute ambas as versões simultaneamente durante a transição (já fazemos isso na API v2)
Forneça ferramentas de migração automatizadas sempre que possível
Dê aos utilizadores tempo suficiente para migrar (mínimo de 6 meses para APIs públicas)
Documente exatamente o que mudou e porquê
Desempenho e Complexidade de Algoritmos
Nós construímos para grandes organizações e equipas. O que funciona bem com 10 utilizadores ou 50 registos pode colapsar sob o peso da escala empresarial. O desempenho não é algo que otimizamos mais tarde. É algo que construímos corretamente desde o início.
Pense na Escala Desde o Primeiro Dia
Ao construir funcionalidades, pergunte sempre: "Como se comporta isto com 1.000 utilizadores? 10.000 registos? 100.000 operações?" A diferença entre algoritmos O(n) e O(n²) pode ser impercetível em desenvolvimento, mas catastrófica em produção.
Padrões O(n²) comuns a evitar:
Iterações de matrizes (arrays) aninhadas (
.mapdentro de.map,.forEachdentro de.forEach)Métodos de matriz como
.some,.findou.filterdentro de ciclos ou callbacksVerificar cada elemento contra todos os outros elementos sem otimização
Filtros encadeados ou mapeamentos aninhados em listas grandes
Exemplo do mundo real: Para 100 slots disponíveis e 50 períodos ocupados, um algoritmo O(n²) executa 5.000 verificações. Dimensione isso para 500 slots e 200 períodos ocupados, e estará a fazer 100.000 operações. Trata-se de um aumento de 20x na carga de processamento para apenas um aumento de 5x nos dados.
Escolha as Estruturas de Dados e Algoritmos Corretos
A maioria dos problemas de desempenho resolve-se escolhendo as melhores estruturas de dados e algoritmos:
Ordenação + saída antecipada: Ordene os seus dados uma vez e depois saia dos ciclos (break) quando souber que os restantes elementos não corresponderão
Procura binária: Utilize a pesquisa binária para consultas em matrizes ordenadas em vez de varreduras lineares
Técnicas de dois ponteiros: Para fundir ou intersetar sequências ordenadas, percorra ambas com ponteiros em vez de ciclos aninhados
Mapas/conjuntos de hash (Hash maps/sets): Utilize objetos ou Sets para consultas O(1) em vez de
.findou.includesem matrizesÁrvores de intervalos: Para agendamento, disponibilidade e consultas de intervalos, utilize estruturas de árvores adequadas em vez de comparações por força bruta
Exemplo de transformação:
Verificações de Desempenho Automatizadas
Iremos implementar múltiplas camadas de defesa contra regressões de desempenho:
Regras de linting que sinalizam:
Funções com ciclos aninhados ou métodos de matriz aninhados
Chamadas múltiplas e aninhadas de
.some,.findou.filterRecursividade sem memoization (mecanismo de memorização)
Antipadrões conhecidos para o nosso domínio (agendamento, verificações de disponibilidade, etc.)
Testes de referência (benchmarks) de desempenho em CI que:
Executam algoritmos críticos em dados realistas e em larga escala
Comparam tempos de execução com a linha de base em cada PR
Bloqueiam junções (merges) que introduzam regressões de desempenho
Testam com dados à escala empresarial (milhares de utilizadores, dezenas de milhares de registos)
Monitorização em produção que:
Rastreia o tempo de execução de caminhos críticos
Alerta quando os algoritmos abrandam com o crescimento dos dados
Identifica regressões de desempenho antes que os utilizadores se apercebam
Fornece dados de desempenho reais para fundamentar otimizações
Desempenho é uma Funcionalidade
O desempenho não é opcional. Não é algo que deixamos "para mais tarde." Para clientes empresariais que agendam reuniões com grandes equipas, respostas lentas significam perda de produtividade e utilizadores frustrados (a nossa experiência com alguns clientes empresariais de maior dimensão serve de testemunho disto).
Cada engenheiro deve:
Analisar o perfil do código (profile) antes de o otimizar, mas pensar na complexidade desde o início
Testar com dados realistas e em larga escala (e não apenas com 5 registos de teste). Já temos scripts de geração (seed) de dados criados. Provavelmente precisamos de os expandir.
