" height="18.016311920580208px" id="GKXyVanMq" stroke-dasharray="0" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-width="0.5" stroke="rgb(0, 0, 0)" transform="translate(3 3)" width="18px"/></svg>)
"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient><linearGradient id="CBS1bzkxF-2031533640-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgb(255, 255, 255)"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient><linearGradient id="Jd7AK81w9-2031533640-linear-gradient" x1="0.49751243781094523" x2="0.5024875621890548" y1="0" y2="1"><stop offset="0" stop-color="rgb(255, 255, 255)"/><stop offset="1" stop-color="rgb(227, 224, 244)"/></linearGradient></defs><g d="M 0 16 L 0 0 L 16 0 L 16 16 Z M 9.167 5.167 C 9.167 4.891 8.943 4.667 8.667 4.667 C 8.391 4.667 8.167 4.891 8.167 5.167 C 8.167 6.784 7.809 7.834 7.155 8.488 C 6.501 9.143 5.451 9.5 3.833 9.5 C 3.557 9.5 3.333 9.724 3.333 10 C 3.333 10.276 3.557 10.5 3.833 10.5 C 5.451 10.5 6.501 10.857 7.155 11.512 C 7.809 12.166 8.167 13.216 8.167 14.833 C 8.167 15.109 8.391 15.333 8.667 15.333 C 8.943 15.333 9.167 15.109 9.167 14.833 C 9.167 13.216 9.524 12.166 10.178 11.512 C 10.832 10.857 11.883 10.5 13.5 10.5 C 13.776 10.5 14 10.276 14 10 C 14 9.724 13.776 9.5 13.5 9.5 C 11.883 9.5 10.832 9.143 10.178 8.488 C 9.524 7.834 9.167 6.784 9.167 5.167 Z M 4 3.667 C 4 3.483 3.851 3.333 3.667 3.333 C 3.483 3.333 3.333 3.483 3.333 3.667 C 3.333 4.32 3.189 4.715 2.952 4.952 C 2.715 5.189 2.32 5.333 1.667 5.333 C 1.483 5.333 1.333 5.483 1.333 5.667 C 1.333 5.851 1.483 6 1.667 6 C 2.32 6 2.715 6.145 2.952 6.382 C 3.189 6.618 3.333 7.013 3.333 7.667 C 3.333 7.851 3.483 8 3.667 8 C 3.851 8 4 7.851 4 7.667 C 4 7.013 4.145 6.618 4.382 6.382 C 4.618 6.145 5.013 6 5.667 6 C 5.851 6 6 5.851 6 5.667 C 6 5.483 5.851 5.333 5.667 5.333 C 5.013 5.333 4.618 5.189 4.382 4.952 C 4.145 4.715 4 4.32 4 3.667 Z M 7.333 1 C 7.333 0.816 7.184 0.667 7 0.667 C 6.816 0.667 6.667 0.816 6.667 1 C 6.667 1.422 6.573 1.65 6.445 1.778 C 6.317 1.906 6.089 2 5.667 2 C 5.483 2 5.333 2.149 5.333 2.333 C 5.333 2.517 5.483 2.667 5.667 2.667 C 6.089 2.667 6.317 2.761 6.445 2.889 C 6.573 3.016 6.667 3.244 6.667 3.667 C 6.667 3.851 6.816 4 7 4 C 7.184 4 7.333 3.851 7.333 3.667 C 7.333 3.244 7.427 3.016 7.555 2.889 C 7.683 2.761 7.911 2.667 8.333 2.667 C 8.517 2.667 8.667 2.517 8.667 2.333 C 8.667 2.149 8.517 2 8.333 2 C 7.911 2 7.683 1.906 7.555 1.778 C 7.427 1.65 7.333 1.422 7.333 1 Z" fill="transparent" height="16px" id="aoZYv33vR" width="16px"><path d="M 0 16 L 0 0 L 16 0 L 16 16 Z" fill="transparent" height="16px" id="Z2uGmhW9f" width="16px"/><g d="M 7.833 4.5 C 7.833 4.224 7.609 4 7.333 4 C 7.057 4 6.833 4.224 6.833 4.5 C 6.833 6.117 6.476 7.168 5.822 7.822 C 5.168 8.476 4.117 8.833 2.5 8.833 C 2.224 8.833 2 9.057 2 9.333 C 2 9.61 2.224 9.833 2.5 9.833 C 4.117 9.833 5.168 10.191 5.822 10.845 C 6.476 11.499 6.833 12.549 6.833 14.167 C 6.833 14.443 7.057 14.667 7.333 14.667 C 7.609 14.667 7.833 14.443 7.833 14.167 C 7.833 12.549 8.191 11.499 8.845 10.845 C 9.499 10.191 10.549 9.833 12.167 9.833 C 12.443 9.833 12.667 9.61 12.667 9.333 C 12.667 9.057 12.443 8.833 12.167 8.833 C 10.549 8.833 9.499 8.476 8.845 7.822 C 8.191 7.168 7.833 6.117 7.833 4.5 Z M 2.667 3 C 2.667 2.816 2.517 2.667 2.333 2.667 C 2.149 2.667 2 2.816 2 3 C 2 3.654 1.855 4.048 1.618 4.285 C 1.382 4.522 0.987 4.667 0.333 4.667 C 0.149 4.667 0 4.816 0 5 C 0 5.184 0.149 5.333 0.333 5.333 C 0.987 5.333 1.382 5.478 1.618 5.715 C 1.855 5.952 2 6.346 2 7 C 2 7.184 2.149 7.333 2.333 7.333 C 2.517 7.333 2.667 7.184 2.667 7 C 2.667 6.346 2.811 5.952 3.048 5.715 C 3.285 5.478 3.68 5.333 4.333 5.333 C 4.517 5.333 4.667 5.184 4.667 5 C 4.667 4.816 4.517 4.667 4.333 4.667 C 3.68 4.667 3.285 4.522 3.048 4.285 C 2.811 4.048 2.667 3.654 2.667 3 Z M 6 0.333 C 6 0.149 5.851 0 5.667 0 C 5.483 0 5.333 0.149 5.333 0.333 C 5.333 0.756 5.239 0.984 5.112 1.112 C 4.984 1.239 4.756 1.333 4.333 1.333 C 4.149 1.333 4 1.483 4 1.667 C 4 1.851 4.149 2 4.333 2 C 4.756 2 4.984 2.094 5.112 2.222 C 5.239 2.35 5.333 2.578 5.333 3 C 5.333 3.184 5.483 3.333 5.667 3.333 C 5.851 3.333 6 3.184 6 3 C 6 2.578 6.094 2.35 6.222 2.222 C 6.35 2.094 6.578 2 7 2 C 7.184 2 7.333 1.851 7.333 1.667 C 7.333 1.483 7.184 1.333 7 1.333 C 6.578 1.333 6.35 1.239 6.222 1.112 C 6.094 0.984 6 0.756 6 0.333 Z" fill="transparent" height="14.66671286102295px" id="ae6ccdFme" transform="translate(1.333 0.667)" width="12.66663px"><path d="M 5.833 0.5 C 5.833 0.224 5.609 0 5.333 0 C 5.057 0 4.833 0.224 4.833 0.5 C 4.833 2.117 4.476 3.168 3.822 3.822 C 3.168 4.476 2.117 4.833 0.5 4.833 C 0.224 4.833 0 5.057 0 5.333 C 0 5.61 0.224 5.833 0.5 5.833 C 2.117 5.833 3.168 6.191 3.822 6.845 C 4.476 7.499 4.833 8.549 4.833 10.167 C 4.833 10.443 5.057 10.667 5.333 10.667 C 5.609 10.667 5.833 10.443 5.833 10.167 C 5.833 8.549 6.191 7.499 6.845 6.845 C 7.499 6.191 8.549 5.833 10.167 5.833 C 10.443 5.833 10.667 5.61 10.667 5.333 C 10.667 5.057 10.443 4.833 10.167 4.833 C 8.549 4.833 7.499 4.476 6.845 3.822 C 6.191 3.168 5.833 2.117 5.833 0.5 Z" fill="url(%23t2lXByE48-2031533640-linear-gradient)" height="10.66671px" id="t2lXByE48" transform="translate(2 4)" width="10.66663px"/><path d="M 2.667 0.333 C 2.667 0.149 2.517 0 2.333 0 C 2.149 0 2 0.149 2 0.333 C 2 0.987 1.855 1.382 1.618 1.618 C 1.382 1.855 0.987 2 0.333 2 C 0.149 2 0 2.149 0 2.333 C 0 2.517 0.149 2.667 0.333 2.667 C 0.987 2.667 1.382 2.811 1.618 3.048 C 1.855 3.285 2 3.68 2 4.333 C 2 4.517 2.149 4.667 2.333 4.667 C 2.517 4.667 2.667 4.517 2.667 4.333 C 2.667 3.68 2.811 3.285 3.048 3.048 C 3.285 2.811 3.68 2.667 4.333 2.667 C 4.517 2.667 4.667 2.517 4.667 2.333 C 4.667 2.149 4.517 2 