Escolher algoritmos e estruturas de dados eficazes à partida
Prestar atenção a iterações aninhadas na revisão de código
Questionar qualquer algoritmo que escale com o produto de duas variáveis
A Realidade NP-Completa (NP-Hard) do Agendamento
Os problemas de agendamento são fundamentalmente complexos (NP-hard). Isto significa que à medida que o número de restrições, participantes ou slots de tempo cresce, a complexidade computacional pode explodir exponencialmente. A maioria dos algoritmos de agendamento ideais tem uma complexidade de tempo exponencial no pior caso, tornando a escolha do algoritmo absolutamente crítica.
Implicações no mundo real:
Encontrar o horário ideal para reuniões para 10 pessoas em 3 fusos horários com restrições de disponibilidade individuais é computacionalmente caro
Adicionar deteção de conflitos, buffers e uma imensidão de outras opções amplia o problema
Piores escolhas de algoritmos que funcionam bem para equipas pequenas tornam-se completamente inutilizáveis para grandes organizações
O que demora milissegundos para 5 utilizadores pode demorar muitos segundos para organizações
Estratégias para gerir a complexidade NP-Hard:
Utilizar algoritmos de aproximação que encontram soluções "suficientemente boas" rapidamente em vez de soluções perfeitas de forma lenta
Implementar caching agressivo de agendas e disponibilidades já calculadas
Pré-calcular cenários comuns durante as horas de menor atividade
Dividir problemas de agendamento grandes em partes menores e mais fáceis de gerir
Definir limites de tempo limite (timeout) razoáveis e recorrer a algoritmos mais simples quando necessário
É por isso que o desempenho não é apenas um aspeto agradável num software de agendamento. É a base que determina se o seu sistema consegue escalar para as necessidades empresariais ou se colapsa sob padrões reais de utilização.
Requisitos de Cobertura de Código
Rastreio de cobertura global
Acompanhamos a cobertura geral da base de código como uma métrica chave que melhora com o tempo. Isso dá-nos visibilidade sobre o nível de maturação dos nossos testes e ajuda a identificar áreas que necessitam de atenção. A percentagem de cobertura global é mostrada em destaque nos nossos dashboards.
Cobertura superior a 80% para código novo
Cada PR deve ter uma cobertura de testes próxima ou superior a 80% para o código que introduz ou modifica. Isto é controlado automaticamente no nosso pipeline de CI. Se adicionar 50 linhas de código novo, essas 50 linhas têm de ser cobertas por testes. Se modificar uma função existente, as suas alterações têm de ser testadas. Trata-se da cobertura global de testes. A cobertura de testes unitários precisa de estar perto de 100%, especialmente com a possibilidade de recorrer a IA para ajudar a gerá-los.
Abordando o argumento de que "a cobertura não conta toda a história": Sim, sabemos que a cobertura de código não garante testes perfeitos. Sabemos que é possível escrever testes sem sentido que passam por todas as linhas mas não testam nada de útil. Sabemos que a cobertura é apenas uma métrica entre muitas. No entanto, é sem dúvida melhor apontar para uma percentagem elevada do que não ter qualquer ideia de onde nos encontramos.
Medir o Sucesso
"Velocidade" (termo emprestado do Scrum mesmo sem utilizarmos Scrum)
Crescimento contínuo nas estatísticas mensais (funcionalidades, melhorias, refatorizações)
Qualidade
Reduzir o esforço de PR dedicado a correções dos atuais 35% para 20% ou menos até ao final de 2026 (calculado com base nas alterações e adições/remoções de ficheiros)
Saúde arquitetónica
Métricas de adesão a padrões, acoplamento de tecnologia, violações de limites
Eficiência de revisão
PRs mais pequenos, revisões mais rápidas, menos rondas de feedback
Disponibilidade (uptime) de aplicação e API
Quão perto estamos de 99,99%?

Comece com o Cal.com gratuitamente hoje!
Experimente uma programação e produtividade sem interrupções, sem taxas ocultas. Registe-se em segundos e comece a simplificar a sua programação hoje, sem necessidade de cartão de crédito!