4.333 2 C 3.68 2 3.285 1.855 3.048 1.618 C 2.811 1.382 2.667 0.987 2.667 0.333 Z" fill="url(%23CBS1bzkxF-2031533640-linear-gradient)" height="4.66667px" id="CBS1bzkxF" transform="translate(0 2.667)" width="4.66667px"/><path d="M 2 0.333 C 2 0.149 1.851 0 1.667 0 C 1.483 0 1.333 0.149 1.333 0.333 C 1.333 0.756 1.239 0.984 1.112 1.112 C 0.984 1.239 0.756 1.333 0.333 1.333 C 0.149 1.333 0 1.483 0 1.667 C 0 1.851 0.149 2 0.333 2 C 0.756 2 0.984 2.094 1.112 2.222 C 1.239 2.35 1.333 2.578 1.333 3 C 1.333 3.184 1.483 3.333 1.667 3.333 C 1.851 3.333 2 3.184 2 3 C 2 2.578 2.094 2.35 2.222 2.222 C 2.35 2.094 2.578 2 3 2 C 3.184 2 3.333 1.851 3.333 1.667 C 3.333 1.483 3.184 1.333 3 1.333 C 2.578 1.333 2.35 1.239 2.222 1.112 C 2.094 0.984 2 0.756 2 0.333 Z" fill="url(%23Jd7AK81w9-2031533640-linear-gradient)" height="3.333333px" id="Jd7AK81w9" transform="translate(4 0)" width="3.3333399999999997px"/></g></g></svg>)
" height="24px" id="WCm44spAV" width="24px"/><path d="M 3.892 7.742 C 1.674 7.742 0 6.014 0 3.882 C 0 1.738 1.589 0 3.892 0 C 5.107 0 5.951 0.374 6.623 1.173 L 5.566 2.09 C 5.118 1.621 4.564 1.386 3.892 1.386 C 2.452 1.386 1.547 2.517 1.547 3.882 C 1.547 5.246 2.452 6.356 3.924 6.356 C 4.649 6.356 5.193 6.111 5.63 5.63 L 6.718 6.558 C 6.153 7.24 5.193 7.742 3.892 7.742 Z" fill="rgb(255, 255, 255)" height="7.741500000000002px" id="XEPpGD7l5" transform="translate(4 8.25)" width="6.717999999999989px"/><path d="M 2.74 7.922 C 1.215 7.922 0 6.632 0 5.032 C 0 3.433 1.215 2.122 2.74 2.122 C 3.7 2.122 4.201 2.516 4.5 3.113 L 4.5 2.239 L 5.928 2.239 L 5.928 7.784 L 4.531 7.784 L 4.531 6.877 C 4.233 7.507 3.731 7.922 2.74 7.922 Z M 1.439 5.023 C 1.439 5.865 2.057 6.622 2.975 6.622 C 3.924 6.622 4.531 5.897 4.531 5.033 C 4.531 4.169 3.924 3.423 2.975 3.423 C 2.057 3.423 1.439 4.159 1.439 5.022 Z M 6.784 7.784 L 6.784 0 L 8.224 0 L 8.224 7.784 L 6.784 7.784 Z" fill="rgb(255, 255, 255)" height="7.9224997406005855px" id="lGDJupIUR" transform="translate(10.5 8)" width="8.223500194549558px"/></g></svg>)
" width="18px"><path d="M 2 8 C 0.895 8 0 7.105 0 6 L 0 2 C 0 0.895 0.895 0 2 0 L 6 0 C 7.105 0 8 0.895 8 2 L 8 6 C 8 7.105 7.105 8 6 8 Z" fill="transparent" height="8px" id="ZrCrI93dV" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" width="8px"/><path d="M 0 0 L 0 4 C 0 5.105 0.895 6 2 6 L 6 6" fill="transparent" height="6px" id="emltWYAiE" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" transform="translate(4 8)" width="6px"/><path d="M 2 8 C 0.895 8 0 7.105 0 6 L 0 2 C 0 0.895 0.895 0 2 0 L 6 0 C 7.105 0 8 0.895 8 2 L 8 6 C 8 7.105 7.105 8 6 8 Z" fill="transparent" height="8px" id="WpBecYDfi" stroke-dasharray="" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" stroke="rgb(0, 0, 0)" transform="translate(10 10)" width="8px"/></g></svg>)

Encontrar e corrigir gargalos de desempenho O(n²): Lições das otimizações de algoritmos da Cal.com
Uma análise profunda sobre como detectámos, analisámos e otimizámos algoritmos com mau desempenho em uma base de código de produção real.

Introdução
Os estrangulamentos de desempenho em sistemas de agendamento podem significar a diferença entre uma experiência de usuário responsiva e usuários abandonando sua plataforma devido à frustração. No Cal.com, recentemente descobrimos e otimizamos vários algoritmos críticos O(n²) que estavam causando lentidão à medida que nossa base de usuários e volumes de dados aumentavam.
Neste artigo, compartilharei quatro otimizações reais de algoritmos do código do Cal.com. Você aprenderá como detectamos a complexidade O(n²), quais estratégias de otimização funcionaram melhor e como implementamos verificações automatizadas para prevenir regressões futuras.

O problema: Como um código inocente se torna O(n²)
À medida que as plataformas de agendamento crescem, é surpreendentemente fácil para loops aninhados parecerem inocentes, mas se tornarem assassinos silenciosos de desempenho. Considere este exemplo real do nosso código:
Para 100 intervalos e 50 períodos ocupados, isso são 5.000 verificações de sobreposição. Em escalas maiores—500 intervalos e 200 períodos ocupados—isso explode para 100.000 operações. Isso representa um aumento de vinte vezes na carga computacional para apenas um aumento de cinco vezes nos dados.
Estudo de caso 1: Otimização de verificação de conflito de intervalo
O problema original
A função checkForConflicts usava iteração aninhada para verificar se intervalos de reserva conflitavam com períodos ocupados. Isso rapidamente se tornou um problema de desempenho com grandes cronogramas.
Implementação original: Loops aninhados O(n²)
Implementação otimizada: O(n log n) com ordenação e término antecipado
O que mudou:
Ordenamos os tempos ocupados pelos seus horários de início, permitindo pular períodos não sobrepostos e sair antecipadamente quando não há conflitos possíveis. O resultado foi uma queda dramática no número de comparações desnecessárias.
Impacto:
A complexidade caiu de O(intervalos disponíveis × períodos ocupados) para O(n log n), e a maioria das verificações foi completamente ignorada em casos típicos.
Estudo de caso 2: Interseção de intervalo de datas usando a técnica de dois ponteiros
O problema original
A função intersect anteriormente usava loops aninhados para encontrar sobreposições na disponibilidade de vários usuários.
Implementação original: Mapeamento aninhado O(n²)
Implementação otimizada: O(n log n) com travessia de dois ponteiros
O que mudou:
Ao ordenar e usar dois ponteiros para percorrer os intervalos, eliminamos a necessidade de iteração aninhada. Isso reduziu a complexidade de quadrática para quase linear na maioria das entradas práticas.
Estudo de caso 3: Árvore de intervalos para filtragem de intervalos redundantes
O problema original
A função filterRedundantDateRanges verificava cada intervalo em relação a outro para ver se um continha o outro. Para grandes cronogramas, isso se tornava dolorosamente lento.
Implementação original: Verificação de contenção O(n²)
Implementação otimizada: O(n log n) com uma árvore de intervalos
O que mudou:
Em vez de comparação por força bruta, usamos uma estrutura de árvore de intervalos para permitir consultas rápidas de contenção O(log n). Esta é uma abordagem clássica na geometria computacional que funciona maravilhosamente para aplicativos de agendamento.
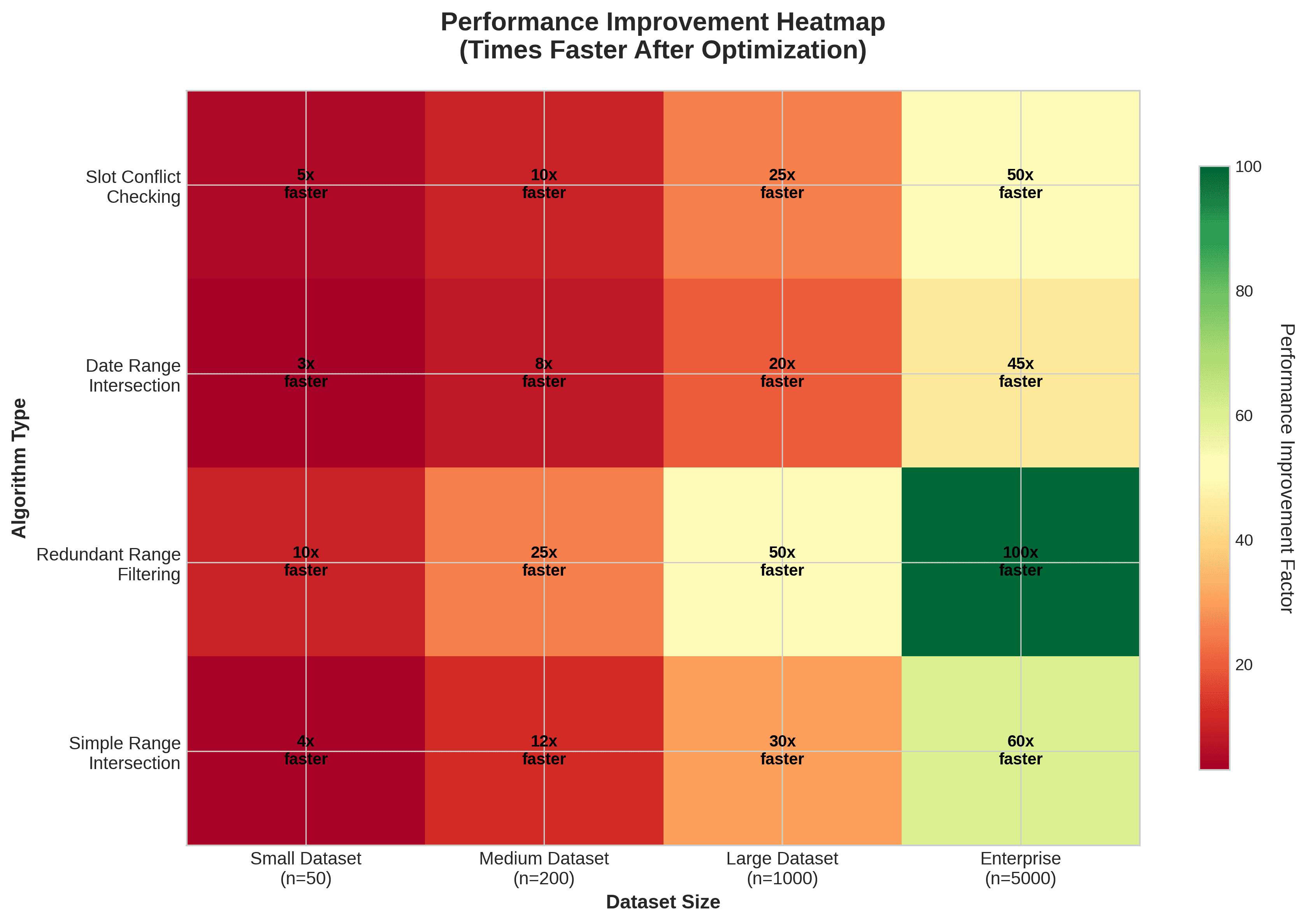
Resultados de desempenho: Antes e depois
Nossos benchmarks mostraram melhorias significativas:
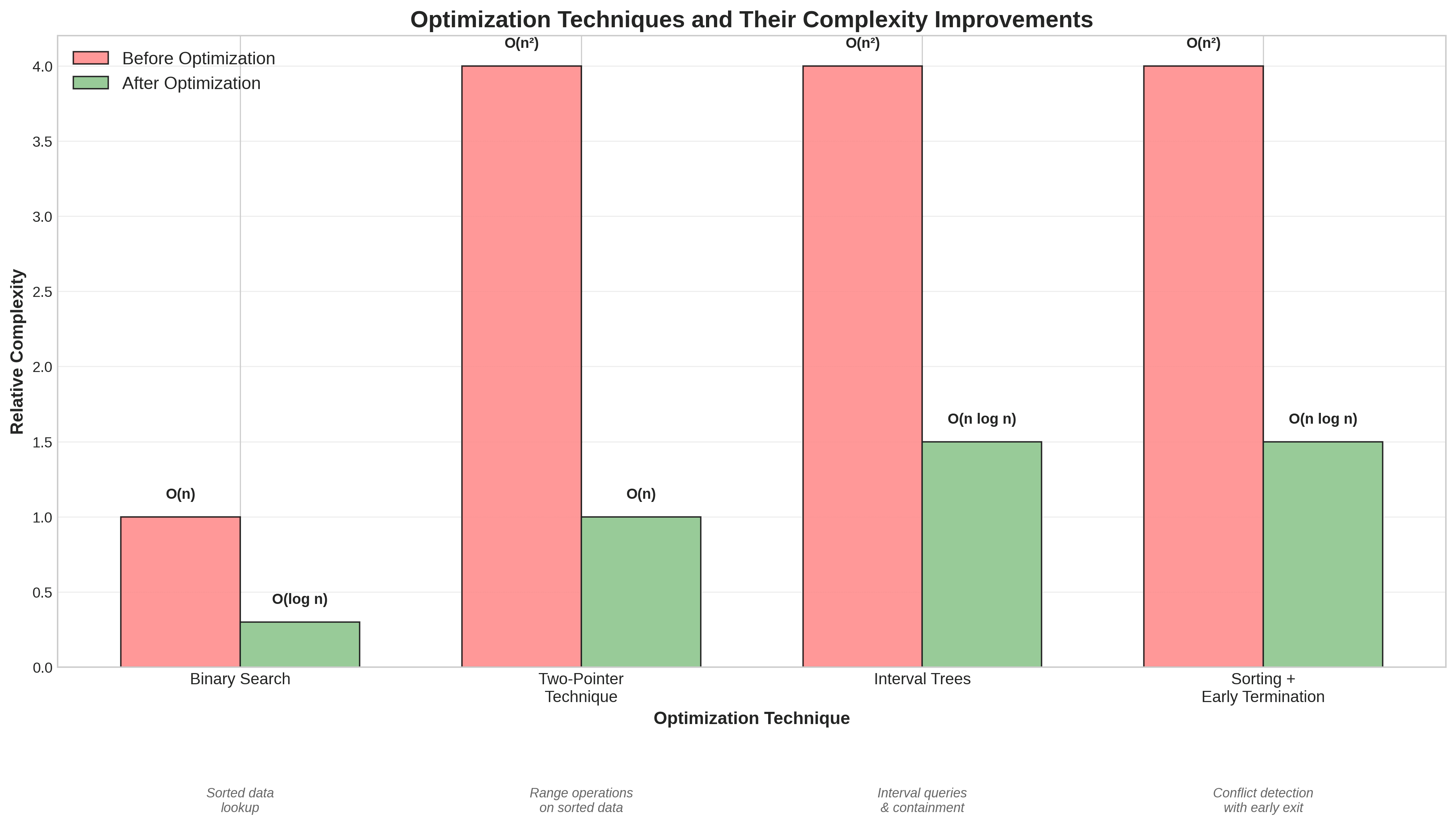
Verificação de conflito de intervalo: Reduzido de O(n²) para O(n log n), tornando 100 intervalos e 50 períodos ocupados cerca de dez vezes mais rápidos.
Interseção de intervalo de datas: Caiu de O(n²) para O(n log n), permitindo que centenas de intervalos de datas fossem processados em milissegundos.
Filtragem de intervalos redundantes: Reduzido de O(n²) para O(n log n), com até cinquenta vezes mais velocidade para milhares de intervalos de datas.
Interseção de intervalo geral: Através de muitos padrões, vimos melhorias de vinte e cinco vezes ou mais.
Técnicas fáceis para detectar algoritmos O(n²)
Reconhecer padrões problemáticos
Fique atento a:
Iterações aninhadas de arrays, especialmente
.map,.forEach,.filterdentro de outra.Métodos de array como
.some,.findou.filterem loops ou callbacks de array.Filtros encadeados ou mapeamento aninhado em listas grandes.
Teste de escalabilidade explicitamente
Escreva testes de desempenho que executem sua função em dados de tamanho crescente e registre tempos de execução. Se o tempo crescer quadraticamente com o tamanho dos dados, você tem um problema O(n²).
Automatize a análise estática
Adicione regras de lint ou análise estática que:
Sinalizem funções com loops aninhados ou métodos de arrays aninhados.
Identifiquem recursão sem memoização.
Detectem funções com múltiplas chamadas aninhadas de
.some,.findou.filter.
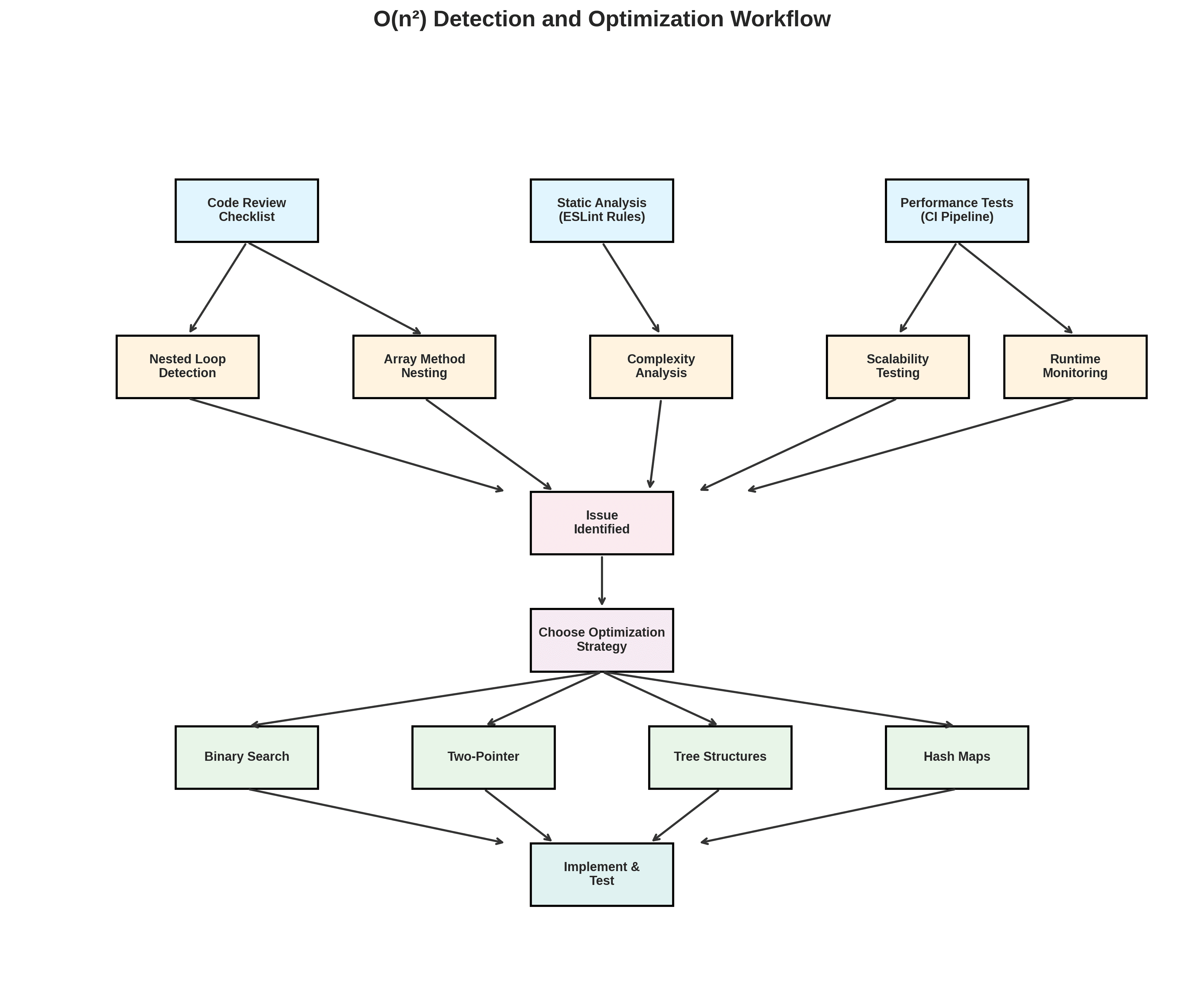
Estratégias comprovadas para substituir código O(n²)
Use busca binária para consultas em arrays ordenados.
Use técnicas de dois ponteiros para mesclar ou intersectar sequências ordenadas.
Use estruturas de dados baseadas em árvore para consultas de intervalos ou dados hierárquicos.
Automatizando verificações de desempenho
Adicione benchmarks de desempenho ao seu pipeline de IC que executem algoritmos críticos em dados realistas. Compare tempos de execução em todas as solicitações de pull e bloqueie mesclagens que causem regressão. Adicione regras de lint personalizadas para evitar que padrões óbvios O(n²) cheguem à produção. Implemente monitoramento em tempo de execução para caminhos críticos para detectar novas regressões antes que os usuários percebam.
Principais lições
A prevenção é sempre melhor que a cura. Verificações automatizadas capturarão algoritmos O(n²) antes que eles causem problemas.
Sempre faça perfis antes de otimizar. Use testes para encontrar gargalos reais.
Escolha as estruturas de dados certas para suas necessidades. Arrays ordenados, abordagens de dois ponteiros e árvores são inestimáveis.
Teste com dados realistas e em grande escala. Testes pequenos podem esconder grandes problemas.
Monitore em produção. Alertas automatizados podem capturar regressões cedo.

Conclusão
As otimizações que fizemos no Cal.com mostram que ganhos significativos de desempenho são possíveis aplicando-se técnicas algorítmicas comprovadas. Combine revisão de código, estruturas de dados inteligentes e monitoramento automatizado para manter seu aplicativo rápido à medida que cresce.
O desempenho deve ser incorporado em todas as etapas do desenvolvimento, desde revisões de código que sinalizam padrões suspeitos até pipelines de IC que executam testes de escalabilidade e monitoramento de tempo de execução que detectam regressões.
O algoritmo rápido de hoje pode facilmente se tornar o estrangulamento de amanhã à medida que seus dados crescem. Mantenha-se vigilante, teste em escala e esteja sempre pronto para otimizar.

Comece com o Cal.com gratuitamente hoje!
Experimente uma programação e produtividade sem interrupções, sem taxas ocultas. Registe-se em segundos e comece a simplificar a sua programação hoje, sem necessidade de cartão de crédito!



